LangChain 框架实战:
构建完整 AI 应用链
如果你曾经尝试直接调用 OpenAI 或 Claude 的 API 构建 AI 应用,一定体会过那种"拼积木"的痛苦——提示词模板要自己管理、对话历史要自己维护、工具调用的格式要自己处理、RAG 管道要从头搭建。LangChain 的出现正是为了解决这些问题。
本教程将带你从零开始,用 LangChain 0.3 构建一个功能完整的 AI 助手:支持链式调用、工具使用、对话记忆和文档检索(RAG)。所有代码均经过实际验证,可直接运行。
一、LangChain 核心架构解读
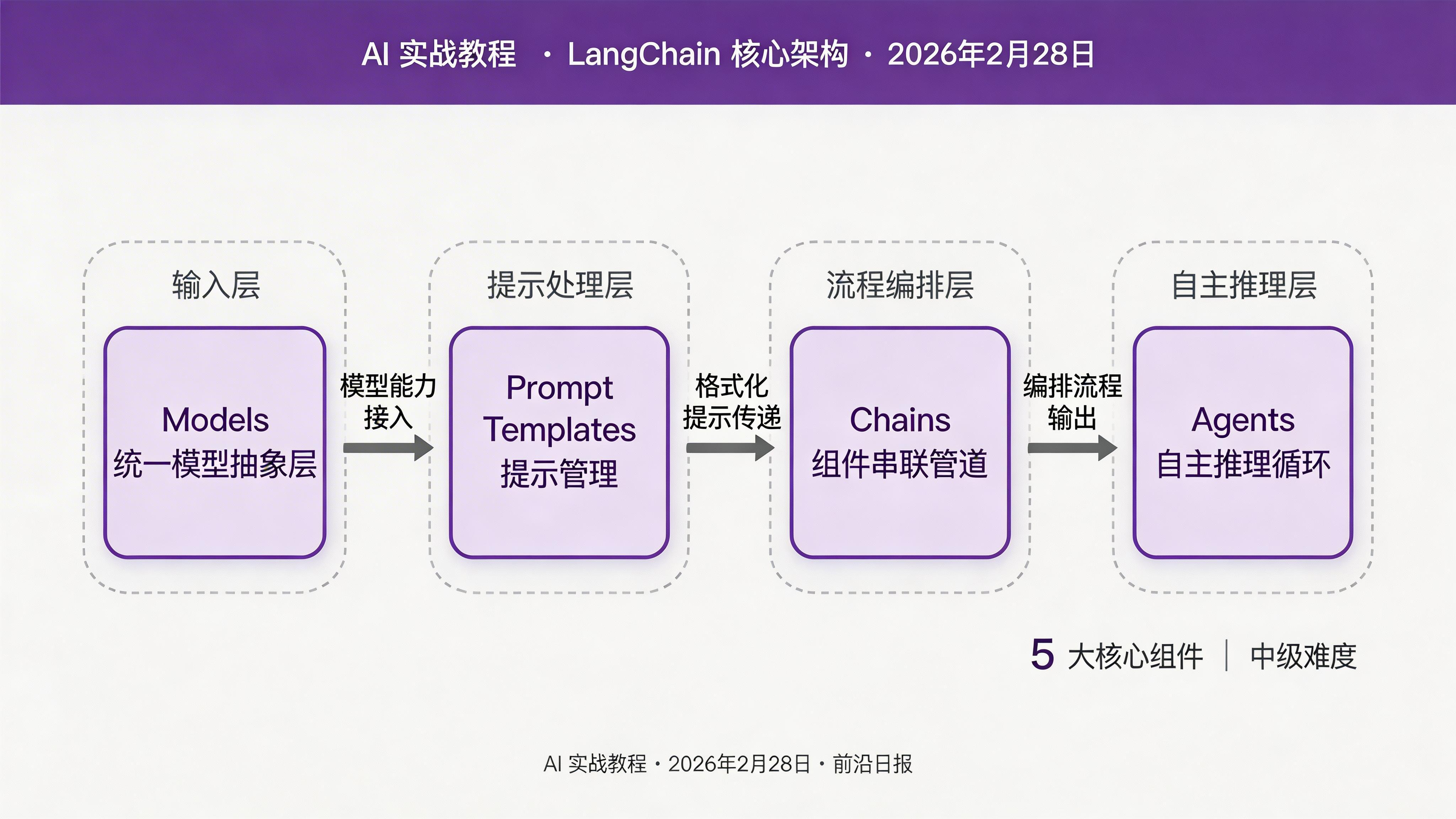
理解 LangChain 的关键,是掌握它的五大核心组件。它们相互独立,又可以灵活组合:
- 模型(Models):对 LLM 的统一抽象,支持 OpenAI、Anthropic、本地模型等,切换模型只需改一行代码。
- 提示模板(Prompt Templates):可复用、可参数化的提示词管理系统,支持 Few-shot、Chat 等多种格式。
- 链(Chains):将多个组件按顺序串联的"管道"。LangChain 0.3 推荐使用 LCEL(LangChain Expression Language)语法,用
|运算符组合。 - 记忆(Memory):为链和代理提供对话历史,让 LLM 具备多轮对话能力。
- 代理(Agents):让 LLM 自主决策调用哪个工具、什么时候结束的推理循环,是构建 AI 应用的核心模式之一。
Runnable 接口,可以像函数一样被链接、并行、嵌套。
二、环境搭建与依赖安装
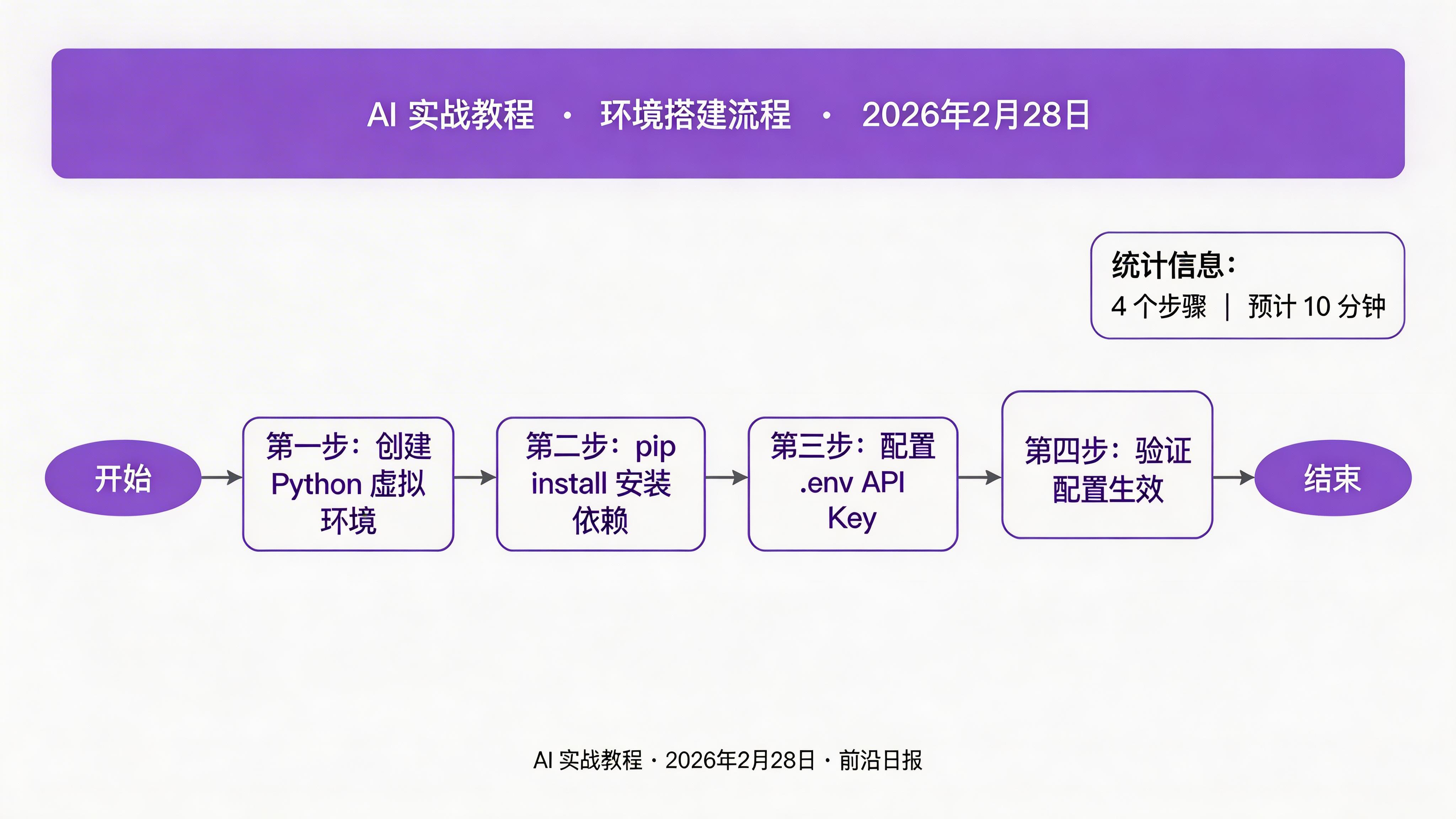
创建虚拟环境并安装依赖
推荐使用 Python 3.10+ 和独立的虚拟环境,避免依赖冲突。
bash# 创建虚拟环境
python -m venv langchain-env
source langchain-env/bin/activate # Windows: langchain-env\Scripts\activate
# 安装核心包
pip install langchain langchain-openai langchain-community
pip install langgraph # 用于构建有状态的代理
pip install faiss-cpu # 向量数据库(RAG 章节使用)
pip install python-dotenv # 管理环境变量配置 API Key
在项目根目录创建 .env 文件,填入你的 API Key。
OPENAI_API_KEY=sk-your-key-here
# 如果使用 Claude
ANTHROPIC_API_KEY=sk-ant-your-key-here
# 可选:LangSmith 可观测性平台
LANGCHAIN_TRACING_V2=true
LANGCHAIN_API_KEY=your-langsmith-keyfrom dotenv import load_dotenv
import os
load_dotenv()
# 验证配置是否生效
print("API Key loaded:", bool(os.getenv("OPENAI_API_KEY"))).env 文件提交到 Git 仓库。在 .gitignore 中添加 .env。
三、第一条链:LCEL 链式调用
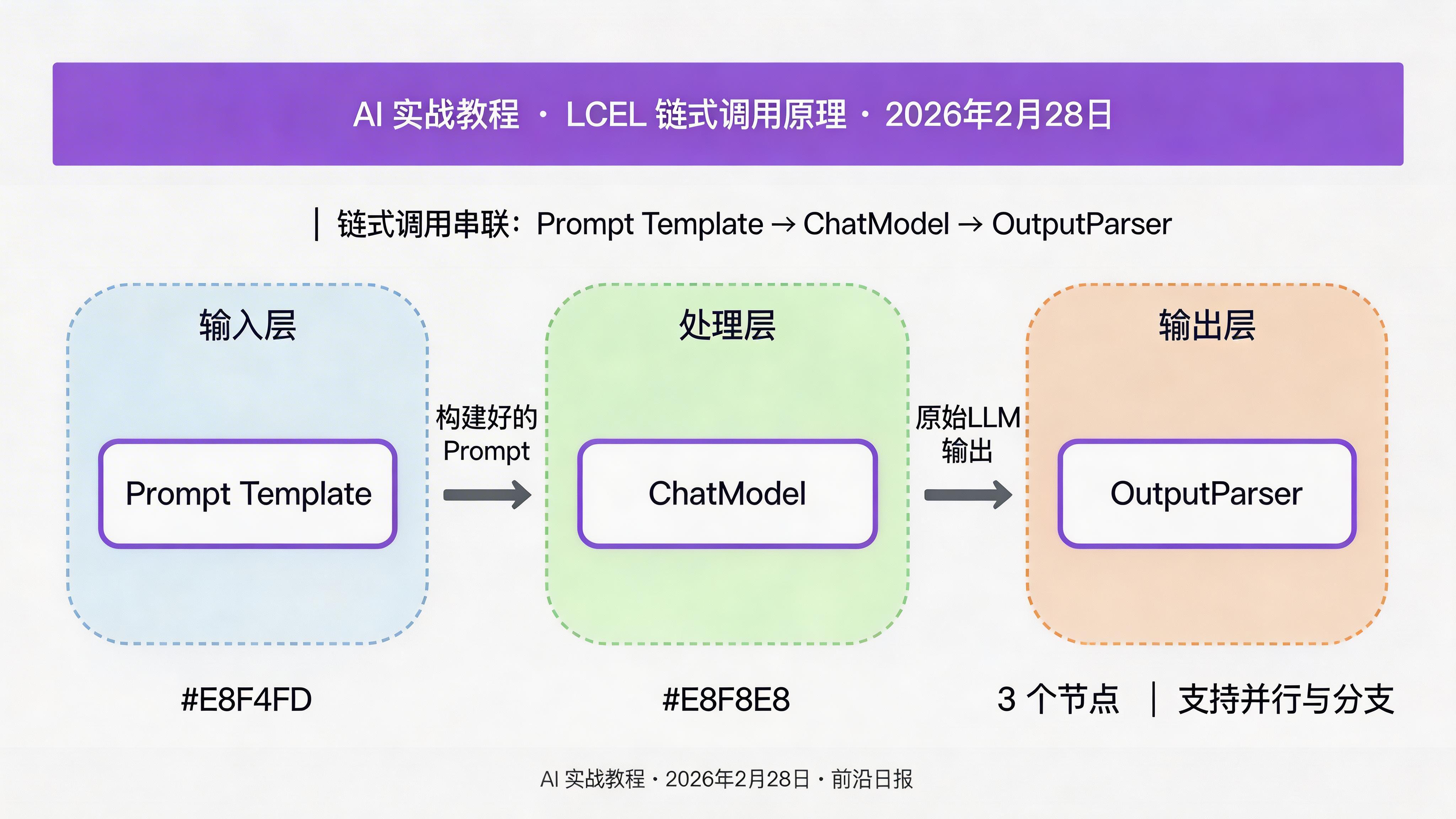
LangChain Expression Language(LCEL)是 0.3 版本的核心特性,用 Python 的 | 管道运算符串联各组件,代码极为简洁。
构建第一条链:翻译助手
这条链的逻辑是:提示模板 → LLM → 输出解析器,三个组件用 | 连接。
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from dotenv import load_dotenv
load_dotenv()
# 1. 定义提示模板({language} 和 {text} 是变量占位符)
prompt = ChatPromptTemplate.from_messages([
("system", "你是专业的翻译员,只输出翻译结果,不加任何解释。"),
("human", "请将以下文本翻译成{language}:\n\n{text}")
])
# 2. 初始化模型(temperature=0 确保输出稳定)
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 3. 用 | 组合成链(LCEL 核心语法)
chain = prompt | model | StrOutputParser()
# 4. 调用链(invoke 传入变量字典)
result = chain.invoke({
"language": "英文",
"text": "大语言模型正在改变软件开发的方式"
})
print(result)
# 输出:Large language models are transforming the way software is developed.并行链与分支
LCEL 还支持并行执行多个子链,用 RunnableParallel 包装:
from langchain_core.runnables import RunnableParallel
# 同时生成中英文摘要(两个子链并行调用 LLM)
summary_chain = RunnableParallel({
"chinese": ChatPromptTemplate.from_template("用中文总结:{text}") | model | StrOutputParser(),
"english": ChatPromptTemplate.from_template("Summarize in English: {text}") | model | StrOutputParser(),
})
result = summary_chain.invoke({"text": "人工智能在医疗影像诊断领域取得了重大突破..."})
print(result["chinese"])
print(result["english"])四、添加工具:构建能调用外部 API 的代理
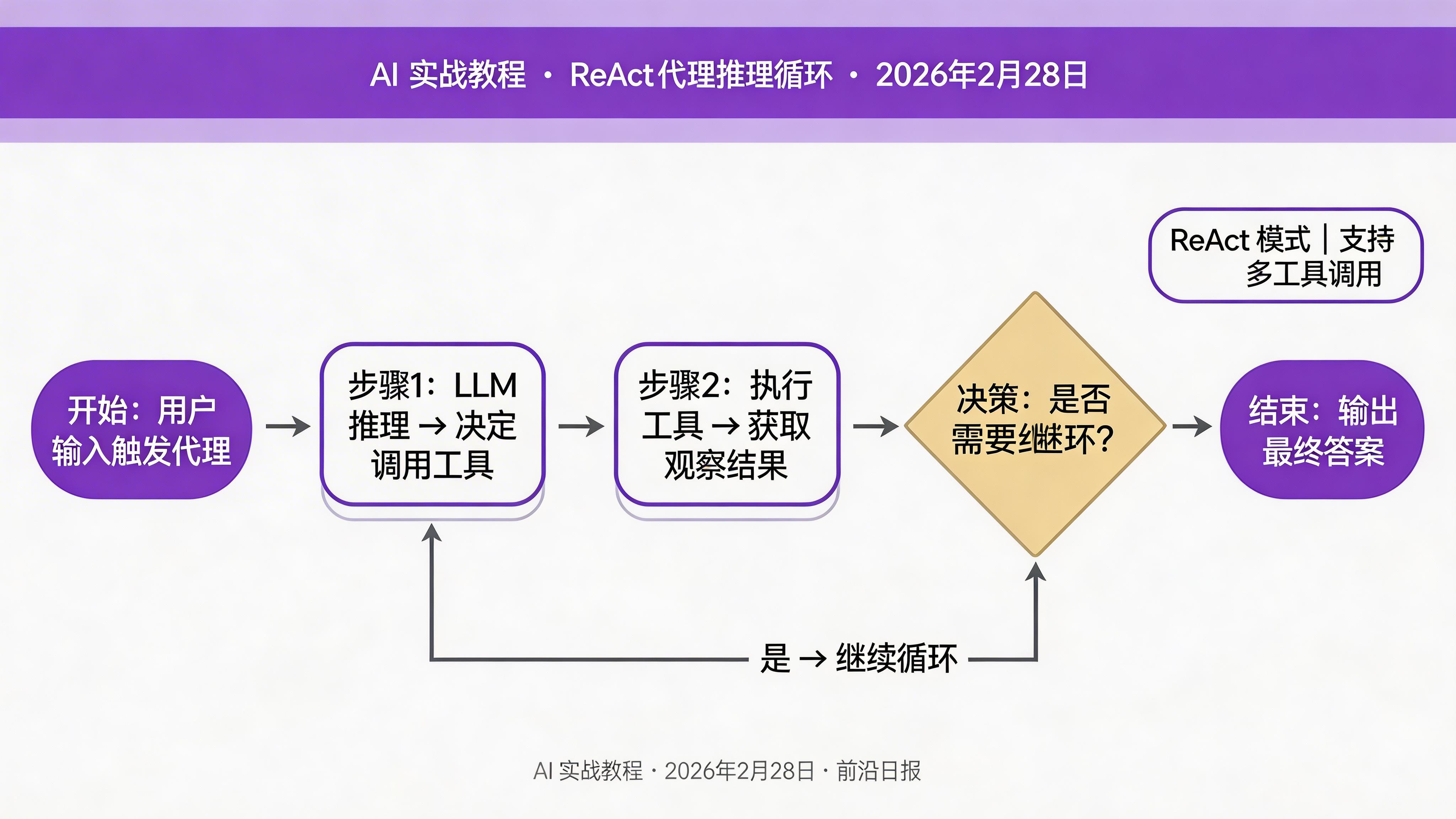
单纯的链只能处理文本,而代理(Agent)可以让 LLM 自主决策是否调用工具。这是 LangChain 最强大的能力之一。
定义工具并创建 ReAct 代理
用 @tool 装饰器将任意 Python 函数转换为 LLM 可调用的工具。函数的 docstring 会成为 LLM 理解工具用途的描述,一定要写清楚。
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from dotenv import load_dotenv
import requests, json
load_dotenv()
# ── 定义工具 ──────────────────────────────────
@tool
def get_weather(city: str) -> str:
"""获取指定城市的当前天气信息。
Args:
city: 城市名称,如 'Beijing'、'Shanghai'
"""
# 实际项目替换为真实天气 API
weather_data = {
"Beijing": "晴天,温度 18°C,湿度 45%",
"Shanghai": "多云,温度 22°C,湿度 68%",
}
return weather_data.get(city, f"{city} 的天气数据暂不可用")
@tool
def calculate(expression: str) -> str:
"""安全地计算数学表达式。
Args:
expression: 数学表达式字符串,如 '2 + 3 * 4'
"""
try:
# 仅允许安全操作
allowed = set('0123456789.+-*/()')
if not all(c in allowed for c in expression.replace(' ', '')):
return "不支持的表达式"
return str(eval(expression))
except Exception as e:
return f"计算错误:{e}"
# ── 创建代理 ──────────────────────────────────
model = ChatOpenAI(model="gpt-4o", temperature=0)
tools = [get_weather, calculate]
# create_react_agent 实现了 ReAct 推理循环(思考→行动→观察→思考...)
agent = create_react_agent(model, tools)
# ── 运行代理 ──────────────────────────────────
response = agent.invoke({
"messages": [("user", "北京现在天气怎么样?如果温度是 18 度,换算成华氏度是多少?")]
})
# 提取最后一条消息(AI 的最终回答)
print(response["messages"][-1].content)五、对话记忆:让 AI 记住上下文

默认情况下,每次调用 LLM 都是无状态的——它不记得上一轮说了什么。在多轮对话场景中,我们需要显式管理对话历史。
基于 LangGraph 实现有状态的对话
LangGraph(LangChain 官方推荐的代理框架)内置了状态管理,支持多轮对话、持久化存储。
memory_chat.pyfrom langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import create_react_agent
from dotenv import load_dotenv
load_dotenv()
model = ChatOpenAI(model="gpt-4o-mini")
# MemorySaver 将对话历史存储在内存中(生产环境替换为 SqliteSaver 或 Redis)
memory = MemorySaver()
agent = create_react_agent(model, tools=[], checkpointer=memory)
# 每个会话用 thread_id 区分(同一个 id 的调用共享历史)
config = {"configurable": {"thread_id": "user-123"}}
# 第一轮对话
r1 = agent.invoke(
{"messages": [HumanMessage("我叫小明,我喜欢编程和爬山。")]},
config=config
)
print("第一轮:", r1["messages"][-1].content)
# 第二轮对话(代理会记住"小明"这个名字)
r2 = agent.invoke(
{"messages": [HumanMessage("你还记得我叫什么吗?我有什么爱好?")]},
config=config
)
print("第二轮:", r2["messages"][-1].content)
# 输出:你叫小明,你的爱好是编程和爬山。长上下文处理:对话历史压缩
当对话轮次很多时,历史消息会消耗大量 token。可以用摘要策略压缩历史:
memory_summary.pyfrom langchain_core.messages import SystemMessage
from langchain_openai import ChatOpenAI
def summarize_history(messages: list, model: ChatOpenAI) -> str:
"""将历史对话压缩为摘要,保留关键信息。"""
history_text = "\n".join([
f"{'用户' if isinstance(m, HumanMessage) else 'AI'}: {m.content}"
for m in messages
])
summary_prompt = f"请用 200 字以内总结以下对话的要点:\n\n{history_text}"
summary = model.invoke([HumanMessage(summary_prompt)])
return summary.content六、RAG 实战:让 AI 读取你的文档
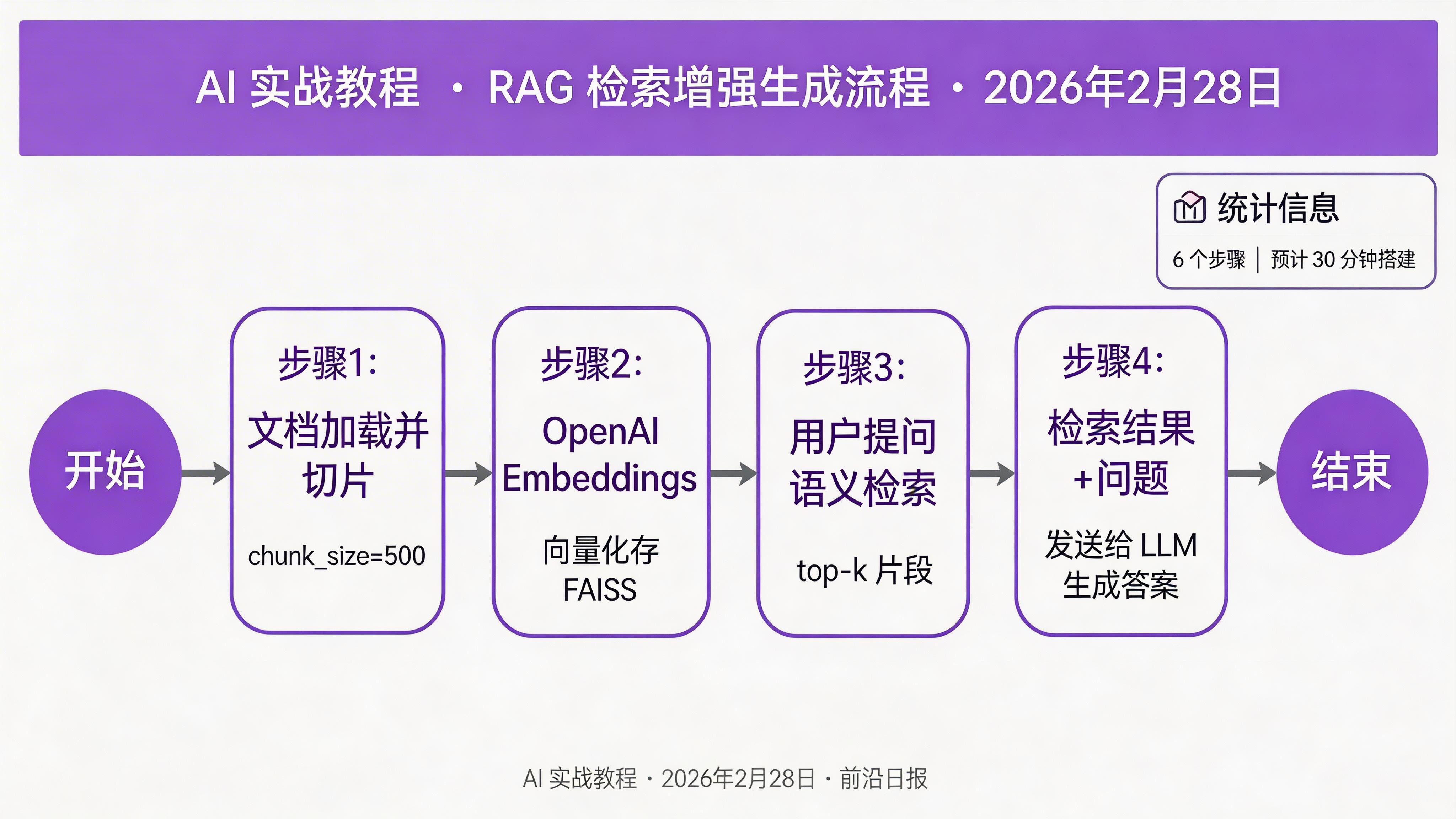
RAG(Retrieval-Augmented Generation,检索增强生成)是目前最主流的 LLM 应用模式之一。核心思路是:将文档切片存入向量数据库,用户提问时检索相关片段,连同问题一起发送给 LLM。
构建本地文档问答系统
以下代码实现了完整的 RAG 流水线:文档加载 → 分块 → 向量化 → 检索 → 生成。
rag_pipeline.pyfrom langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from dotenv import load_dotenv
load_dotenv()
# ── Step 1: 加载文档 ──────────────────────────
loader = TextLoader("docs/product_manual.txt", encoding="utf-8")
documents = loader.load()
# ── Step 2: 文档切片(chunk_size 控制粒度,overlap 保留上下文连续性)
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!", "?", " "]
)
chunks = splitter.split_documents(documents)
print(f"文档切分为 {len(chunks)} 个片段")
# ── Step 3: 向量化并存入 FAISS(本地向量数据库,无需部署服务)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = FAISS.from_documents(chunks, embeddings)
# 持久化到本地(下次直接加载,无需重新向量化)
vectorstore.save_local("faiss_index")
# 加载:vectorstore = FAISS.load_local("faiss_index", embeddings)
# ── Step 4: 构建检索器(top-k=3 返回最相关的 3 个片段)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# ── Step 5: 构建 RAG Chain ─────────────────────
rag_prompt = ChatPromptTemplate.from_messages([
("system", """你是专业的文档助手。请根据以下文档内容回答用户问题。
如果文档中没有相关信息,明确告知用户"文档中未找到相关内容",不要编造答案。
文档内容:
{context}"""),
("human", "{question}")
])
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
def format_docs(docs):
"""将检索结果格式化为字符串"""
return "\n\n---\n\n".join([d.page_content for d in docs])
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| model
| StrOutputParser()
)
# ── Step 6: 运行问答 ──────────────────────────
answer = rag_chain.invoke("产品的退款政策是什么?")
print(answer)chunk_size=300~500 通常效果较好。太小会导致上下文不足,太大会引入噪音,影响检索精度。
七、结构化输出:用 Pydantic 约束 AI 响应

在实际生产场景中,我们通常需要 LLM 返回 JSON 格式的结构化数据,而不是自由文本。LangChain 与 Pydantic 深度集成,可以强制约束输出格式。
用 Pydantic 定义输出模式
structured_output.pyfrom pydantic import BaseModel, Field
from typing import List, Literal
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
# 定义输出结构
class ProductReview(BaseModel):
"""商品评价分析结果"""
sentiment: Literal["positive", "negative", "neutral"] = Field(
description="情感倾向"
)
score: int = Field(
ge=1, le=5,
description="评分,1-5 分"
)
highlights: List[str] = Field(
description="核心亮点列表,每条不超过 20 字"
)
issues: List[str] = Field(
default=[],
description="提及的问题或缺点"
)
# with_structured_output 自动处理格式提示和解析
model = ChatOpenAI(model="gpt-4o-mini")
structured_model = model.with_structured_output(ProductReview)
review_text = """
这款耳机音质真的很棒,低音饱满,佩戴也很舒适,续航达到了标注的 30 小时。
美中不足是连接偶尔会断,希望后续固件能修复。整体还是很满意的。
"""
result: ProductReview = structured_model.invoke(
f"请分析以下商品评价:\n{review_text}"
)
print(f"情感:{result.sentiment}")
print(f"评分:{result.score}/5")
print(f"亮点:{result.highlights}")
print(f"问题:{result.issues}")八、进阶:LangSmith 可观测性与生产调优

将 AI 应用推向生产环境,需要解决三个核心问题:调试难(LLM 黑盒难以排查)、成本高(每次调用都消耗 token)、延迟大(链式调用累加延迟)。LangSmith 提供了完整的解决方案。
启用 LangSmith 追踪与语义缓存
production.pyimport os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_core.globals import set_llm_cache
from langchain_community.cache import InMemorySemanticCache
load_dotenv()
# ── 1. LangSmith 追踪(在 .env 中配置 LANGCHAIN_TRACING_V2=true 即可自动开启)
# 所有链的调用会自动记录到 https://smith.langchain.com
os.environ["LANGCHAIN_PROJECT"] = "my-production-app"
# ── 2. 语义缓存(相似问题命中缓存,节省 token 费用)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
set_llm_cache(InMemorySemanticCache(
embedding=embeddings,
score_threshold=0.95 # 相似度阈值,越高越严格
))
model = ChatOpenAI(model="gpt-4o-mini")
# ── 3. 流式输出(降低首 token 延迟感知)
print("流式输出:", end="", flush=True)
for chunk in model.stream("简述 LangChain 的三大核心优势"):
print(chunk.content, end="", flush=True)
print()
# ── 4. 回调钩子:自定义日志记录
from langchain_core.callbacks import BaseCallbackHandler
class TokenCounter(BaseCallbackHandler):
def __init__(self):
self.total_tokens = 0
def on_llm_end(self, response, **kwargs):
usage = response.generations[0][0].generation_info.get("usage", {})
self.total_tokens += usage.get("total_tokens", 0)
print(f"\n[Token 统计] 本次消耗: {usage.get('total_tokens', 0)}")
counter = TokenCounter()
model_tracked = ChatOpenAI(model="gpt-4o-mini", callbacks=[counter])
model_tracked.invoke("什么是 LangGraph?")九、常见问题解答
| 问题 | 解决方案 |
|---|---|
| ImportError:找不到模块 | LangChain 0.3 拆分为多个包。langchain-openai、langchain-anthropic 等需单独安装。参考错误提示中的包名执行 pip install。 |
| API Key 报 401 错误 | 检查 .env 文件是否在当前工作目录,确认 load_dotenv() 在代码最顶部调用,Key 是否过期或余额不足。 |
| RAG 检索结果不准确 | 尝试减小 chunk_size(如 200~300),增加 chunk_overlap,或换用更强的 Embedding 模型(如 text-embedding-3-large)。 |
| 代理陷入无限循环 | 在 create_react_agent 中设置 recursion_limit(默认 25),为工具函数添加完善的错误处理和返回值验证。 |
| Pydantic 解析失败 | 确保使用支持结构化输出的模型(GPT-4o 系列最稳定)。字段描述要清晰,避免歧义。可添加 .with_structured_output(ProductReview, strict=True)。 |
| 响应延迟过高 | 启用语义缓存、使用 gpt-4o-mini 替代 gpt-4o、将独立子链改为 RunnableParallel 并行执行、开启流式输出改善感知延迟。 |
本教程核心要点
- LCEL 的
|管道语法让组件组合变得直观,是 LangChain 0.3 的核心编程模型 - 用
@tool+create_react_agent快速构建能调用外部 API 的智能代理 MemorySaver+thread_id实现多轮对话,SqliteSaver适合生产持久化- RAG 管道的关键参数:
chunk_size、chunk_overlap、k(检索数量)需要根据实际文档调优 .with_structured_output(PydanticModel)是获取可靠结构化输出的最佳实践- LangSmith 追踪 + 语义缓存 + 流式输出是生产环境三板斧
下一步学习方向
掌握本教程的内容后,建议进一步探索:
- LangGraph:构建复杂的多代理工作流,支持条件分支、循环、人机协作(Human-in-the-Loop)
- 多模态 RAG:处理包含图表的 PDF 文档,结合视觉模型提升检索质量
- 生产部署:用 LangServe 将链暴露为 REST API,或集成到 FastAPI 应用中
- 评估系统:用 LangSmith Dataset 构建自动化评估流水线,持续监控生产效果