Cloudflare Workers + AI:
构建实时智能工作流
边缘计算 + AI 正在重新定义工作流的速度边界。Cloudflare Workers 将你的代码运行在全球 300+ 个边缘节点,Workers AI 则将大语言模型的推理能力直接嵌入这些节点——两者组合,可以做到:用户请求到达后,毫秒级调用 LLM,完成分类、摘要、生成,再把结果缓存在 KV 里,无需回源。
本教程将带你从头构建一套包含实时文本生成、多轮对话、向量检索(RAG)和持久化多步骤工作流的智能系统,并最终部署到 Cloudflare 生产环境。
一、核心概念:理解三层架构
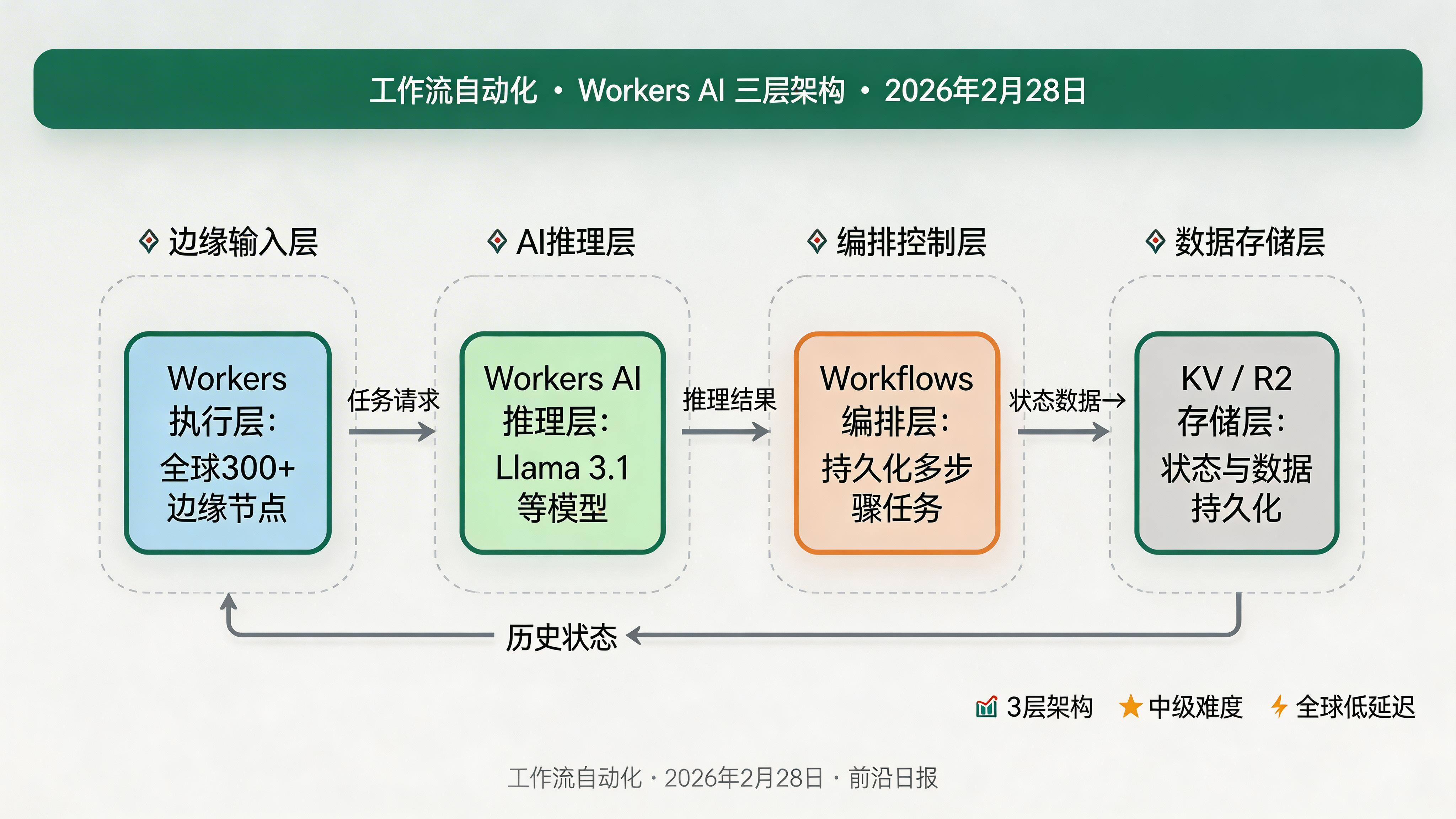
在动手写代码之前,先理解这套系统的三个核心层次:
- Cloudflare Workers(执行层):无服务器边缘运行时,负责接收 HTTP 请求、路由分发、调用 AI 绑定。每个请求在最近的边缘节点处理,冷启动 <5ms。
- Workers AI(推理层):Cloudflare 托管的模型推理服务,支持 Llama 3.1、Mistral、Whisper、BAAI/bge-base 等数十种开源模型。通过
env.AI.run()一行代码调用,无需管理 GPU。 - Cloudflare Workflows(编排层):持久化多步骤执行引擎,内置重试、超时、事件等待能力。适合需要 >30 秒的长任务,如批量文档处理、异步 AI 管线。
三层协同的典型数据流:用户发起请求 → Workers 路由 → 调用 Workers AI 获得 LLM 响应 → 写入 KV/R2 → (可选)触发 Workflows 完成后续异步处理。
二、环境准备与项目初始化
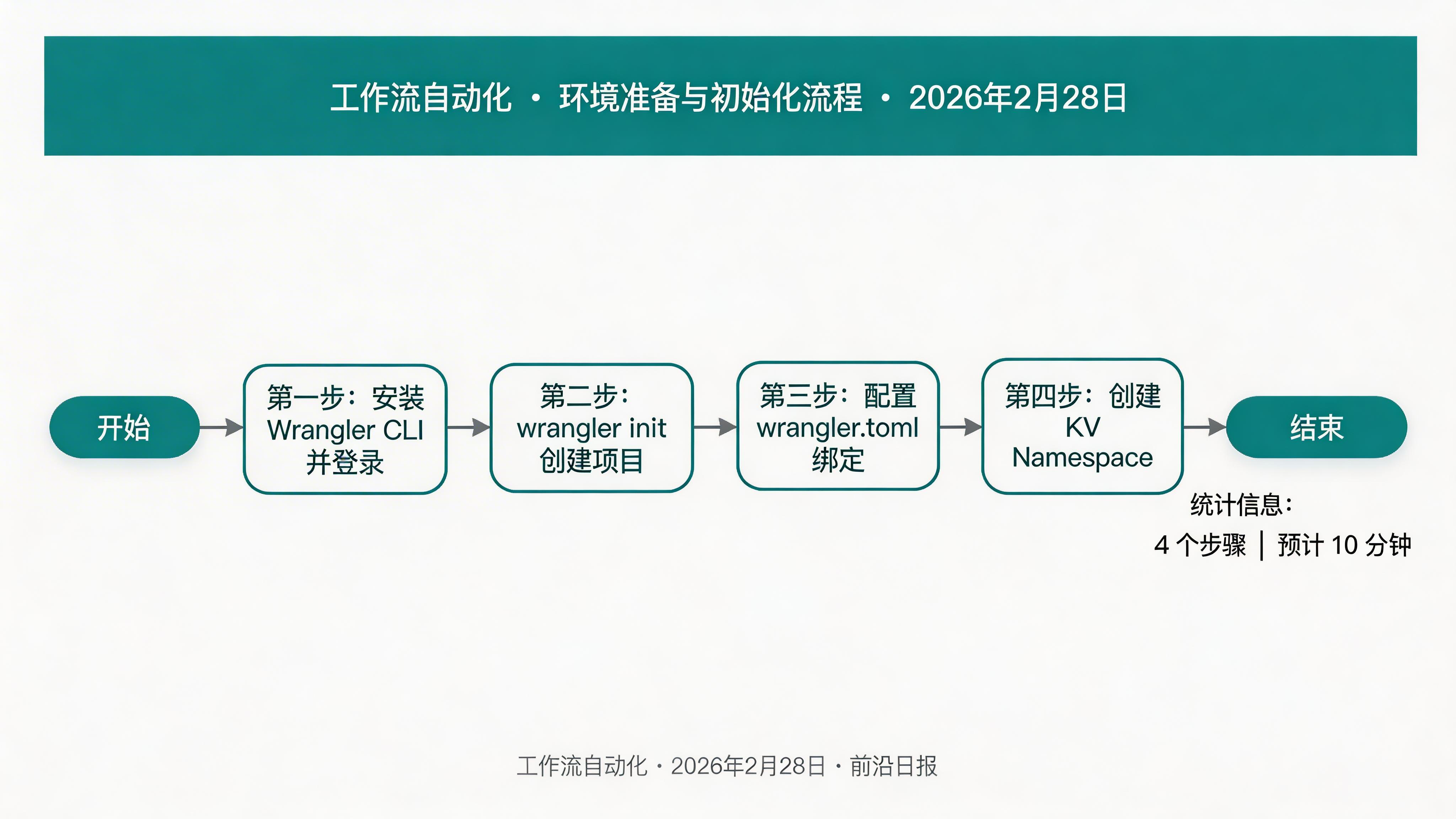
安装 Wrangler CLI 并登录
Wrangler 是 Cloudflare 官方的 CLI 工具,负责本地开发、预览和部署。
# 安装 Wrangler(需要 Node.js 18+)
npm install -g wrangler
# 登录 Cloudflare 账号(会打开浏览器授权页)
wrangler login
# 验证登录状态
wrangler whoami创建 Workers 项目
# 使用 TypeScript 模板创建项目
wrangler init ai-workflow --type=javascript
# 或者使用 npm create 脚手架
npm create cloudflare@latest ai-workflow
# 进入项目目录
cd ai-workflow项目结构如下:
ai-workflow/
├── src/
│ └── worker.ts # 主入口
├── wrangler.toml # 配置文件
├── package.json
└── tsconfig.json配置 wrangler.toml
在 wrangler.toml 中声明 AI 绑定和 KV 存储:
name = "ai-workflow"
main = "src/worker.ts"
compatibility_date = "2024-09-23"
compatibility_flags = ["nodejs_compat"]
# Workers AI 绑定
[ai]
binding = "AI"
# KV 存储(用于会话状态)
[[kv_namespaces]]
binding = "SESSIONS"
id = "你的 KV Namespace ID"
preview_id = "你的预览 KV Namespace ID"wrangler kv namespace create SESSIONS 自动创建 KV 并获得 ID。三、实现第一个 AI 文本生成接口
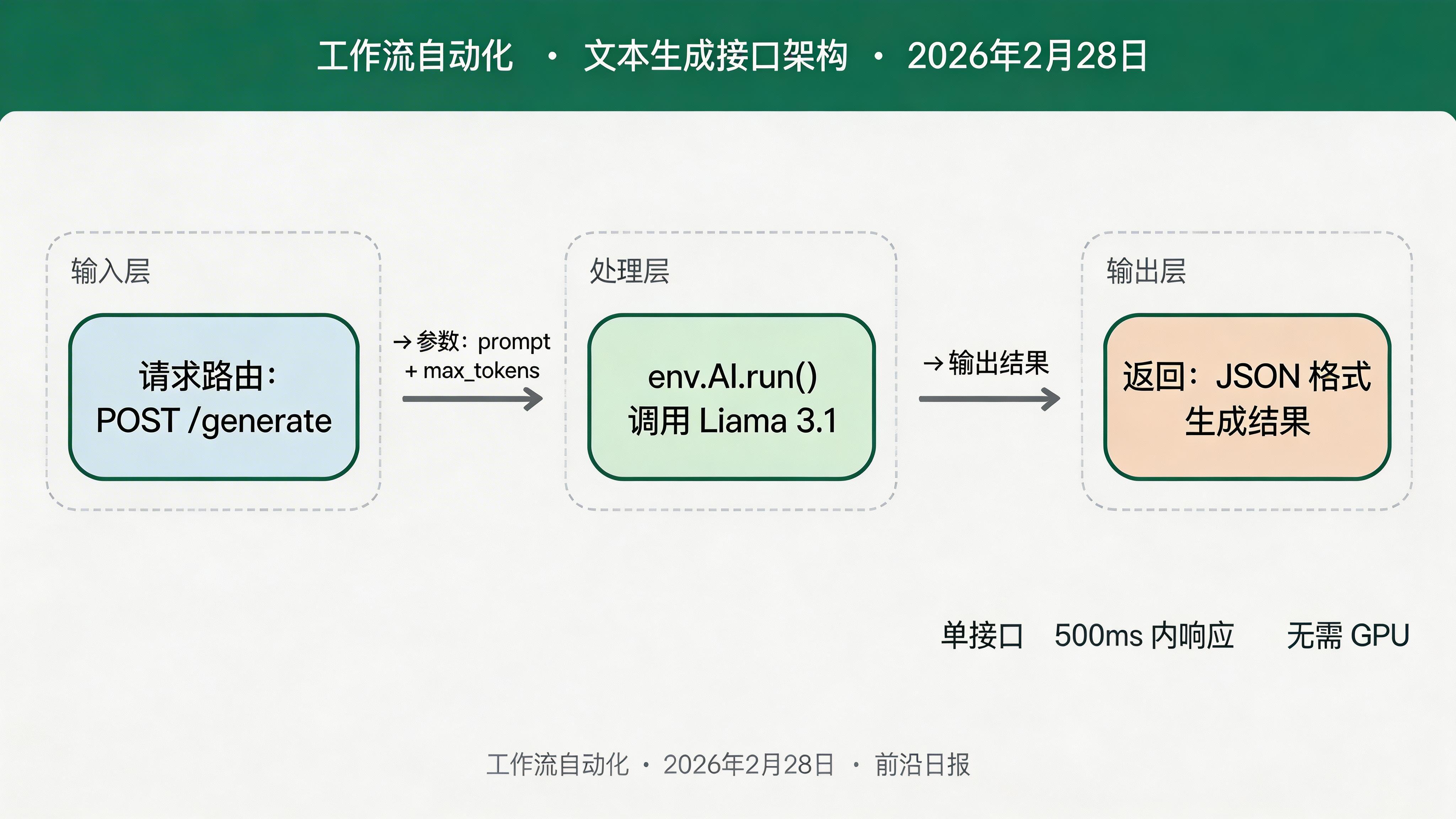
现在来写第一个有实际功能的 Worker:接收用户的文本 Prompt,调用 Llama 3.1 模型,返回 AI 生成的内容。
类型定义
新建 src/types.ts:
export interface Env {
AI: Ai;
SESSIONS: KVNamespace;
}
export interface GenerateRequest {
prompt: string;
max_tokens?: number;
system?: string;
}主 Worker 入口
编辑 src/worker.ts:
import { Env, GenerateRequest } from './types';
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const url = new URL(request.url);
const { pathname } = url;
// 路由分发
if (request.method === "POST" && pathname === "/generate") {
return handleGenerate(request, env);
}
if (request.method === "POST" && pathname === "/chat") {
return handleChat(request, env);
}
return new Response("Not found", { status: 404 });
}
};
// ── 文本生成处理器 ──
async function handleGenerate(
request: Request,
env: Env
): Promise<Response> {
try {
const body = await request.json() as GenerateRequest;
if (!body.prompt?.trim()) {
return Response.json(
{ error: "prompt 不能为空" },
{ status: 400 }
);
}
// 调用 Llama 3.1 模型
const messages = [
{
role: "system",
content: body.system ?? "你是一个专业、简洁的 AI 助手。"
},
{ role: "user", content: body.prompt }
];
const result = await env.AI.run(
"@cf/meta/llama-3.1-8b-instruct",
{ messages, max_tokens: body.max_tokens ?? 500 }
);
return Response.json({
success: true,
response: (result as any).response,
model: "llama-3.1-8b-instruct"
});
} catch (err) {
return Response.json(
{ error: "生成失败", detail: String(err) },
{ status: 500 }
);
}
}本地测试
# 启动本地开发服务器
wrangler dev
# 另开终端发送测试请求
curl -X POST http://localhost:8787/generate \
-H "Content-Type: application/json" \
-d '{"prompt": "用三句话解释量子计算"}'wrangler dev 会自动连接到 Cloudflare 远程推理服务,无需在本地安装任何模型。四、构建多轮对话机器人(基于 KV 会话存储)
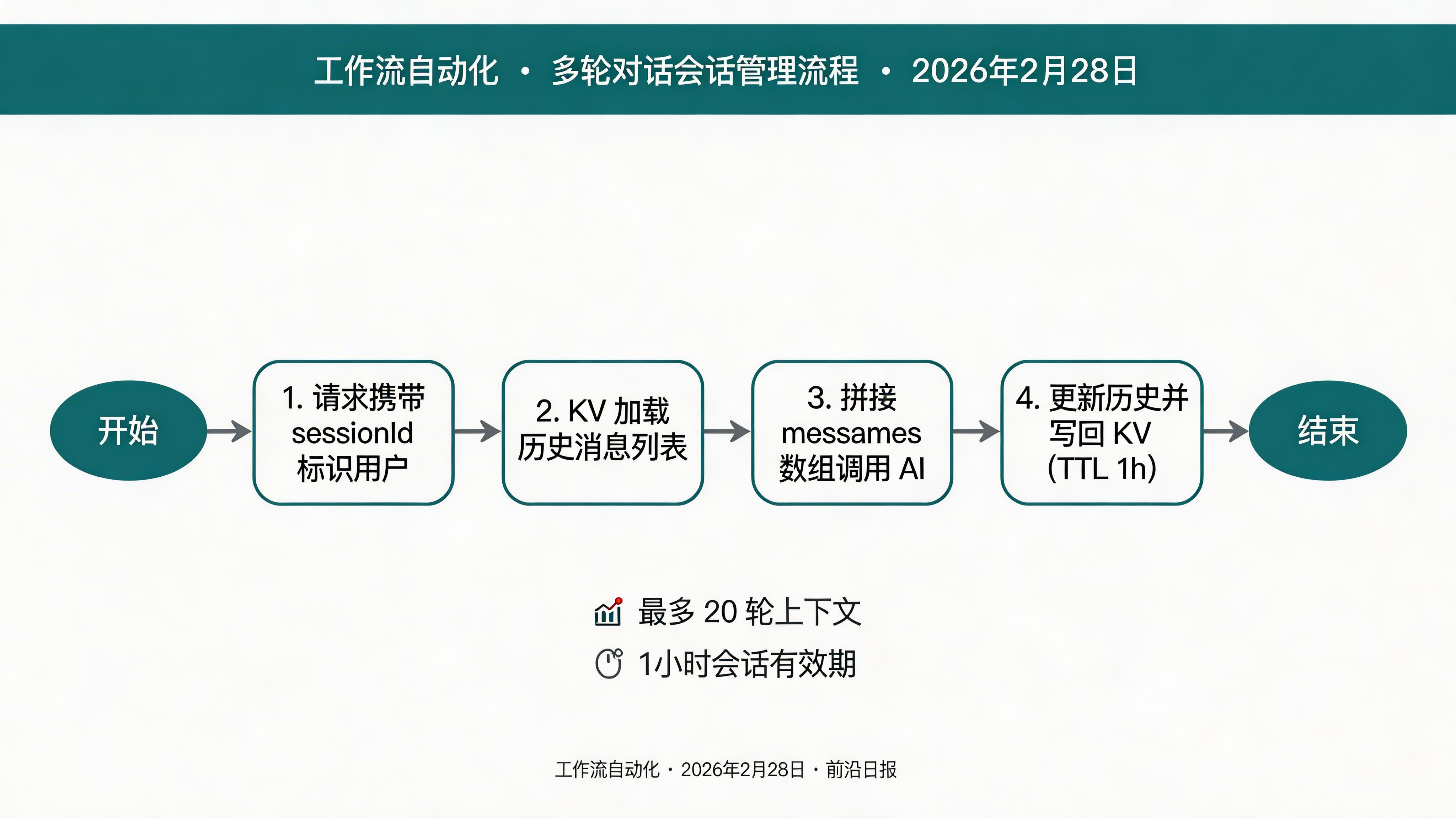
单轮问答满足不了真实需求——用户期望 AI 记住上下文。我们用 KV 存储会话历史,实现有状态的多轮对话。
会话管理逻辑
在 src/worker.ts 中补充 handleChat:
interface Message {
role: "user" | "assistant" | "system";
content: string;
}
async function handleChat(
request: Request,
env: Env
): Promise<Response> {
const { sessionId, message, system } =
await request.json() as {
sessionId: string;
message: string;
system?: string;
};
// 从 KV 加载历史消息
const raw = await env.SESSIONS.get(`session:${sessionId}`);
const history: Message[] = raw ? JSON.parse(raw) : [];
// 构造完整 messages 数组
const messages: Message[] = [
{ role: "system", content: system ?? "你是一个耐心、专业的助手。" },
...history,
{ role: "user", content: message }
];
// 调用 AI
const result = await env.AI.run(
"@cf/meta/llama-3.1-8b-instruct",
{ messages, max_tokens: 600 }
);
const assistantReply = (result as any).response as string;
// 更新历史(最多保留 20 条,避免超出 token 上限)
const updated = [
...history,
{ role: "user" as const, content: message },
{ role: "assistant" as const, content: assistantReply }
].slice(-20);
await env.SESSIONS.put(
`session:${sessionId}`,
JSON.stringify(updated),
{ expirationTtl: 3600 } // 1 小时后过期
);
return Response.json({
sessionId,
reply: assistantReply,
turns: updated.length / 2
});
}测试多轮对话
# 第一轮
curl -X POST http://localhost:8787/chat \
-H "Content-Type: application/json" \
-d '{"sessionId":"user-001","message":"我想学 Rust,从哪里开始?"}'
# 第二轮(AI 会记住上下文)
curl -X POST http://localhost:8787/chat \
-H "Content-Type: application/json" \
-d '{"sessionId":"user-001","message":"推荐几本适合初学者的书"}'sessionId 必须经过身份验证,避免用户互相读取会话。可在请求头中传入 JWT 并验证后再拼接 session key。五、集成向量检索:用 RAG 增强知识问答

大语言模型的知识有截止日期,也无法掌握你的私有文档。RAG(检索增强生成)模式将文档向量化存储,在回答时先检索相关片段,再注入 Prompt,让 AI 基于真实数据作答。
使用 Vectorize 存储向量
先在 wrangler.toml 中添加 Vectorize 绑定:
[[vectorize]]
binding = "VECTORIZE"
index_name = "knowledge-base"# 创建向量索引(维度 768 对应 BAAI/bge-base 模型)
wrangler vectorize create knowledge-base \
--dimensions=768 \
--metric=cosine写入文档向量
// src/rag.ts
export async function indexDocument(
env: Env & { VECTORIZE: VectorizeIndex },
docId: string,
text: string
) {
// 生成嵌入向量
const embedResult = await env.AI.run(
"@cf/baai/bge-base-en-v1.5",
{ text: [text] }
);
const vector = (embedResult as any).data[0] as number[];
// 存入 Vectorize
await env.VECTORIZE.upsert([
{
id: docId,
values: vector,
metadata: { text: text.slice(0, 500) } // 保存原文片段
}
]);
}
// 检索最相关的 K 个文档
export async function searchDocuments(
env: Env & { VECTORIZE: VectorizeIndex },
query: string,
topK = 3
): Promise<string[]> {
const embedResult = await env.AI.run(
"@cf/baai/bge-base-en-v1.5",
{ text: [query] }
);
const queryVector = (embedResult as any).data[0] as number[];
const results = await env.VECTORIZE.query(queryVector, {
topK,
returnMetadata: true
});
return results.matches
.filter(m => m.score > 0.7) // 相似度阈值
.map(m => m.metadata?.text as string);
}在问答接口中注入检索结果
async function handleRagQuery(
request: Request,
env: Env & { VECTORIZE: VectorizeIndex }
) {
const { question } = await request.json() as { question: string };
// 1. 检索相关文档
const contexts = await searchDocuments(env, question);
const contextText = contexts.length
? contexts.join("\n\n---\n\n")
: "(无相关知识库内容)";
// 2. 构造 RAG Prompt
const systemPrompt = `你是知识库助手。请基于以下背景资料回答用户的问题,如果资料中没有答案,请如实告知。
背景资料:
${contextText}`;
// 3. 调用 LLM
const result = await env.AI.run(
"@cf/meta/llama-3.1-8b-instruct",
{
messages: [
{ role: "system", content: systemPrompt },
{ role: "user", content: question }
]
}
);
return Response.json({
answer: (result as any).response,
contextCount: contexts.length
});
}六、使用 Cloudflare Workflows 编排异步任务
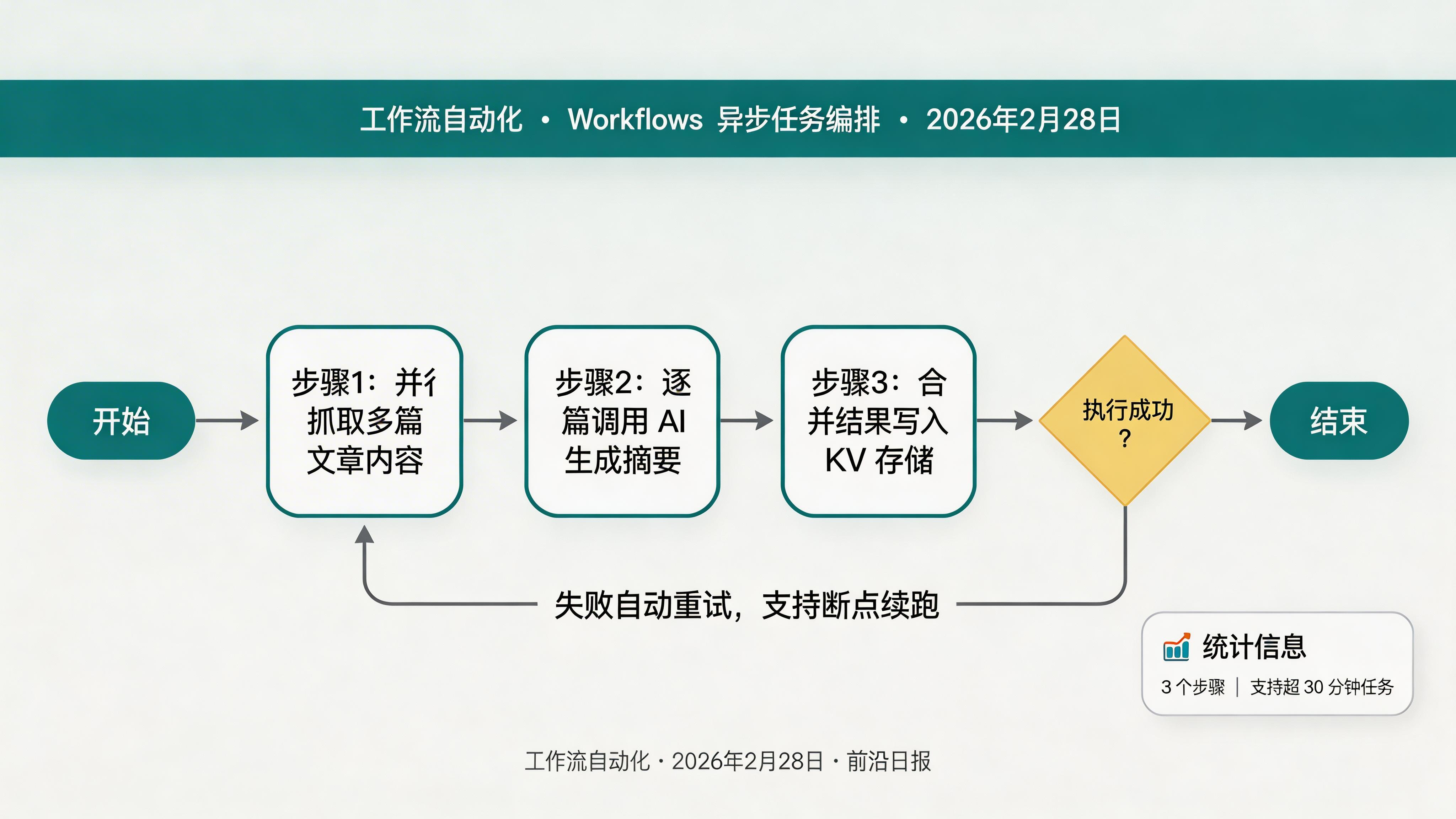
Workers 的执行时间有限制(最长 30 秒),但有些任务需要更长时间:批量处理 100 篇文章、分步骤抓取多个 API 再整合……这时就需要 Cloudflare Workflows。
Workflows 的核心特性:
- 持久化状态:中途失败可从断点重试
- 内置重试:步骤级别的自动重试和超时控制
- 事件等待:支持
waitForEvent暂停执行等待外部触发 - 并发控制:可配置并发工作流实例上限
定义工作流
新建 src/workflow.ts:
import {
WorkflowEntrypoint,
WorkflowStep,
WorkflowEvent
} from "cloudflare:workers";
import { Env } from "./types";
interface ArticleSummaryParams {
articleUrls: string[];
outputKey: string;
}
export class ArticleSummaryWorkflow
extends WorkflowEntrypoint<Env, ArticleSummaryParams> {
async run(
event: WorkflowEvent<ArticleSummaryParams>,
step: WorkflowStep
) {
const { articleUrls, outputKey } = event.payload;
// 步骤 1:并行抓取文章内容
const contents = await step.do("fetch-articles", async () => {
const results = await Promise.allSettled(
articleUrls.map(async url => {
const res = await fetch(url);
return res.text();
})
);
return results
.filter(r => r.status === "fulfilled")
.map(r => (r as PromiseFulfilledResult<string>).value);
});
// 步骤 2:逐篇 AI 摘要
const summaries = await step.do("summarize-articles", async () => {
const results: string[] = [];
for (const content of contents) {
const r = await this.env.AI.run(
"@cf/meta/llama-3.1-8b-instruct",
{
messages: [
{ role: "system", content: "请用 3 句话总结文章核心内容。" },
{ role: "user", content: content.slice(0, 3000) }
]
}
);
results.push((r as any).response);
}
return results;
});
// 步骤 3:合并结果写入 R2/KV
await step.do("save-result", async () => {
const combined = summaries.join("\n\n");
await this.env.SESSIONS.put(outputKey, combined);
});
return { processed: summaries.length, outputKey };
}
}在 wrangler.toml 注册工作流
[[workflows]]
binding = "ARTICLE_WORKFLOW"
name = "article-summary-workflow"
class_name = "ArticleSummaryWorkflow"触发工作流
// 在 Worker 中触发工作流实例
async function handleBatchSummary(
request: Request,
env: Env & { ARTICLE_WORKFLOW: Workflow }
) {
const { urls } = await request.json() as { urls: string[] };
const instanceId = crypto.randomUUID();
const instance = await env.ARTICLE_WORKFLOW.create({
id: instanceId,
params: {
articleUrls: urls,
outputKey: `summary:${instanceId}`
}
});
return Response.json({
workflowId: instance.id,
status: "started",
// 客户端可轮询此接口查询进度
pollUrl: `/workflow-status/${instance.id}`
});
}七、部署到生产环境

本地构建验证
# TypeScript 类型检查
npx tsc --noEmit
# Wrangler 本地预览(连接真实 Cloudflare 服务)
wrangler dev --remote存储敏感配置(Secrets)
# 存储 API 密钥(不会出现在 wrangler.toml)
wrangler secret put OPENAI_API_KEY
wrangler secret put JWT_SECRET
# 列出所有 Secrets
wrangler secret listwrangler secret 管理,在 Worker 中通过 env.SECRET_NAME 读取。部署到生产
# 一键部署
wrangler deploy
# 指定环境(如 staging / production)
wrangler deploy --env production部署成功后,Wrangler 会输出你的 Worker URL,例如:
Published ai-workflow (1.23 sec)
https://ai-workflow.your-account.workers.dev绑定自定义域名
# 在 wrangler.toml 中添加路由[env.production]
routes = [
{ pattern = "api.yourdomain.com/*", zone_name = "yourdomain.com" }
]查看实时日志和指标
# 实时流式日志(生产环境)
wrangler tail
# 过滤特定状态码
wrangler tail --status error也可在 Cloudflare Dashboard → Workers → 你的 Worker → Metrics 查看请求量、错误率、P99 延迟等指标。
常见问题解答
| 问题 | 解决方案 |
|---|---|
| Workers AI 调用速度慢? | 对于重复请求,使用 Cache API 缓存 AI 响应。将 caches.default.put(cacheKey, response) 放在 AI 调用后,下次请求先 match 缓存。 |
| 如何防止 Prompt 注入攻击? | 不要直接拼接用户输入到 system prompt。将用户内容始终放在 user role 的 message 中,system prompt 中的内容由服务端控制。 |
| Workflow 步骤执行超时? | 每个步骤可设置独立超时:step.do("step-name", { timeout: "5 minutes" }, async () => {...}),最长支持 24 小时。 |
| 如何控制 AI 调用费用? | Workers AI 按 token 计费。可在路由层增加请求频率限制(配合 Cloudflare Rate Limiting 规则),并对 max_tokens 设置合理上限。 |
本地 wrangler dev 无法连接 AI? |
运行 wrangler dev --remote(远程模式)可访问真实 Workers AI。本地模式不支持 AI 绑定。 |
本教程总结
- 用 Workers AI 在边缘节点直接调用 LLM,无需管理服务器
- 通过 KV 存储实现多轮对话状态持久化
- 结合 Vectorize + BAAI/bge 构建私有知识库 RAG 问答
- 用 Cloudflare Workflows 编排超过 30 秒的异步 AI 任务
- 通过 Wrangler Secrets 安全管理敏感配置
下一步:尝试接入 @cf/openai/whisper 语音转文字模型,构建语音输入的智能问答工作流。