引言 为什么你的 AI Agent 无法投入生产?
想象这个场景:你花了一周构建了一个 AI 客服 Agent,它在测试环境运行完美——能准确理解用户意图、调用正确的工具、给出专业回答。但上线第一天就出了问题:
- 服务器重启后,所有进行中的对话全部丢失
- 用户要求"稍等一下,我去查下订单",Agent 无法等待
- 某个工具调用超时,整个工作流崩溃,用户需要重新描述问题
- 你想看看 Agent 为什么做出了错误决策,但没有任何执行日志
传统 LLM 应用采用无状态线性链式架构——每个请求从头开始,无法保留中间状态,不支持暂停/恢复,缺少可观察性。这种架构可以做出漂亮的 Demo,但无法应对生产环境的复杂性。
本教程将带你掌握 LangGraph 1.0 的状态图编排能力,这是一个由 LangChain 团队开发的生产级 AI 工作流框架,已被 NVIDIA、IBM 等公司用于构建关键业务系统。学完本教程后,你将能够:
✓ 设计状态图
使用 TypedDict 定义状态契约,用节点和边构建清晰的执行流程
✓ 实现 Human-in-the-loop
在关键决策点暂停,等待人类审批后再继续执行
✓ 添加持久化
使用 PostgreSQL 检查点,崩溃后从断点恢复而不丢失进度
✓ 调试与观测
通过 LangGraph Studio 可视化执行轨迹,快速定位问题
01 环境准备与核心概念
首先创建项目并安装依赖:
# 创建项目目录
mkdir langgraph-tutorial && cd langgraph-tutorial
# 初始化 Python 项目
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
# 安装依赖
pip install langgraph langchain-openai langchain-community
pip install psycopg2-binary # PostgreSQL 驱动创建 .env 文件配置 API 密钥:
OPENAI_API_KEY=sk-xxx
DATABASE_URL=postgresql://user:pass@localhost:5432/langgraph_demo检查点持久化需要 PostgreSQL。如果只想快速体验,可以暂时跳过数据库配置,使用内存模式(重启后数据丢失)。
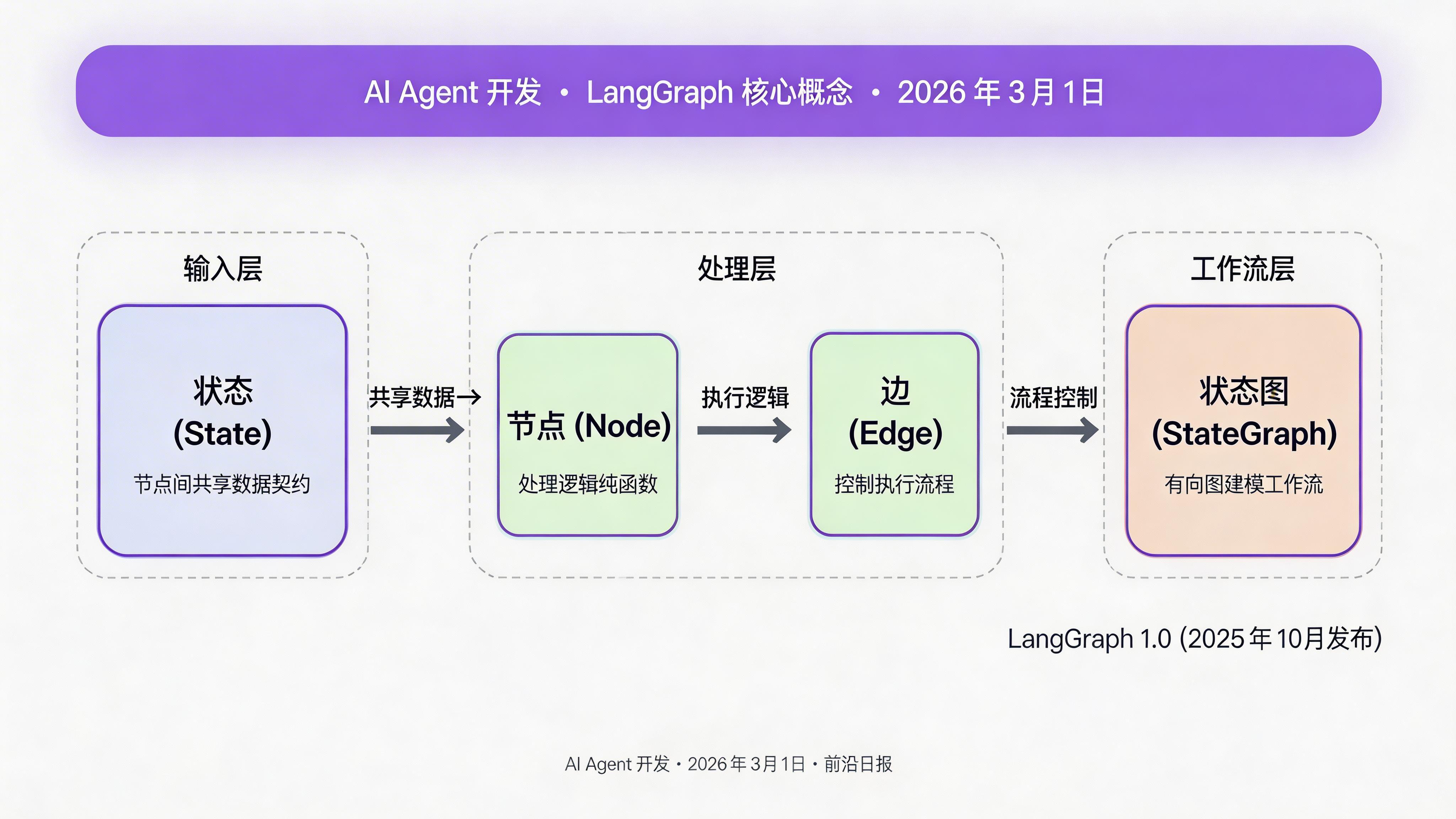
02 定义状态架构 (State Schema)
状态是 LangGraph 的核心抽象。所有节点共享同一个状态对象,节点接收状态、返回更新。我们使用 Python 的 TypedDict 定义状态结构:
from typing import TypedDict, Annotated, List, Literal
import operator
class ResearchState(TypedDict):
# 用户输入的研究主题
query: str
# 累积消息历史(使用 reducer 确保追加而非覆盖)
messages: Annotated[List[str], operator.add]
# 搜索到的来源 URL 列表
sources: Annotated[List[str], operator.add]
# LLM 生成的综合内容
synthesis: str
# 人类审批结果
is_approved: bool
# 错误信息(如果有)
error: str注意 Annotated[List[str], operator.add] 的使用。如果不指定 reducer,状态更新会覆盖原有值;使用 operator.add 可以确保列表被追加。这对于消息历史等累积型字段至关重要。
03 定义节点 (Nodes) —— 纯函数处理逻辑
节点是状态图的处理单元。每个节点是一个纯函数:接收状态字典,返回要更新的字段。节点应该无副作用——不直接修改外部状态,所有变更通过返回值体现。
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o")
def search_node(state: ResearchState) -> dict:
"""搜索网络获取相关资料"""
query = state["query"]
# 实际项目中这里调用搜索 API(如 Tavily、Exa)
sources = [
f"https://example.com/result1?q={query}",
f"https://example.com/result2?q={query}",
]
return {"sources": sources}
def synthesize_node(state: ResearchState) -> dict:
"""使用 LLM 综合搜索结果生成报告"""
context = "\n".join(state["sources"])
prompt = f"基于以下资料综合研究报告:{context}"
response = llm.invoke(prompt)
return {"synthesis": response.content}
def human_review_node(state: ResearchState) -> dict:
"""等待人类审批(实际项目中通过 API 实现)"""
# 这里会触发 interrupt_before 暂停
# 审批后通过 update_state 设置 is_approved
return {"is_approved": state.get("is_approved", False)}04 构建状态图 (StateGraph)
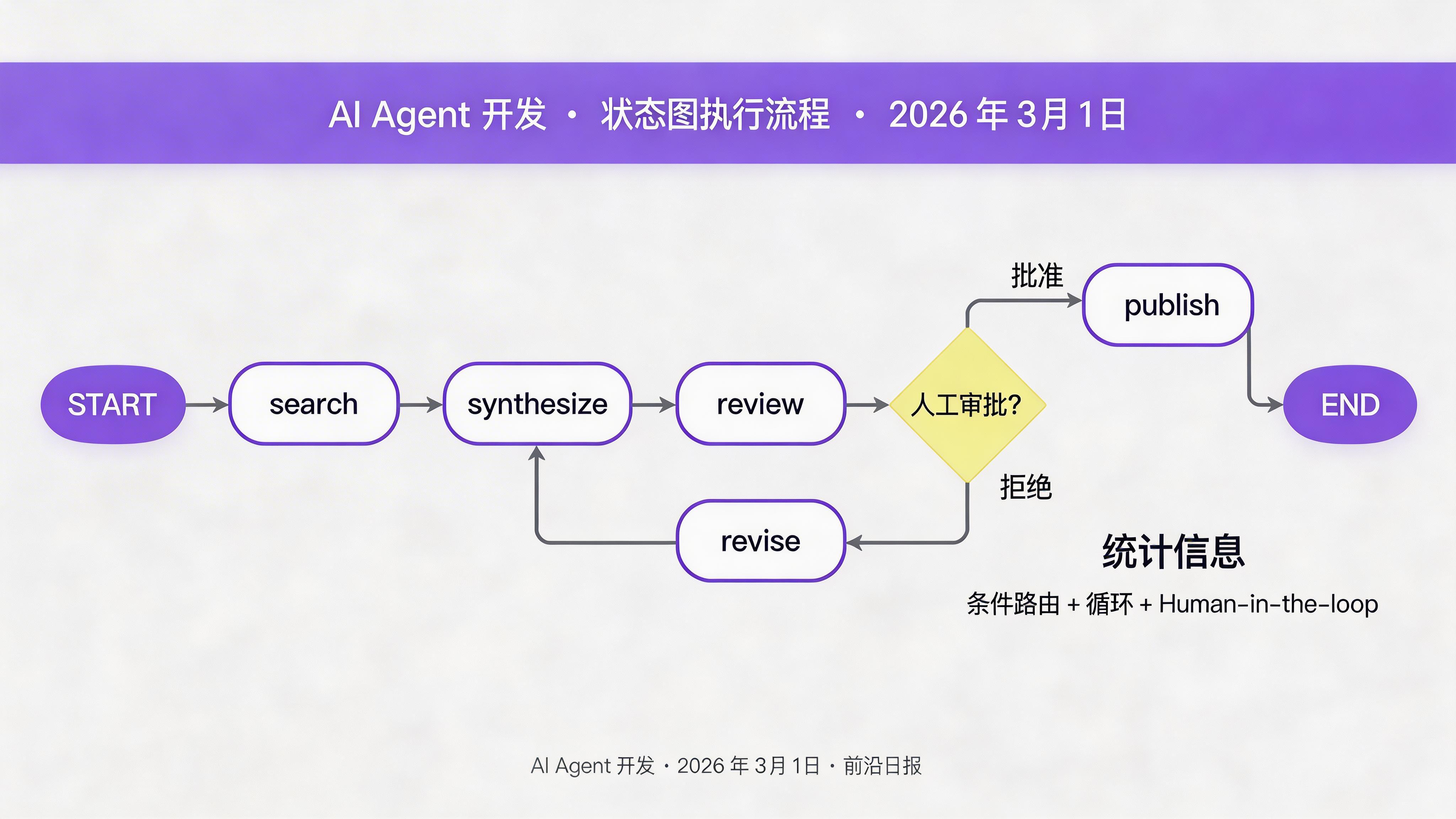
有了状态和节点,现在使用 StateGraph 构建完整的执行流程。关键点在于条件边——它允许根据状态动态决定下一步。
from langgraph.graph import StateGraph, START, END
# 1. 初始化图
builder = StateGraph(ResearchState)
# 2. 添加节点
builder.add_node("search", search_node)
builder.add_node("synthesize", synthesize_node)
builder.add_node("review", human_review_node)
builder.add_node("publish", publish_node)
builder.add_node("revise", revise_node)
# 3. 定义边(固定流程)
builder.add_edge(START, "search")
builder.add_edge("search", "synthesize")
builder.add_edge("synthesize", "review")
# 4. 条件边:根据审批结果决定走向
def route_after_review(state: ResearchState) -> Literal["publish", "revise"]:
if state["is_approved"]:
return "publish"
else:
return "revise"
builder.add_conditional_edges(
"review",
route_after_review,
{"publish": "publish", "revise": "revise"}
)
# 5. 循环:修订后回到综合步骤
builder.add_edge("revise", "synthesize")
builder.add_edge("publish", END)
# 6. 编译(添加持久化)
from langgraph.checkpoint.postgres import PostgresSaver
graph = builder.compile(
checkpointer=PostgresSaver.from_conn_string(
"postgresql://user:pass@localhost:5432/langgraph_demo"
),
interrupt_before=["review"] # 在审批节点前暂停
)
05 执行与 Human-in-the-loop 审批
现在执行工作流。注意 interrupt_before=["review"] 配置——这会让图在执行到 review 节点前自动暂停,等待人类决策。
# 配置线程(用于持久化会话)
config = {"configurable": {"thread_id": "session-001"}}
# 启动工作流
result = graph.invoke({
"query": "2026 年 AI Agent 工作流引擎技术趋势",
"messages": [],
"sources": [],
"synthesis": "",
"is_approved": False,
}, config)
# 检查暂停状态
snapshot = graph.get_state(config)
print(f"下一步执行:{snapshot.next}") # 输出:['review']
# 查看当前状态
current_state = snapshot.values
print(f"已收集来源:{len(current_state['sources'])} 个")暂停后,你可以通过外部系统(Web 界面、Slack 机器人等)展示当前结果,等待用户审批:
# 用户批准后更新状态
graph.update_state(config, {
"is_approved": True,
"messages": ["用户已批准,继续发布"]
})
# 从断点继续执行
final_result = graph.invoke(None, config)Human-in-the-loop 是生产系统的关键特性——在内容发布、资金操作、敏感决策等场景,必须保留人类最终控制权。
06 检查点持久化与故障恢复
LangGraph 的检查点机制会在每个 Super-Step 后自动保存状态到数据库。这意味着:
- 服务器重启后,从最近的检查点恢复
- 用户间隔几天继续对话,历史状态完整保留
- 调试时可以回放任意时间点的状态
# 查看历史检查点
from langgraph.checkpoint.postgres import PostgresSaver
saver = PostgresSaver.from_conn_string(DATABASE_URL)
# 获取某个线程的所有检查点
checkpoints = saver.list({"configurable": {"thread_id": "session-001"}})
for checkpoint in checkpoints:
print(f"时间:{checkpoint['created_at']}")
print(f"状态:{checkpoint['channel_values']}")
print("---")
# 回滚到特定检查点
target_checkpoint = checkpoints[-2] # 倒数第二个
graph.update_state(config, target_checkpoint["channel_values"])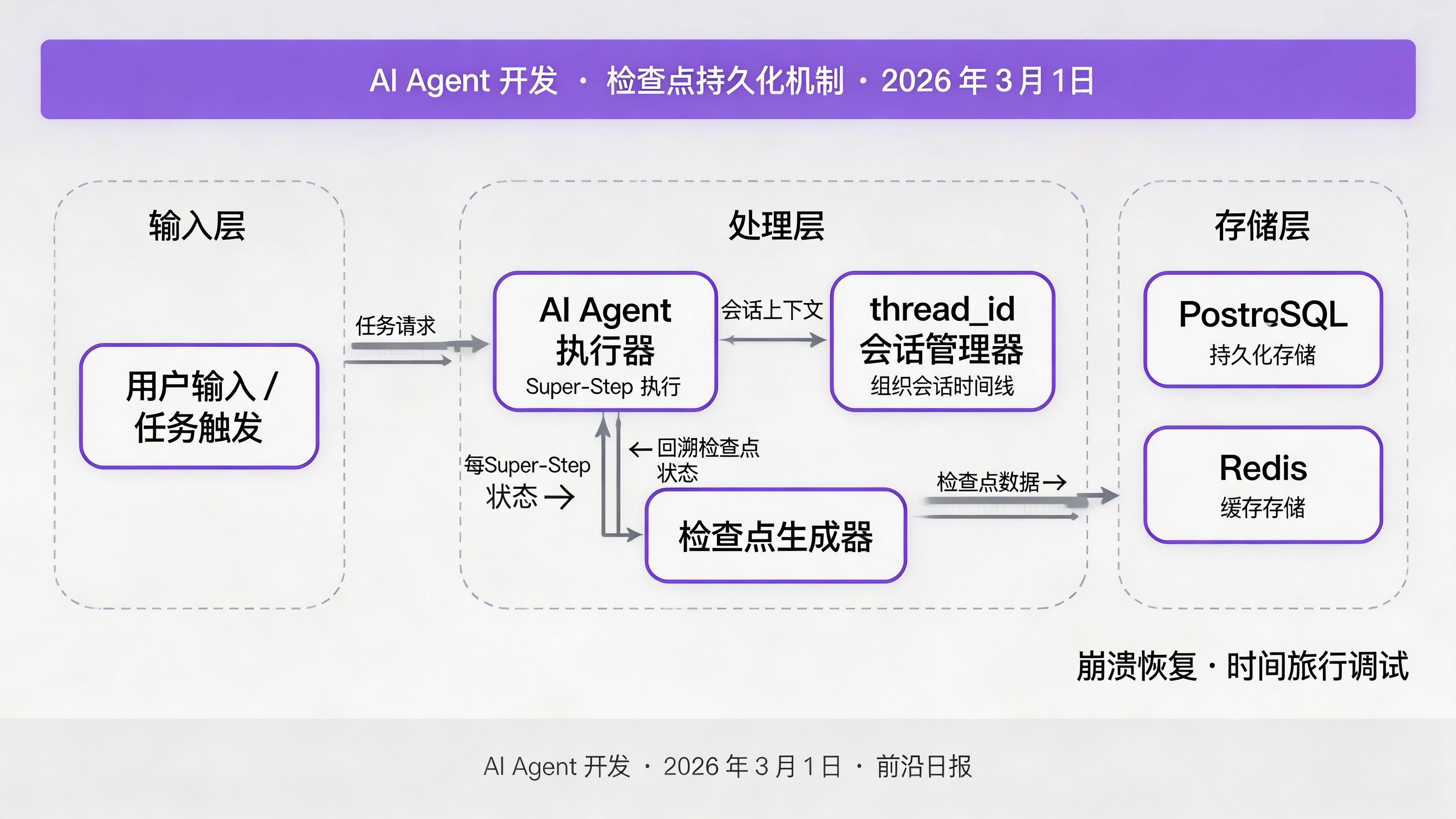
07 可观测性:使用 LangGraph Studio 调试
LangGraph Studio 是官方可视化工具,可以实时查看状态图的执行过程:
# 安装 LangGraph Studio
pip install langgraph-cli
# 启动开发服务器
langgraph dev
# 在浏览器打开 http://localhost:8123Studio 提供以下能力:
- 可视化执行轨迹:看到状态如何在节点间流转
- 状态检查:点击任意节点查看当时的状态值
- 时间旅行调试:回放到历史检查点重新执行
- 人工审批界面:直接在 UI 中批准或拒绝
08 生产模式:错误处理与优化
最后,补充生产环境必备的错误处理和优化策略:
import logging
from tenacity import retry, stop_after_attempt, wait_exponential
logger = logging.getLogger(__name__)
# 重试装饰器
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10)
)
def search_with_retry(query: str):
return search_api(query)
# 在节点内捕获异常
def safe_search_node(state: ResearchState) -> dict:
try:
sources = search_with_retry(state["query"])
return {"sources": sources}
except Exception as e:
logger.error(f"搜索失败:{e}")
return {"error": str(e)}
# 设置最大迭代次数防止无限循环
graph = builder.compile(
checkpointer=saver,
interrupt_before=["review"]
)
# 执行时限制最大步数
result = graph.invoke(
input_data,
config,
stream_mode="updates", # 流式输出中间状态
recursion_limit=25 # 防止无限循环
)曾有团队的生产系统因条件边逻辑错误陷入无限循环,11 天内消耗了 $47,000 的 API 费用。务必设置 recursion_limit 并监控执行步数。
FAQ 常见问题解答
CrewAI 采用基于角色的抽象(Agent 有 Role/Goal/Backstory),适合快速原型和多 Agent 协作场景。LangGraph 采用更底层的状态图抽象,提供精确的流程控制和持久化能力,适合生产环境的关键业务系统。简单说:CrewAI 像"乐高积木",LangGraph 像"电路板"。
LangGraph 支持多种检查点后端:PostgreSQL(生产推荐)、Redis(低延迟场景)、SQLite(开发测试)。你也可以实现自定义的 BaseCheckpointSaver 对接其他存储系统。
使用 LangGraph 1.0 新增的 Send API 实现动态 Fan-Out。例如同时搜索多个子主题,然后聚合结果。具体可以参考官方文档的"Parallel Execution"章节。
如果你的工作流只有 2-3 个简单步骤,使用 LangChain 的线性链就足够了。LangGraph 的价值体现在:5+ 步骤、需要条件分支、需要人类审批、需要故障恢复的复杂场景。