图解 Transformer 注意力机制
从 Self-Attention 到 Multi-Head
通过可视化图解和 PyTorch 代码实战,深入理解 Transformer 注意力机制的核心原理。掌握 Q/K/V 矩阵计算、Multi-Head 设计动机,以及 2026 年最新高效注意力变体。
当你阅读这段文字时,你的大脑并不会平等地处理每个字——你会自然地将注意力集中在关键信息上。这正是注意力机制的核心直觉。2017 年,《Attention Is All You Need》论文彻底改变了深度学习,而今天,注意力机制已成为大语言模型的基石。
本教程你将学到
- Self-Attention 的 Q/K/V 矩阵计算与数学直觉
- Multi-Head Attention 的设计动机与并行计算优势
- 如何用 PyTorch 从零实现注意力机制
- 注意力权重的可视化方法与调试技巧
- 2026 年最新高效注意力变体(FlashAttention、GQA)
理解注意力的直觉:从人类认知到数学公式
想象你在阅读这句话:"The pizza came out of the oven and it tasted good."当你的大脑处理代词"it"时,会自动将它与"pizza"而非"oven"建立联系——这种动态关联上下文的能力就是注意力的本质。
在传统 RNN 中,信息必须按顺序传递,就像接力赛一样,这不仅效率低下,还容易导致长距离依赖的丢失。而注意力机制允许模型直接跨越任意距离建立连接,实现了真正的并行计算。

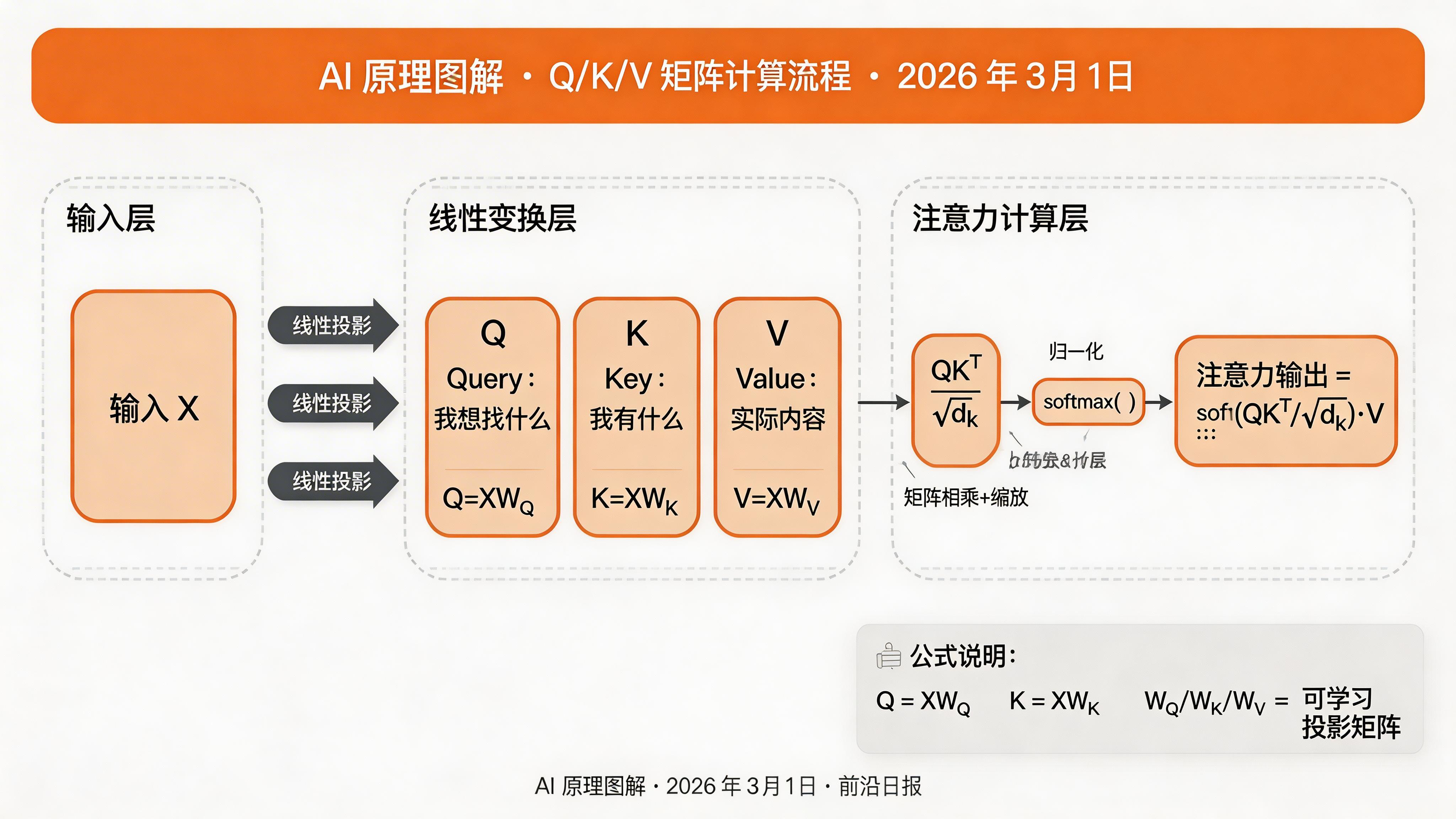
注意力机制的数学表达出奇地优雅:给定一个查询(Query)和一组键值对(Key-Value pairs),注意力输出是值的加权和,权重由查询与对应键的相似度决定。
Q/K/V 三要素:注意力机制的核心组件
Self-Attention 的核心是将输入转换为三个向量:Query(查询)、Key(键)、Value(值)。这个设计灵感来源于信息检索系统——当你搜索信息时,你提供一个查询(Query),系统用它匹配数据库中的键(Key),找到匹配后返回对应的值(Value)。
| 向量 | 符号 | 维度 | 物理含义 |
|---|---|---|---|
| Query | Q | (seq_len, d_k) | 查询向量,表示"我想找什么" |
| Key | K | (seq_len, d_k) | 键向量,表示"我有什么信息" |
| Value | V | (seq_len, d_v) | 值向量,表示"实际的内容" |
注意力公式如下:
Attention(Q, K, V) = softmax(QK^T / √d_k) · V其中 Q = XW_Q,K = XW_K,V = XW_V,W_Q、W_K、W_V 是可学习的投影矩阵。
缩放点积注意力:为什么需要除以 √d_k?
当你第一次看到公式中的 / √d_k 时,可能会疑惑:这个缩放因子是做什么的?答案关乎数值稳定性。
当 d_k 较大时,QK^T 的点积结果会变得很大。考虑极端情况:两个 512 维向量的点积可能在 [-512, 512] 范围内。当这个值输入 softmax 函数时,会导致梯度消失——softmax 在输入值很大或很小时会变得非常"平坦",梯度接近于零。
import torch
import torch.nn as nn
import math
class ScaledDotProductAttention(nn.Module):
def __init__(self, dropout=0.1):
super().__init__()
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, mask=None):
d_k = query.size(-1)
# 1. 计算相似度分数 QK^T
scores = torch.matmul(query, key.transpose(-2, -1))
# 2. 缩放:防止点积过大导致 softmax 梯度消失
scaled_scores = scores / math.sqrt(d_k)
# 3. Mask(用于 decoder 或 padding)
if mask is not None:
scaled_scores = scaled_scores.masked_fill(mask == 0, -1e9)
# 4. Softmax 归一化得到注意力权重
attention_weights = torch.softmax(scaled_scores, dim=-1)
attention_weights = self.dropout(attention_weights)
# 5. 加权求和
output = torch.matmul(attention_weights, value)
return output, attention_weights
Multi-Head Attention:多个视角同时学习
Single-Head 注意力已经能工作了,但为什么 Transformer 要使用 Multi-Head?答案是:让模型在多个不同的子空间中同时学习注意力。
不同的"注意力头"可能关注不同类型的信息:头 1 可能关注语法结构(主谓关系),头 2 可能关注语义关联(代词指代),头 3 可能关注位置关系(相邻词)。
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout=0.1):
super().__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
# 合并 QKV 投影以提高效率
self.qkv_proj = nn.Linear(d_model, 3 * d_model)
self.output_proj = nn.Linear(d_model, d_model)
self.attention = ScaledDotProductAttention(dropout)
def forward(self, x, mask=None):
batch_size, seq_len, _ = x.shape
# 生成 QKV 并 reshape 为多头格式
qkv = self.qkv_proj(x).view(batch_size, seq_len, 3, self.num_heads, self.head_dim)
qkv = qkv.permute(2, 0, 3, 1, 4)
query, key, value = qkv[0], qkv[1], qkv[2]
# Self-Attention(每个头并行计算)
attn_output, attn_weights = self.attention(query, key, value, mask)
# 合并头并输出
attn_output = attn_output.transpose(1, 2).reshape(batch_size, seq_len, self.d_model)
return self.output_proj(attn_output), attn_weights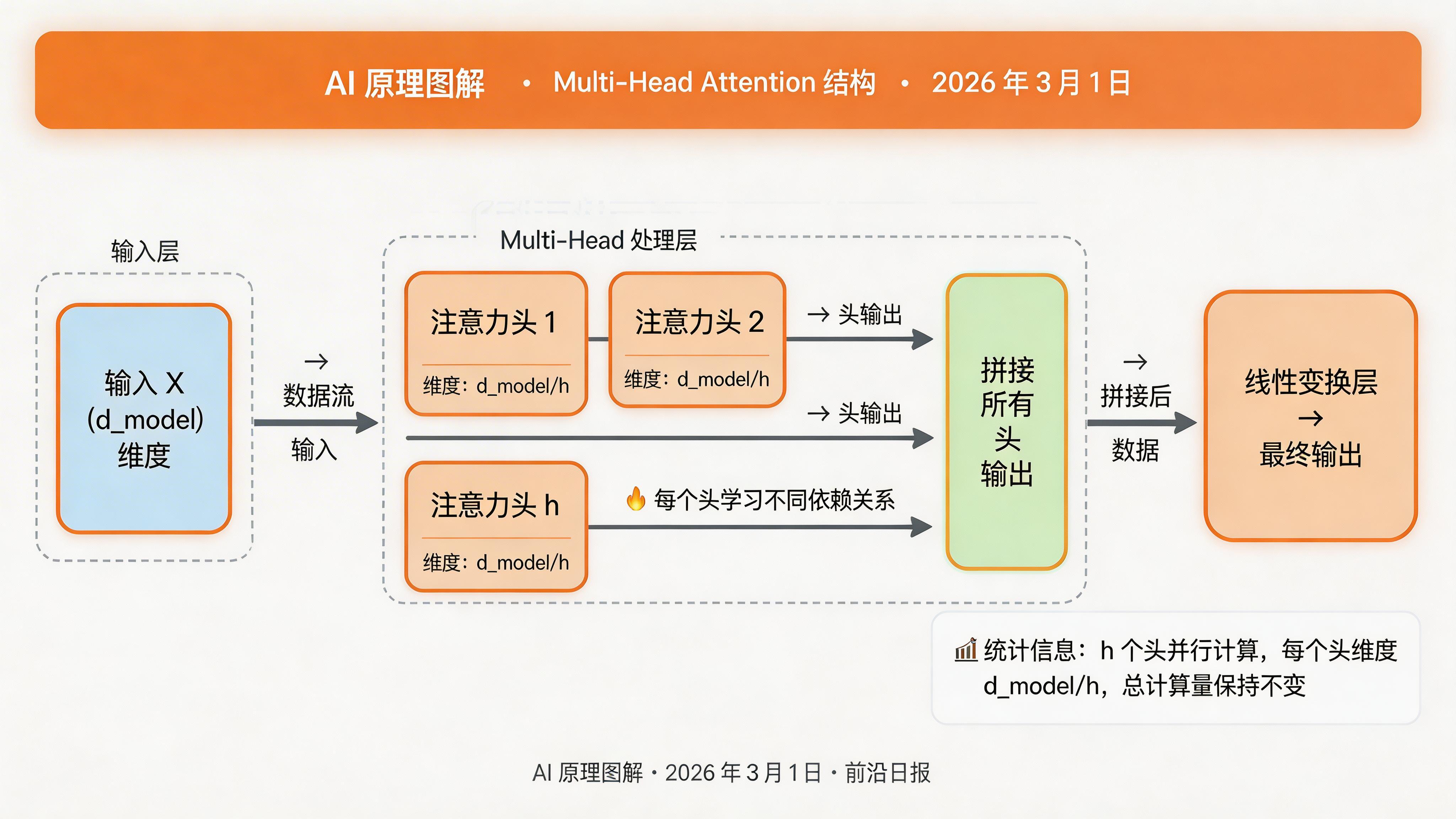
注意力权重可视化:看见模型的"注意力"
注意力权重是一个矩阵,shape 为 (seq_len, seq_len),每个元素表示某个 token 对另一个 token 的关注程度。可视化这个矩阵,我们就能"看见"模型在关注什么。
import matplotlib.pyplot as plt
import seaborn as sns
def plot_attention_heatmap(attention_weights, tokens, head_idx=0, layer_idx=0):
# 提取特定层和头的注意力权重
attn = attention_weights[layer_idx][0][head_idx].cpu().numpy()
plt.figure(figsize=(10, 8))
sns.heatmap(attn, xticklabels=tokens, yticklabels=tokens, cmap='YlOrRd')
plt.title(f"Layer {layer_idx}, Head {head_idx}")
plt.xlabel("Keys"); plt.ylabel("Queries")
plt.savefig(f"attention_l{layer_idx}_h{head_idx}.png", dpi=150)
plt.show()
常见的注意力模式:对角线模式(自注意力)、垂直线模式(某些 token 被全局关注)、块状模式(短语内部注意力)、长距离模式(跨句子依赖)。
2026 年高效注意力变体:FlashAttention 与 GQA
标准注意力(MHA)的 KV Cache 大小为 O(h·n·d),对于长序列和大头数会消耗大量内存。2026 年,两种优化成为主流:
| 变体 | 全称 | KV Cache | 质量 | 适用场景 |
|---|---|---|---|---|
| MHA | Multi-Head Attention | O(h·n·d) | 100% | 训练、高质量推理 |
| MQA | Multi-Query Attention | O(n·d) | ~85% | 高吞吐推理 |
| GQA | Grouped-Query Attention | O(g·n·d) | ~95% | Llama 3、Mistral |
| FlashAttn | IO-Aware Attention | 同 MHA | 100% + 更快 | 训练和推理加速 |
GQA(Grouped-Query Attention) 是 Llama 3 的标准配置:32 个 Query 头共享 8 个 KV 头,在保持质量的同时减少 4 倍 KV Cache。
FlashAttention-3 针对 H100/H200 优化,通过 Tiling 分块、Kernel Fusion 内核融合、Recomputation 重计算,实现 7-10 倍速度提升。
# 使用 FlashAttention-2/3
from flash_attn import flash_attn_func
output = flash_attn_func(q, k, v, dropout_p=0.0, causal=True)
# PyTorch 2.0+ SDPA(自动选择最优后端)
import torch.nn.functional as F
output = F.scaled_dot_product_attention(q, k, v, is_causal=True)常见问题 FAQ
核心收获
- Self-Attention 通过 Q/K/V 矩阵实现动态上下文关联,公式为 softmax(QK^T/√d_k)V
- Multi-Head 让模型在多个子空间并行学习注意力,增强表达能力
- 缩放因子 √d_k 防止点积过大导致 softmax 梯度消失
- 注意力权重可视化可以"看见"模型的关注模式
- GQA 和 FlashAttention 是 2026 年主流高效注意力变体
立即开始实践
打开 PyTorch,从零实现一个 Multi-Head Attention 层,用 BertViz 可视化工具观察注意力权重。动手写一遍代码,比读十篇教程都有效。