为什么你的 Agent 总是"健忘"?
你有没有遇到过这样的场景:用户花了几分钟描述自己的需求和偏好,第二天回来时,Agent 却像失忆了一样,一切从头开始?或者用户反复强调自己是 Python 开发者,Agent 却还是给出 JavaScript 示例代码?
这不是 Agent 不够"聪明",而是缺少了关键的基础设施——记忆系统。
🔴 无状态 LLM 的根本限制
LLM 被设计为在有界上下文窗口内推理——GPT-4 只有 8K-128K tokens,Claude 3.5 Sonnet 是 200K tokens。窗口之外的一切对模型而言都不存在。真正的問題不是"模型有多聪明",而是"系统如何智能地管理模型能看到的内容"。
🟡 传统 RAG 的三大局限
RAG 只能检索相似片段,但无法理解事件之间的因果关系、时间序列和用户意图的演进。它回答"什么相似",但回答不了"为什么发生"和"接下来该做什么"。
本教程你将学会
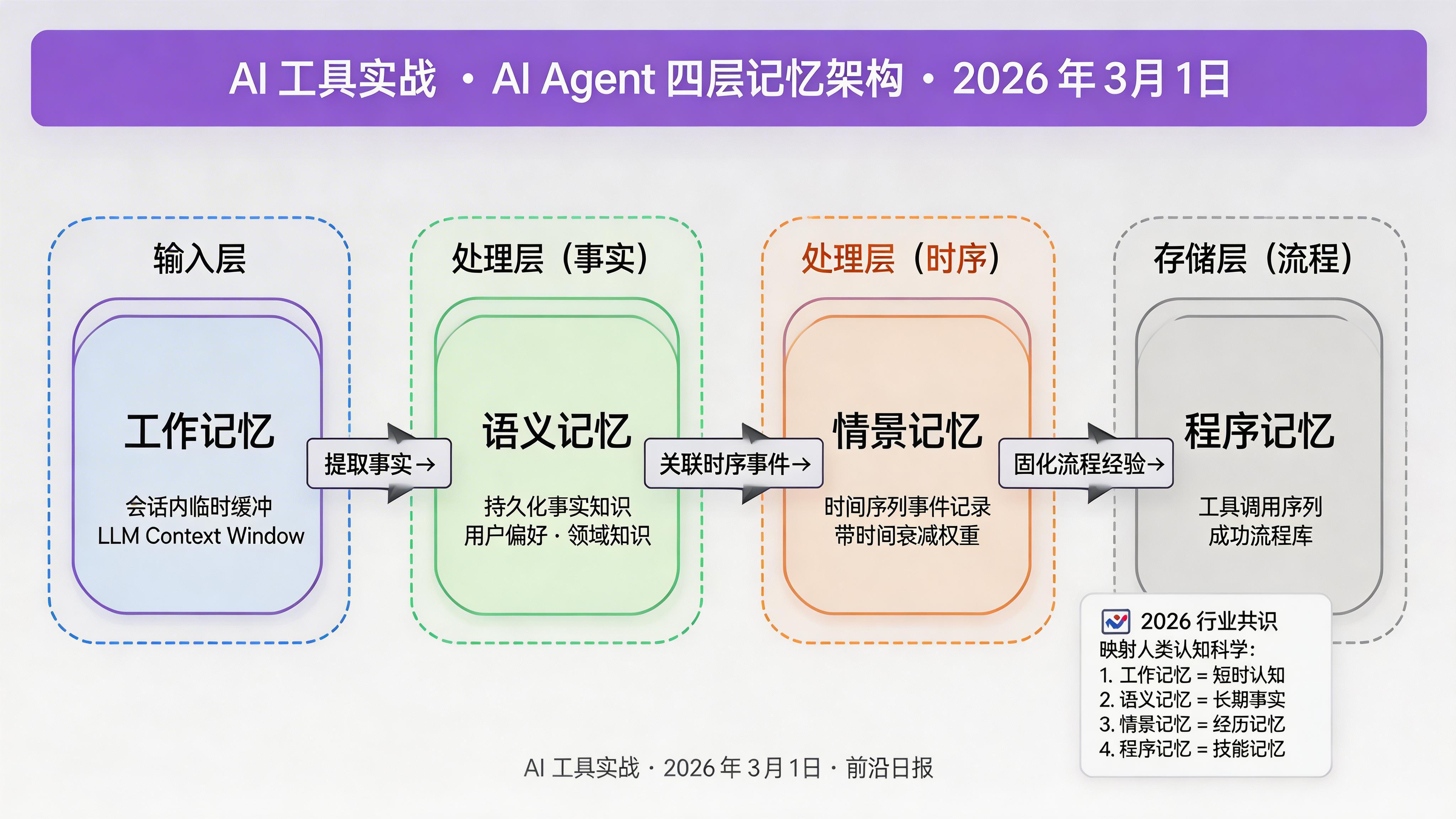
📐 四层记忆架构设计
掌握 2026 年行业共识的记忆类型:工作记忆、语义记忆、情景记忆、程序记忆,以及它们的实现模式。
🗄️ 向量数据库选型实战
深入对比 Chroma、Qdrant、Pinecone、pgvector 等主流方案,理解 HNSW 索引原理和性能优化技巧。
🔄 LangGraph 持久化实现
使用 LangGraph Checkpoint 构建跨会话的状态持久化系统,让 Agent 记住长期目标和用户偏好。
📊 Graph Memory 新范式
解析 2026 年 2 月最新论文成果,理解图结构记忆如何超越传统向量检索,实现关系推理。
在开始编码之前,我们需要建立一个关键认知:记忆不是 LLM 的功能特性,而是 Agent 架构的设计原语。这意味着记忆不应该事后添加,而应该在系统设计之初就作为核心组件来考虑。
2026 年四层记忆架构
根据新加坡国立大学、Renmin 大学等机构的联合研究,AI Agent 记忆已收敛为四种类型,这一分类直接映射人类认知科学:
各类型记忆的技术特征
工作记忆(Working Memory)
生命周期:单次会话
存储介质:LLM 上下文 token
容量限制:4K-2M tokens
优化策略:滑动窗口、摘要压缩、选择性保留
语义记忆(Semantic Memory)
生命周期:持久化,跨会话
存储介质:向量数据库 + 知识图谱
访问模式:语义相似度搜索
内容类型:用户偏好、领域知识、事实数据
情景记忆(Episodic Memory)
生命周期:持久化,带时间戳
存储介质:时序数据库 + 向量索引
访问模式:时间范围查询 + 语义检索
关键设计:时间衰减权重、定期压缩
程序记忆(Procedural Memory)
生命周期:持久化,可更新
存储介质:代码库 + 工具注册表
访问模式:模式匹配 + 执行历史
内容类型:工具函数、API 调用序列、调试策略
理解这四种记忆类型的区别和联系,是设计有效记忆系统的前提。接下来,我们将逐一实现它们。
向量数据库是语义记忆和情景记忆的核心存储引擎。它的质量直接决定了记忆检索的准确性和响应速度。2026 年,市面上已有超过 20 种向量数据库方案,我们聚焦最主流的六种进行深度对比。
HNSW 算法:高性能相似度搜索的核心
在深入具体产品之前,先理解 HNSW(Hierarchical Navigable Small World)算法——这是绝大多数向量数据库的索引基础。HNSW 通过构建多层图结构,在保持高精度的同时实现亚毫秒级检索。
import hnswlib
import numpy as np
import time
p = hnswlib.Index(space='cosine', dim=1536)
p.init_index(max_elements=1000000, ef_construction=200, M=16)
data = np.random.rand(1000000, 1536).astype('float32')
p.add_items(data, range(1000000))
p.set_ef(50)
query = np.random.rand(1, 1536).astype('float32')
start = time.time()
labels, distances = p.knn_query(query, k=10)
print(f"P99 延迟:{(time.time()-start)*1000:.2f}ms")
关键参数调优建议:
M=16:每个节点的最大连接数,增大提高精度但增加内存ef_construction=200:构建时的搜索深度,推荐值 200-400ef=50:查询时的搜索深度,根据延迟要求调整
六大向量数据库对比
| 方案 |
类型 |
优势 |
局限 |
| Chroma |
嵌入式 |
开发者友好,纯 Python |
单节点,不适合高并发 |
| Qdrant |
独立服务 |
Rust 实现,性能优秀,支持混合搜索 |
需要独立部署 |
| Pinecone |
全托管 |
零运维,自动扩展 |
成本高,闭源 |
| Weaviate |
独立服务 |
支持向量 + 关键词混合搜索 |
内存占用高 |
| pgvector |
PostgreSQL 扩展 |
与现有数据库无缝集成 |
性能弱于专用方案 |
| SochDB |
AI 原生 |
内置 Context Query Builder,Token 优化 |
2026 年新品,生态待成熟 |
现在进入实战环节。我们将使用 Python 构建一个完整的分层记忆系统,包含所有四种记忆类型的实现。
环境准备
langgraph>=0.2.0
chromadb>=0.5.0
openai>=1.12.0
numpy>=1.24.0
tiktoken>=0.5.0
pydantic>=2.0.0
Memory Controller 核心实现
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from typing import List, Dict, Optional, Any
from enum import Enum
import chromadb
import numpy as np
import tiktoken
class MemoryType(Enum):
WORKING = "working"
SEMANTIC = "semantic"
EPISODIC = "episodic"
PROCEDURAL = "procedural"
@dataclass
class Memory:
"""记忆单元基类"""
id: str
content: str
created_at: datetime = field(default_factory=datetime.utcnow)
importance: float = 0.5
access_count: int = 0
metadata: Dict[str, Any] = field(default_factory=dict)
@dataclass
class EpisodicMemory(Memory):
"""情景记忆:带时间戳的事件记录"""
event_type: str = "conversation"
participants: List[str] = field(default_factory=list)
outcome: Optional[str] = None
class MemoryController:
"""分层记忆系统控制器"""
def __init__(
self,
embedding_model: str = "text-embedding-3-small",
chroma_path: str = "./chroma_db",
token_budget: int = 4000
):
self.token_budget = token_budget
self.encoding = tiktoken.encoding_for_model("gpt-4")
self.chroma_client = chromadb.PersistentClient(path=chroma_path)
self.semantic_collection = self.chroma_client.get_or_create_collection(
name="semantic_memory",
metadata={"hnsw:space": "cosine"}
)
self.episodic_collection = self.chroma_client.get_or_create_collection(
name="episodic_memory",
metadata={"hnsw:space": "cosine"}
)
self.working_memory: List[Memory] = []
self.procedural_memory: Dict[str, List[str]] = {}
self._embedding_cache: Dict[str, List[float]] = {}
def _get_embedding(self, text: str) -> List[float]:
"""获取文本的 embedding 向量(带缓存)"""
if text in self._embedding_cache:
return self._embedding_cache[text]
embedding = np.random.randn(1536).tolist()
self._embedding_cache[text] = embedding
return embedding
def _count_tokens(self, text: str) -> int:
"""计算 token 数量"""
return len(self.encoding.encode(text))
def add_semantic_memory(
self,
content: str,
category: str,
metadata: Optional[Dict] = None
) -> str:
"""添加语义记忆(事实知识)"""
memory_id = f"sem_{datetime.utcnow().timestamp()}"
embedding = self._get_embedding(content)
full_metadata = {
"category": category,
"created_at": datetime.utcnow().isoformat(),
**(metadata or {})
}
self.semantic_collection.upsert(
ids=[memory_id],
embeddings=[embedding],
metadatas=[full_metadata],
documents=[content]
)
return memory_id
def add_episodic_memory(
self,
content: str,
event_type: str = "conversation",
participants: Optional[List[str]] = None,
outcome: Optional[str] = None
) -> str:
"""添加情景记忆(事件记录)"""
memory_id = f"epi_{datetime.utcnow().timestamp()}"
embedding = self._get_embedding(content)
full_metadata = {
"event_type": event_type,
"created_at": datetime.utcnow().isoformat(),
"participants": ",".join(participants or []),
"outcome": outcome or ""
}
self.episodic_collection.upsert(
ids=[memory_id],
embeddings=[embedding],
metadatas=[full_metadata],
documents=[content]
)
return memory_id
def retrieve_semantic(
self,
query: str,
top_k: int = 5,
category_filter: Optional[str] = None
) -> List[Dict]:
"""检索语义记忆"""
query_embedding = self._get_embedding(query)
where_clause = None
if category_filter:
where_clause = {"category": category_filter}
results = self.semantic_collection.query(
query_embeddings=[query_embedding],
n_results=top_k,
where=where_clause,
include=["documents", "metadatas", "distances"]
)
return [
{
"id": results["ids"][0][i],
"content": results["documents"][0][i],
"metadata": results["metadatas"][0][i],
"distance": results["distances"][0][i]
}
for i in range(len(results["ids"][0]))
]
def retrieve_episodic(
self,
query: str,
top_k: int = 5,
time_range: Optional[tuple] = None,
apply_time_decay: bool = True
) -> List[Dict]:
"""检索情景记忆(支持时间范围过滤和时间衰减)"""
query_embedding = self._get_embedding(query)
results = self.episodic_collection.query(
query_embeddings=[query_embedding],
n_results=top_k * 2,
include=["documents", "metadatas", "distances"]
)
memories = []
now = datetime.utcnow()
for i in range(len(results["ids"][0])):
metadata = results["metadatas"][0][i]
created_at = datetime.fromisoformat(metadata["created_at"])
if time_range:
start, end = time_range
if not (start <= created_at <= end):
continue
memory = {
"id": results["ids"][0][i],
"content": results["documents"][0][i],
"metadata": metadata,
"distance": results["distances"][0][i],
"created_at": created_at
}
if apply_time_decay:
age_hours = (now - created_at).total_seconds() / 3600
decay_factor = np.exp(-age_hours / 24)
memory["score"] = (1 - memory["distance"]) * decay_factor
else:
memory["score"] = 1 - memory["distance"]
memories.append(memory)
memories.sort(key=lambda x: x["score"], reverse=True)
return memories[:top_k]
def build_context(
self,
query: str,
semantic_top_k: int = 3,
episodic_top_k: int = 3,
max_tokens: Optional[int] = None
) -> str:
"""构建 LLM 上下文(自动在 token 预算内优化)"""
max_tokens = max_tokens or self.token_budget
semantic_memories = self.retrieve_semantic(query, top_k=semantic_top_k)
episodic_memories = self.retrieve_episodic(query, top_k=episodic_top_k)
context_parts = []
current_tokens = 0
for memory in semantic_memories:
content = f"[知识库] {memory['content']}"
tokens = self._count_tokens(content)
if current_tokens + tokens <= max_tokens * 0.5:
context_parts.append(content)
current_tokens += tokens
for memory in episodic_memories:
content = f"[历史记录] {memory['content']}"
tokens = self._count_tokens(content)
if current_tokens + tokens <= max_tokens:
context_parts.append(content)
current_tokens += tokens
return "\n\n".join(context_parts)
def consolidate_old_memories(
self,
days_threshold: int = 7,
summary_model: str = "gpt-4o-mini"
):
"""压缩旧情景记忆为语义摘要(定期执行)"""
cutoff = datetime.utcnow() - timedelta(days=days_threshold)
old_memories = self.retrieve_episodic(
query="",
top_k=100,
time_range=(datetime.min, cutoff),
apply_time_decay=False
)
if len(old_memories) < 5:
return
summary = f"压缩 {len(old_memories)} 条旧记忆为语义知识"
self.add_semantic_memory(
content=summary,
category="consolidated_summary",
metadata={"source_count": len(old_memories)}
)
for memory in old_memories:
self.episodic_collection.delete(ids=[memory["id"]])
上述代码实现了完整的分层记忆系统。关键设计点:
- 分离存储:语义和情景记忆分别存储在 ChromaDB 的两个 Collection 中,便于针对性优化
- 时间衰减:情景记忆检索时应用 24 小时半衰期的指数衰减,近期事件权重更高
- Token 预算:
build_context() 方法自动在 token 限制内优化记忆选择
- 定期压缩:
consolidate_old_memories() 将旧事件压缩为语义摘要,释放存储空间
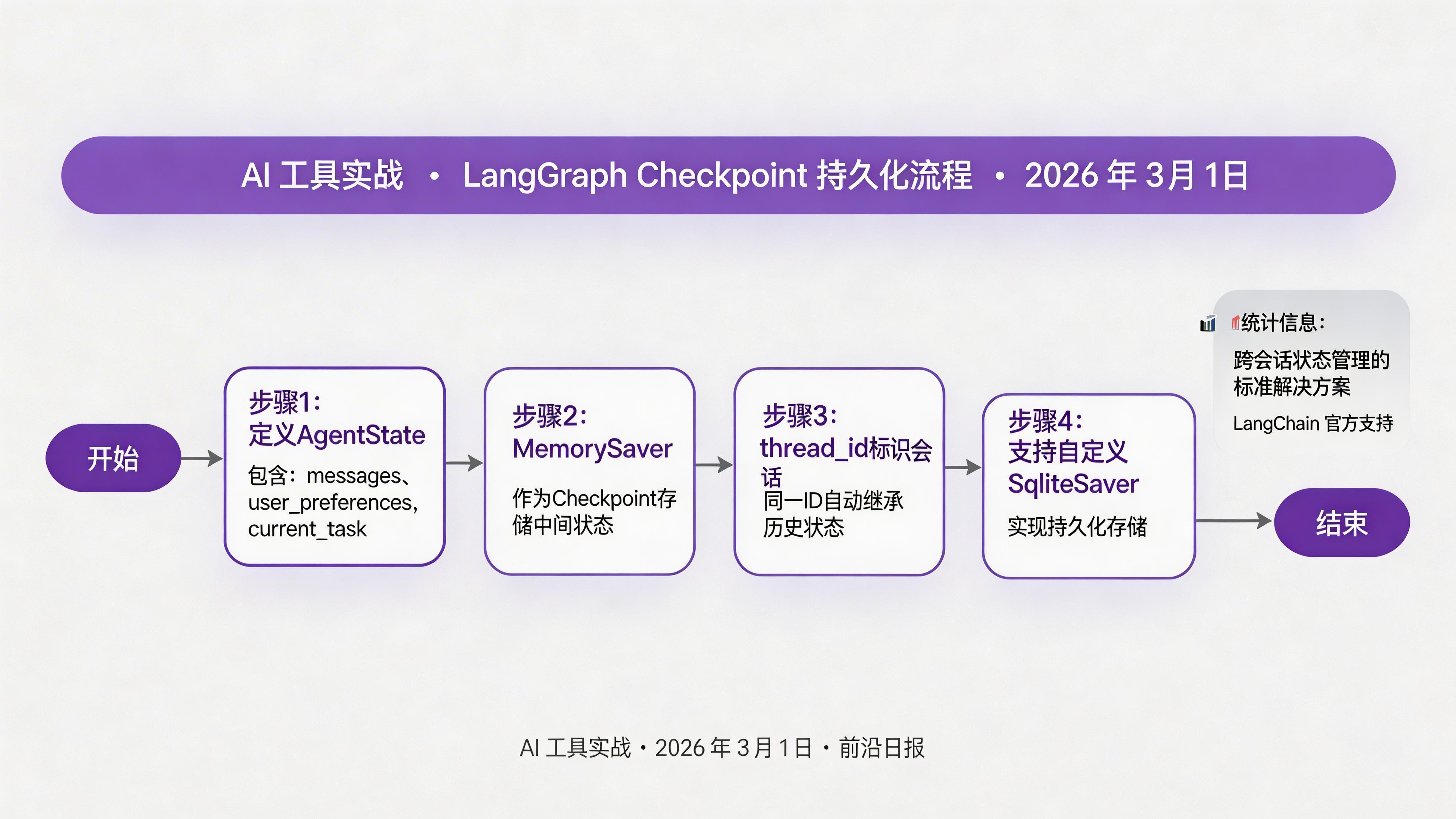
LangGraph 是 LangChain 团队推出的图原生 Agent 编排框架,其 Checkpoint 机制为跨会话状态持久化提供了开箱即用的解决方案。
Checkpoint 基础使用
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
from typing import TypedDict, Annotated
import operator
class AgentState(TypedDict):
"""定义 Agent 状态"""
messages: Annotated[List[str], operator.add]
user_preferences: Dict[str, Any]
current_task: str
memory = MemorySaver()
builder = StateGraph(AgentState)
def process_node(state: AgentState):
"""处理节点"""
return {"messages": ["处理完成"]}
builder.add_node("processor", process_node)
builder.add_edge(START, "processor")
builder.add_edge("processor", END)
graph = builder.compile(checkpointer=memory)
config = {"configurable": {"thread_id": "user_123"}}
result1 = graph.invoke({
"messages": [],
"user_preferences": {"language": "Python"},
"current_task": "build_agent"
}, config)
result2 = graph.invoke({
"messages": ["继续执行"],
"user_preferences": {},
"current_task": "test_agent"
}, config)
自定义 Checkpoint 实现
MemorySaver 仅在内存中存储状态,进程重启后数据丢失。生产环境需要使用持久化存储。下面是使用 SQLite 的自定义实现:
from langgraph.checkpoint.base import (
BaseCheckpointSaver,
Checkpoint,
CheckpointMetadata,
SerializerProtocol
)
from langgraph.serde.jsonplus import JsonPlusSerializer
import sqlite3
import json
class SqliteSaver(BaseCheckpointSaver):
"""SQLite 持久化 Checkpoint 实现"""
serializer: SerializerProtocol = field(default_factory=JsonPlusSerializer)
def __init__(self, db_path: str):
self.conn = sqlite3.connect(db_path)
self._setup_tables()
def _setup_tables(self):
"""创建数据表"""
self.conn.execute("""
CREATE TABLE IF NOT EXISTS checkpoints (
thread_id TEXT PRIMARY KEY,
checkpoint_id TEXT,
checkpoint BLOB,
metadata BLOB,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
self.conn.commit()
def get_tuple(self, config: Dict) -> Optional[tuple]:
"""获取 checkpoint"""
thread_id = config["configurable"]["thread_id"]
cursor = self.conn.execute(
"SELECT checkpoint_id, checkpoint, metadata FROM checkpoints WHERE thread_id = ?",
(thread_id,)
)
row = cursor.fetchone()
if not row:
return None
return (
row[0],
self.serializer.loads(row[1]),
self.serializer.loads(row[2])
)
def put(
self,
config: Dict,
checkpoint: Checkpoint,
metadata: CheckpointMetadata
) -> Dict:
"""保存 checkpoint"""
thread_id = config["configurable"]["thread_id"]
checkpoint_id = checkpoint["id"]
self.conn.execute(
"""
INSERT OR REPLACE INTO checkpoints
(thread_id, checkpoint_id, checkpoint, metadata)
VALUES (?, ?, ?, ?)
""",
(
thread_id,
checkpoint_id,
self.serializer.dumps(checkpoint),
self.serializer.dumps(metadata)
)
)
self.conn.commit()
return {"configurable": {"thread_id": thread_id}}
2026 年 2 月,新加坡国立大学等机构联合发布了 Graph Memory 论文,提出了一种超越传统向量检索的记忆架构。Graph Memory 通过图结构存储实体和关系,支持多跳推理和时间感知查询。
为什么需要图结构记忆?
向量检索的本质是相似度匹配,它无法回答需要推理的问题:
- "用户上周提到的那个项目最后进展如何?"(需要时间序列 + 状态追踪)
- "张三是李四的什么关系?"(需要关系推理)
- "这个项目涉及哪些技术栈?"(需要实体 - 属性关联)
使用 Neo4j 实现 Graph Memory
from neo4j import GraphDatabase
class GraphMemory:
"""基于 Neo4j 的图记忆系统"""
def __init__(self, uri: str, user: str, password: str):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def close(self):
self.driver.close()
def add_entity(self, entity_id: str, entity_type: str, properties: Dict):
"""添加实体节点"""
with self.driver.session() as session:
props_str = ", ".join(f"{k}: $props.{k}" for k in properties.keys())
query = f"""
MERGE (e:{entity_type} {{id: $id}})
SET e += $props
RETURN e
"""
session.run(query, id=entity_id, props=properties)
def add_relation(
self,
from_entity: str,
relation: str,
to_entity: str,
properties: Optional[Dict] = None
):
"""添加关系边"""
with self.driver.session() as session:
props_set = f"SET r += $props" if properties else ""
query = f"""
MATCH (a), (b)
WHERE a.id = $from AND b.id = $to
MERGE (a)-[r:{relation}]->(b)
{props_set}
RETURN r
"""
session.run(query, from=from_entity, to=to_entity, props=properties or {})
def query_path(
self,
start_entity: str,
end_entity: str,
max_hops: int = 3
) -> List[Dict]:
"""查询两个实体之间的路径(多跳推理)"""
with self.driver.session() as session:
query = """
MATCH path = shortestPath(
(start {id: $start})-[*..max_hops]-(end {id: $end})
)
RETURN path
"""
result = session.run(query, start=start_entity, end=end_entity, max_hops=max_hops)
return list(result)
Graph Memory vs 向量记忆对比:
向量记忆
优势:实现简单、检索快速、语义相似度准确
局限:无法推理关系、不支持结构化查询、丢失时间序列信息
适用场景:文档检索、FAQ 匹配、语义搜索
图记忆
优势:支持多跳推理、结构化查询、时间感知、关系显式建模
局限:实现复杂、查询延迟较高、需要图数据库
适用场景:客服 Agent、个人助理、项目管理
最后,我们讨论生产环境的关键考量:性能、监控和成本控制。
性能优化清单
📊 索引优化
- HNSW 参数调优:M=16, ef_construction=200, ef=50
- PQ 乘积量化:将 1536 维压缩到 64 字节,内存减少 90%
- IVF 倒排索引:先聚类再搜索,适合亿级数据
⚡ 缓存策略
- Embedding 缓存:Redis 存储热点查询的向量结果
- 检索结果缓存:相同 query 直接返回,TTL 设为 5 分钟
- LLM 响应缓存:对相同上下文 + 问题的回答去重
🔧 批量优化
- 批量插入:1000 条/批,避免逐条写入
- 异步写入:记忆写入不阻塞主流程
- 增量索引:只更新变化的数据,不重建全量索引
📈 监控指标
- P99 延迟目标:< 100ms,告警阈值 > 500ms
- 召回率:top-10 准确率 > 90%
- Token 使用率:控制在预算的 60-80%
成本估算(10 万用户规模)
| 组件 |
方案 |
月成本 |
| 向量数据库 |
Qdrant Cloud (100 万向量) |
$249 |
| 图数据库 |
Neo4j Aura Basic |
$129 |
| Embedding API |
OpenAI text-embedding-3-small |
~$50 (1M 次调用) |
| LLM |
GPT-4o-mini (128K context) |
~$200 (10 万用户) |
| 总计 |
~$628/月 |
💡 优化建议
对于初创项目,可以从 Chroma(嵌入式)+ SQLite 开始,零成本验证。用户量达到 1 万后再迁移到 Qdrant Cloud。Neo4j 可以用 Mem0 等托管服务替代,进一步降低运维成本。