如果你用过 Stable Diffusion 或 Flux.1 生成图片,可能想过这个问题:一张 1024×1024 的 RGB 图像,像素空间维度是 1024×1024×3 ≈ 300 万,扩散模型要在这么高维的空间里一步步去噪,计算量大到不可想象。
实际上,所有主流扩散模型都不在像素空间操作,而是先把图像压缩到一个低维的潜在空间(Latent Space),在这个压缩后的表示上做扩散去噪,最后再解压回像素空间。
这个"压缩 - 解压"的核心组件,就是 VAE(变分自编码器,Variational Autoencoder)。
本教程你将理解
- ✓ 什么是潜在空间,为什么它比像素空间更适合扩散
- ✓ VAE 编码器和解码器的分工:图像→latent 与 latent→图像
- ✓ 完整流程:输入图→VAE 编码→latent 扩散→VAE 解码→输出图
- ✓ PyTorch 代码实战:手写一个微型 VAE,看压缩比如何达到 48 倍
- ✓ 为什么潜在空间扩散能节省 98% 以上的计算量
核心概念:潜在空间是什么
潜在空间是一个低维、连续的向量空间。你可以把它理解为图像的"压缩表示"或"紧凑编码"。
类比:一张 100MB 的 PNG 图片,用 ZIP 压缩后变成 2MB。ZIP 文件就是"潜在表示",解压后能还原出原图。VAE 的作用类似,但它不是简单的压缩算法,而是一个神经网络,它学到的潜在空间具有更好的数学性质:
- 连续性:潜在向量稍微变化,解码出的图像也平滑变化(不会出现 ZIP 解压失败的花屏)
- 语义性:潜在空间的某些维度对应具体语义(如"笑脸程度"、"侧脸角度")
- 可采样性:可以从潜在空间随机采样,解码出合理的新图像

为什么要在潜在空间做扩散
以 Stable Diffusion 为例,它使用的 VAE 压缩比是 4×4×8 = 128 倍(空间各压缩 4 倍,通道从 3 变 4):
- 像素空间:512×512×3 = 786,432 维
- 潜在空间:128×128×4 = 65,536 维
扩散模型每一步去噪都要用 U-Net 对整张图做卷积。在潜在空间操作,计算量减少到约 1/12(考虑通道数差异),显存占用也大幅下降。
更重要的是,潜在空间已经过滤掉了像素级的高频噪声,扩散模型可以专注于学习语义层面的结构,生成的图像质量更高、训练更稳定。

完整流程:从输入图像到生成图像
扩散模型的完整管线分为四个阶段:
-
1
VAE 编码:图像 → Latent
输入一张 RGB 图像(如 512×512×3),VAE 编码器(Encoder)把它压缩成潜在向量
z = encoder(x),输出维度为 128×128×4。关键操作:编码器输出的是概率分布的参数(均值 μ 和方差 σ),而不是确定的向量。然后用重参数化技巧采样:
z = μ + σ ⊙ ε, 其中 ε ~ N(0, I)这样保证了潜在表示具有随机性,能够从同一输入生成不同变体。
-
2
前向扩散:添加噪声
在训练阶段,对潜在向量
z₀逐步加噪,T 步后变成纯高斯噪声zᴛ:z_t = √(ᾱ_t) · z₀ + √(1 - ᾱ_t) · ε, ε ~ N(0, I)ᾱ_t是预设的噪声调度,控制每一步加多少噪声。 -
3
反向扩散:U-Net 去噪
训练一个 U-Net 网络,输入带噪的
z_t和步数t,预测出噪声ε或原始z₀:ε_pred = U-Net(z_t, t, condition)inference 时从随机噪声开始,一步步减去预测的噪声,最终得到干净的
z₀。 -
4
VAE 解码:Latent → 图像
把去噪后的潜在向量
z₀输入 VAE 解码器(Decoder),解压回像素空间:x_recon = decoder(z₀)输出就是最终的生成图像(512×512×3)。

实战:手写微型 VAE
下面用 PyTorch 实现一个简化版 VAE,输入 64×64×3 图像,压缩到 16×16×4 潜在空间(压缩比 48 倍)。
步骤 1:定义编码器
class Encoder(nn.Module):
def __init__(self, latent_dim=4):
super().__init__()
self.net = nn.Sequential(
# 64×64×3 → 32×32×64
nn.Conv2d(3, 64, 4, stride=2, padding=1),
nn.ReLU(),
# 32×32×64 → 16×16×128
nn.Conv2d(64, 128, 4, stride=2, padding=1),
nn.ReLU(),
# 16×16×128 → 8×8×256
nn.Conv2d(128, 256, 4, stride=2, padding=1),
nn.ReLU(),
)
# 输出均值和 log 方差(各 latent_dim 通道)
self.mu_layer = nn.Conv2d(256, latent_dim, 3, padding=1)
self.logvar_layer = nn.Conv2d(256, latent_dim, 3, padding=1)
def forward(self, x):
h = self.net(x)
mu = self.mu_layer(h)
logvar = self.logvar_layer(h)
return mu, logvar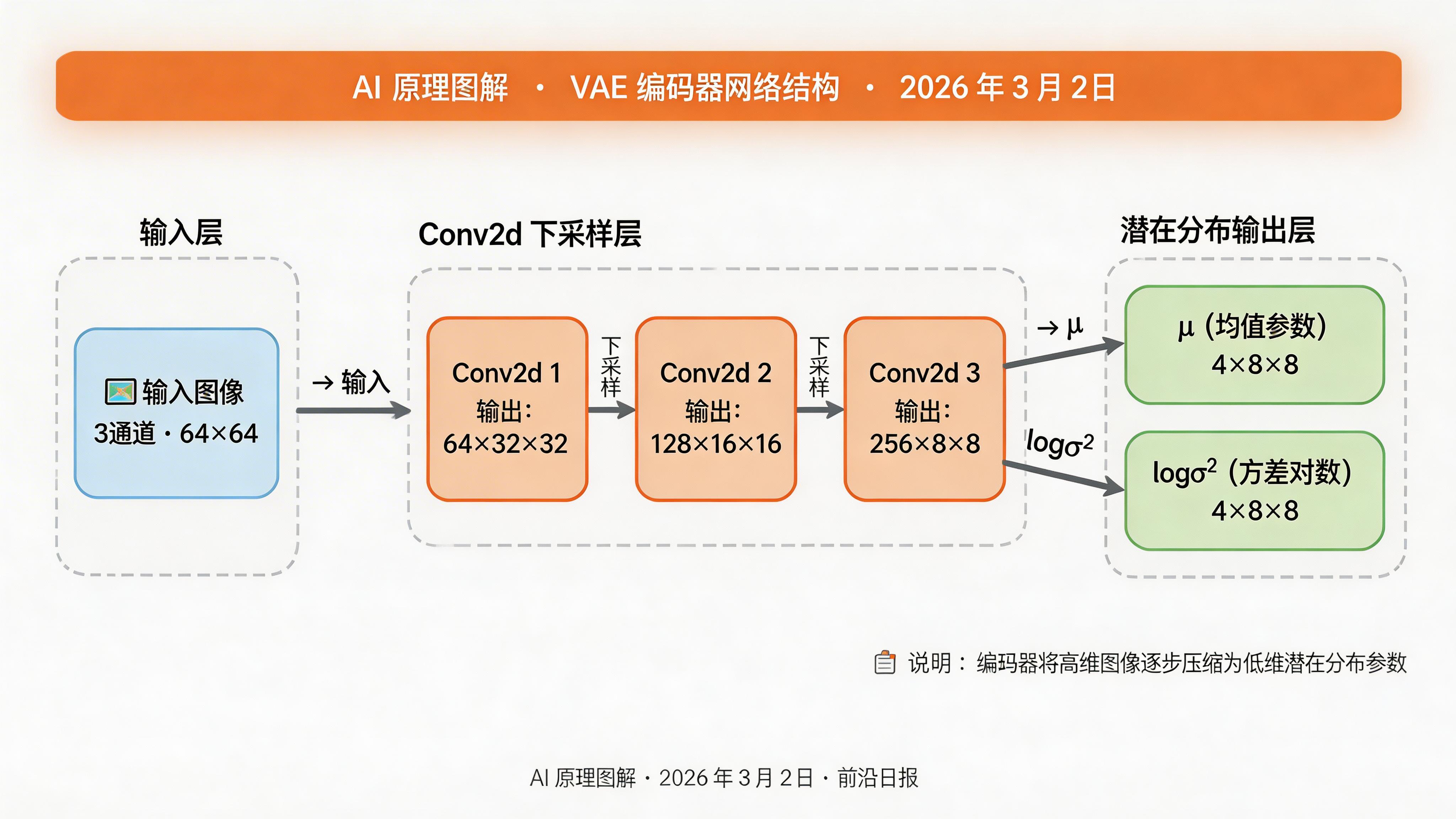
步骤 2:重参数化采样
def reparameterize(mu, logvar):
"""从 N(mu, sigma^2) 采样,使用重参数化技巧"""
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std) # ε ~ N(0, I)
return mu + std * eps # z = μ + σ·ε这个操作保证了梯度可以反向传播到编码器(ε detach 了随机性)。
步骤 3:定义解码器
class Decoder(nn.Module):
def __init__(self, latent_dim=4):
super().__init__()
self.net = nn.Sequential(
# 8×8×4 → 8×8×256
nn.Conv2d(latent_dim, 256, 3, padding=1),
nn.ReLU(),
# 8×8×256 → 16×16×128
nn.ConvTranspose2d(256, 128, 4, stride=2, padding=1),
nn.ReLU(),
# 16×16×128 → 32×32×64
nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1),
nn.ReLU(),
# 32×32×64 → 64×64×3
nn.ConvTranspose2d(64, 3, 4, stride=2, padding=1),
nn.Sigmoid(), # 输出像素值 [0, 1]
)
def forward(self, z):
return self.net(z)
步骤 4:计算损失并训练
def vae_loss(x_recon, x, mu, logvar):
"""VAE 损失 = 重建损失 + KL 散度"""
# 重建损失:MSE 或 BCE
recon_loss = F.mse_loss(x_recon, x)
# KL 散度:让 q(z|x) 接近先验 N(0, I)
kl_loss = -0.5 * torch.mean(1 + logvar - mu.pow(2) - logvar.exp())
return recon_loss + kl_loss训练循环:
for epoch in range(50):
for x in dataloader: # x: [B, 3, 64, 64]
mu, logvar = encoder(x)
z = reparameterize(mu, logvar) # 采样 latent
x_recon = decoder(z) # 解码回图像
loss = vae_loss(x_recon, x, mu, logvar)
optimizer.zero_grad()
loss.backward()
optimizer.step()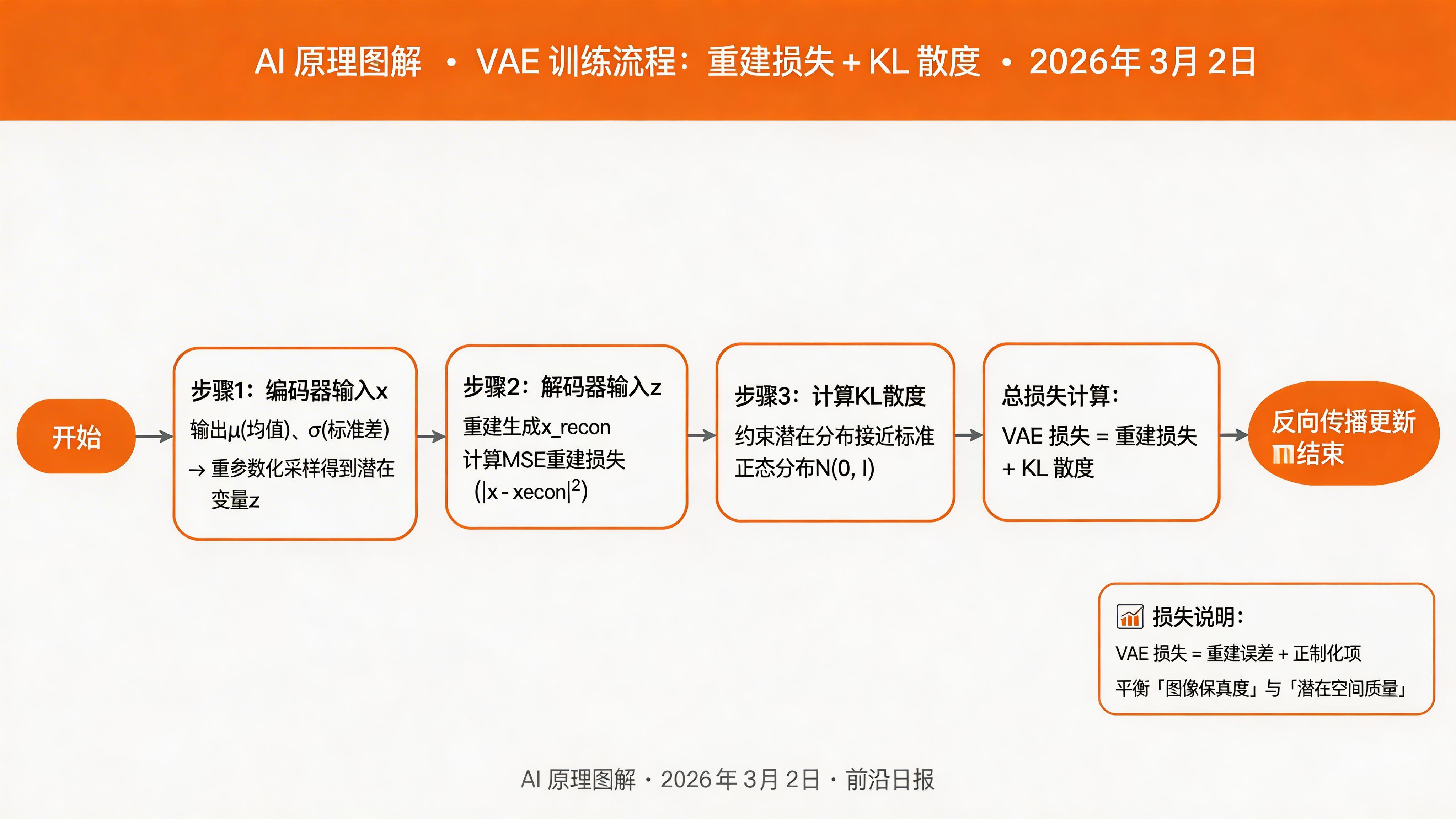
步骤 5:测试压缩效果
# 加载训练好的 VAE
encoder.eval()
decoder.eval()
# 编码 - 解码测试
with torch.no_grad():
mu, logvar = encoder(test_image)
z = reparameterize(mu, logvar)
x_recon = decoder(z)
# 计算压缩比
original_size = 64 * 64 * 3 # 12,288
latent_size = 8 * 8 * 4 # 256
compression_ratio = original_size / latent_size # 48 倍
print(f"压缩比:{compression_ratio}x")
print(f"PSNR: {calculate_psnr(test_image, x_recon):.2f} dB")FAQ
总结
- ✓ 潜在空间是低维连续向量空间,图像在这里做扩散计算量减少 98%+
- ✓ VAE 编码器把图像压缩为 latent 向量(如 512×512×3 → 128×128×4)
- ✓ VAE 解码器把 latent 向量解压回 RGB 图像
- ✓ 重参数化技巧:z = μ + σ·ε,让随机采样可反向传播
- ✓ 完整流程:图像→编码→latent 扩散→解码→生成图
- ✓ 压缩比:Stable Diffusion 为 48 倍,Flux.1 类似
下一篇我们将深入 Diffusion 的噪声调度(Noise Schedule):为什么线性调度不如余弦调度?如何通过调节噪声曲线提升生成质量?