为什么你的 Agent 总是"失忆"?
2026 年的 Agent 系统普遍存在三大记忆缺陷:
- 碎片化存储 — 对话历史、工具调用、用户偏好分散在不同位置
- 关系丢失 — 向量检索只能找到"相似"内容,无法追溯因果链条
- 长期记忆失效 — 超过 100K tokens 的上下文让模型迷失在噪声中
本教程将构建一个混合记忆架构:向量数据库处理模糊语义检索,知识图谱保留实体关系与因果链条,混合路由器根据查询类型自动选择检索策略。
环境准备与工具栈
Python 3.11+
主编程语言,Async 支持
Qdrant / Chroma
向量数据库,存储 Embedding
Neo4j
知识图谱,存储关系网络
LangChain Memory
记忆管理抽象层
text-embedding-3-large
OpenAI 高维 Embedding 模型
💡 核心思想:向量检索擅长"找相似",图谱遍历擅长"找关系"。混合架构让 Agent 同时拥有模糊匹配能力与逻辑推理能力。
步骤 1:设计混合记忆存储模型
01
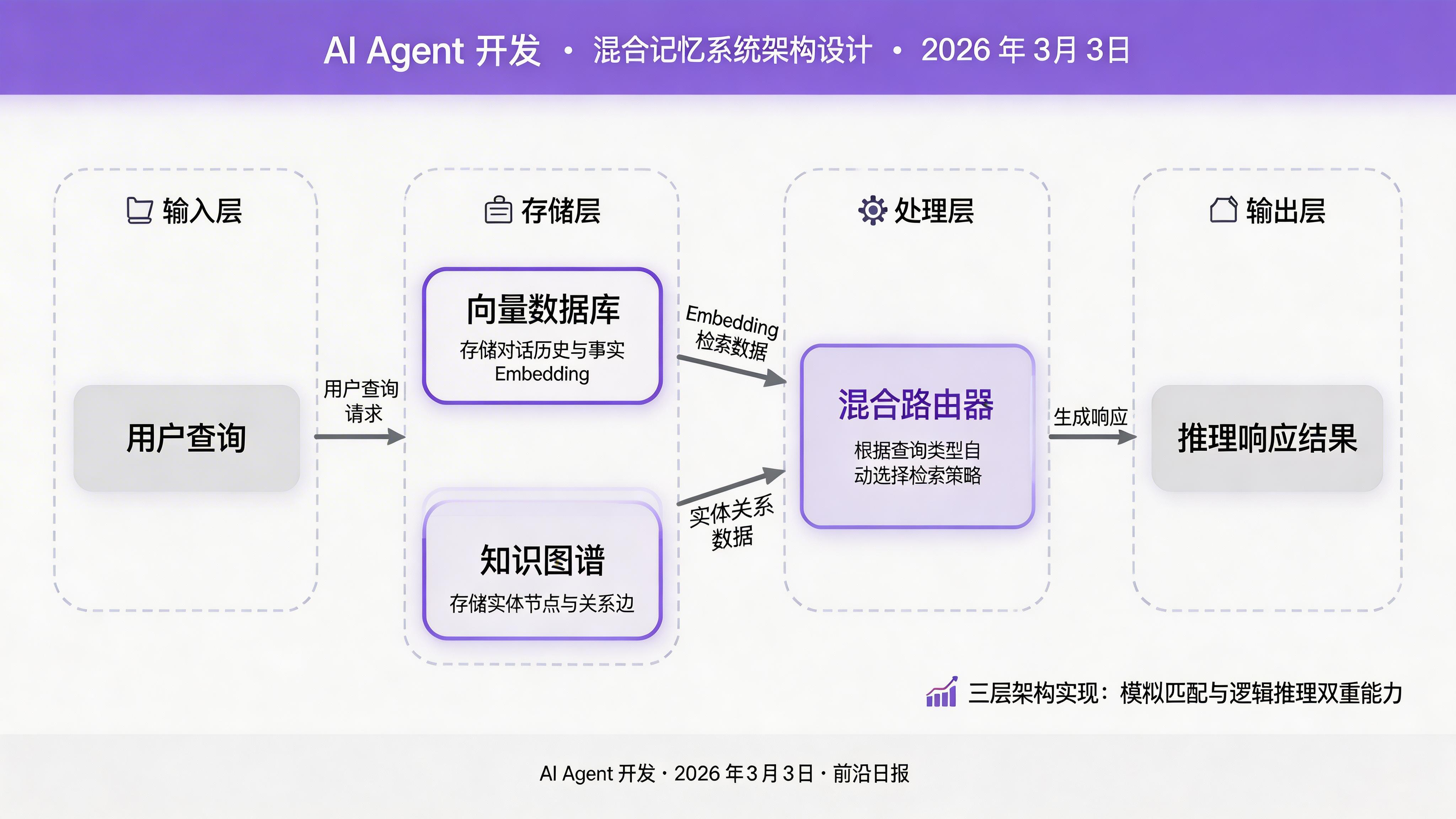
定义记忆数据类型与存储策略
记忆系统需要处理三类数据:短期对话(Session)、长期事实(Facts)、关系网络(Relations)。每类数据对应不同的存储策略:
from pydantic import BaseModel, Field
from typing import List, Optional
from enum import Enum
class MemoryType(str, Enum):
SHORT_TERM = "short_term" # 会话级记忆(向量存储)
LONG_TERM = "long_term" # 持久化事实(向量 + 图谱)
RELATION = "relation" # 实体关系(仅图谱)
class Memory(BaseModel):
id: str
type: MemoryType
content: str
embedding: Optional[List[float]] = None
entities: List[str] = Field(default_factory=list) # 提取的实体
timestamp: float
ttl_hours: Optional[int] = None # None = 永久
⚠️ 注意:向量存储适合全文检索,但无法表达"A 是 B 的上级"这类关系。必须在写入时同步提取实体并构建图谱关系。
步骤 2:搭建向量数据库层
02

初始化 Qdrant 客户端与 Collection
使用 Qdrant 作为向量存储,支持 HNSW 索引与 Payload 过滤:
from qdrant_client import QdrantClient
from qdrant_client.models import (
Distance, VectorParams, PointStruct,
Filter, FieldCondition, MatchValue
)
# 初始化客户端
client = QdrantClient(host="localhost", port=6333)
# 创建 Collection(1536 维 = text-embedding-3-large)
COLLECTION_NAME = "agent_memory"
client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(size=1536, distance=Distance.COSINE),
)
# 创建 Payload 索引(用于按类型过滤)
client.create_payload_index(
collection_name=COLLECTION_NAME,
field_name="memory_type",
field_schema="keyword"
)
写入记忆时需同时存储向量与 Payload 元数据:
from openai import OpenAI
openai_client = OpenAI()
def embed(text: str) -> List[float]:
"""生成 1536 维 Embedding"""
response = openai_client.embeddings.create(
model="text-embedding-3-large",
input=text
)
return response.data[0].embedding
def store_memory(memory: Memory):
# 生成向量
if memory.embedding is None:
memory.embedding = embed(memory.content)
# 写入 Qdrant
client.upsert(
collection_name=COLLECTION_NAME,
points=[
PointStruct(
id=hash(memory.id) % (2**63),
vector=memory.embedding,
payload=memory.model_dump()
)
]
)
步骤 3:构建知识图谱层
03

Neo4j 图谱设计与实体关系写入
使用 Neo4j 存储实体及其关系。核心设计:
- 节点(Node):Entity(带 name、type 属性)
- 关系(Relationship):RELATED_TO、PART_OF、CAUSES、USES 等
from neo4j import GraphDatabase
class GraphMemory:
def __init__(self, uri: str, user: str, password: str):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def close(self):
self.driver.close()
def add_entity(self, name: str, type: str):
"""添加实体节点"""
with self.driver.session() as session:
session.run(
"MERGE (e:Entity {name: $name}) SET e.type = $type",
name=name, type=type
)
def add_relation(self, from_entity: str, to_entity: str, rel_type: str):
"""添加实体关系"""
with self.driver.session() as session:
session.run(
f"""
MATCH (a:Entity {{name: $from}})
MATCH (b:Entity {{name: $to}})
MERGE (a)-[:{rel_type}]->(b)
""",
from=from_entity, to=to_entity
)
从对话中提取实体与关系的简单实现(实际项目可用 LLM 提取):
import re
def extract_entities(text: str) -> List[str]:
"""简单规则提取:大写字母开头的词、技术术语"""
# 简化示例:提取引号内的内容
return re.findall(r'"([^"]+)"', text)
def build_graph_from_memory(memory: Memory, graph: GraphMemory):
"""将记忆中的实体写入图谱"""
entities = extract_entities(memory.content)
# 添加实体
for entity in entities:
graph.add_entity(entity, "concept")
# 简单关系:如果两个实体在同一段记忆中出现,建立弱相关关系
for i, e1 in enumerate(entities):
for e2 in entities[i+1:]:
graph.add_relation(e1, e2, "RELATED_TO")
💡 进阶技巧:使用 LLM 提取结构化实体关系,如:"MCP 服务器部署在 Cloudflare Workers 上" → MCP 服务器 -[DEPLOYED_ON]→ Cloudflare Workers
步骤 4:实现混合路由器
04
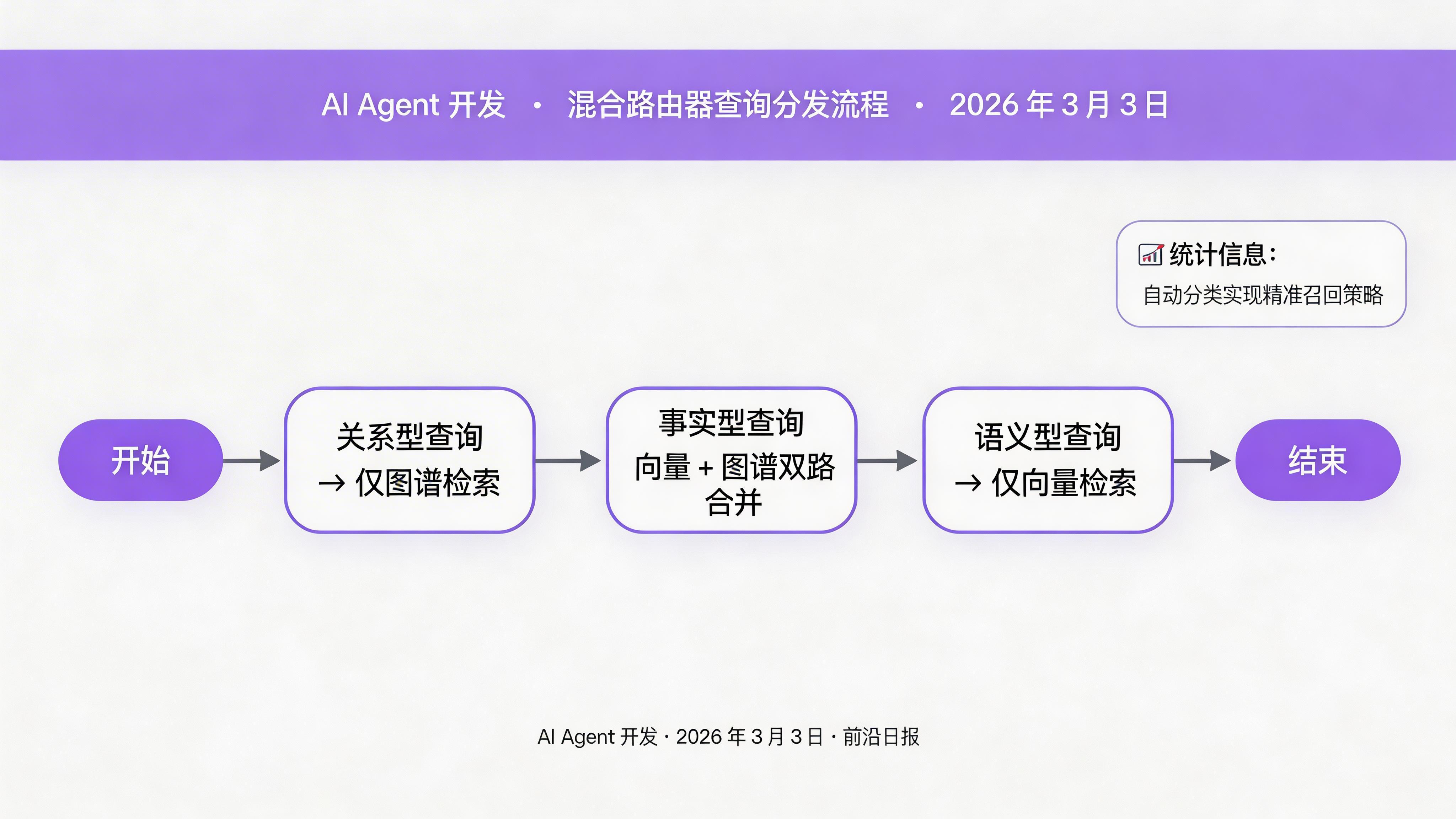
查询分类与双路检索策略
混合路由器的核心逻辑:根据查询类型决定检索策略。
from typing import Literal
class QueryType(str, Enum):
FACTUAL = "factual" # 事实型:图谱优先
SEMANTIC = "semantic" # 语义型:向量优先
RELATIONAL = "relational" # 关系型:仅图谱
def classify_query(query: str) -> QueryType:
"""简单规则分类(生产环境用 LLM 分类器)"""
query_lower = query.lower()
# 关系型关键词
if any(w in query_lower for w in ["关系", "连接", "属于", "依赖"]):
return QueryType.RELATIONAL
# 事实型关键词
if any(w in query_lower for w in ["什么是", "定义", "原理", "架构"]):
return QueryType.FACTUAL
return QueryType.SEMANTIC
class HybridRouter:
def __init__(self, vector_client: QdrantClient, graph: GraphMemory):
self.vector_client = vector_client
self.graph = graph
def search(self, query: str, top_k: int = 5) -> List[dict]:
query_type = classify_query(query)
if query_type == QueryType.RELATIONAL:
return self.graph_search(query)
elif query_type == QueryType.FACTUAL:
# 双路检索:向量 + 图谱
vector_results = self.vector_search(query, top_k // 2)
graph_results = self.graph_search(query)
return self.merge_results(vector_results, graph_results)
else:
return self.vector_search(query, top_k)
向量检索实现:
def vector_search(self, query: str, top_k: int) -> List[dict]:
query_embedding = embed(query)
results = self.vector_client.search(
collection_name=COLLECTION_NAME,
query_vector=query_embedding,
limit=top_k
)
return [
{"source": "vector", "score": r.score, "content": r.payload["content"]}
for r in results
]
图谱检索实现(遍历相关实体):
def graph_search(self, query: str) -> List[dict]:
"""从图谱中检索相关实体与关系"""
# 简单实现:提取查询中的实体,查找其关联
entities = extract_entities(query)
if not entities:
return []
with self.graph.driver.session() as session:
cypher = """
MATCH (e:Entity)-[r]-(related:Entity)
WHERE e.name IN $entities
RETURN e.name, type(r) as rel_type, related.name as related_name
LIMIT 20
"""
result = session.run(cypher, entities=entities)
return [
{
"source": "graph",
"content": f"{record['e.name']} -[{record['rel_type']}]-> {record['related_name']}"
}
for record in result
]
步骤 5:实现记忆压缩与 TTL 管理
05
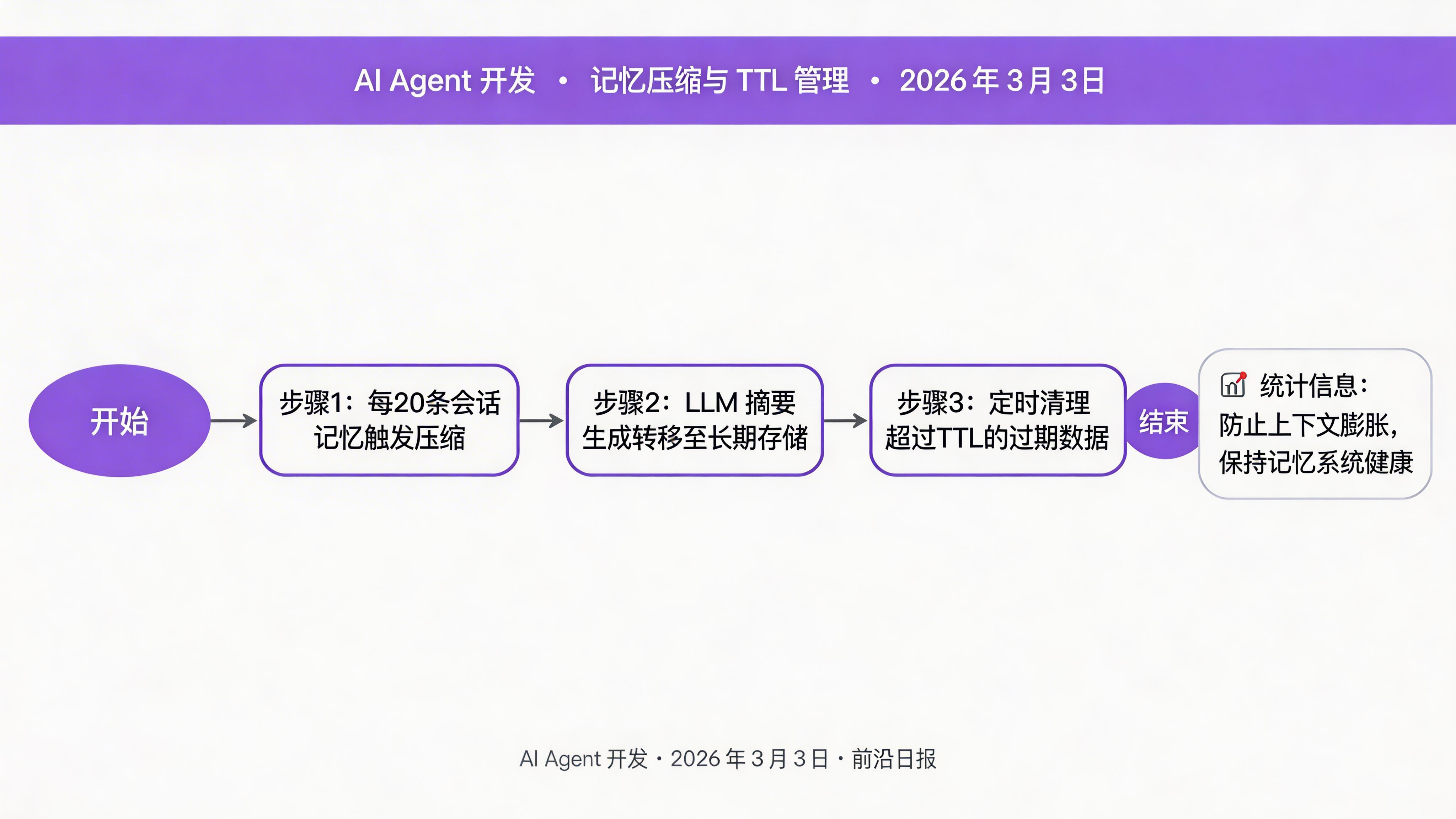
长期记忆压缩与过期清理
短期记忆会随时间膨胀,需要定期压缩并转移到长期存储:
from openai import OpenAI
class MemoryCompressor:
def __init__(self):
self.llm = OpenAI()
def compress_session(self, memories: List[Memory]) -> Memory:
"""压缩多段会话记忆为摘要"""
content = "\n".join(m.content for m in memories)
response = self.llm.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "将以下对话压缩为 3-5 个关键事实,每句一行。"},
{"role": "user", "content: content}
]
)
return Memory(
id=f"summary_{memories[0].id}",
type=MemoryType.LONG_TERM,
content=response.choices[0].message.content,
timestamp=time.time(),
ttl_hours=None # 永久保存
)
def cleanup_expired(self):
"""清理过期记忆"""
cutoff = time.time() - (24 * 3600) # 24 小时前
expired = client.scroll(
collection_name=COLLECTION_NAME,
scroll_filter=Filter(
must=[FieldCondition(key="ttl_hours", match=MatchValue(value=24))]
)
)
for point in expired:
if point.payload["timestamp"] < cutoff:
client.delete(
collection_name=COLLECTION_NAME,
points_selector=[point.id]
)
步骤 6:集成到 Agent 运行时
06
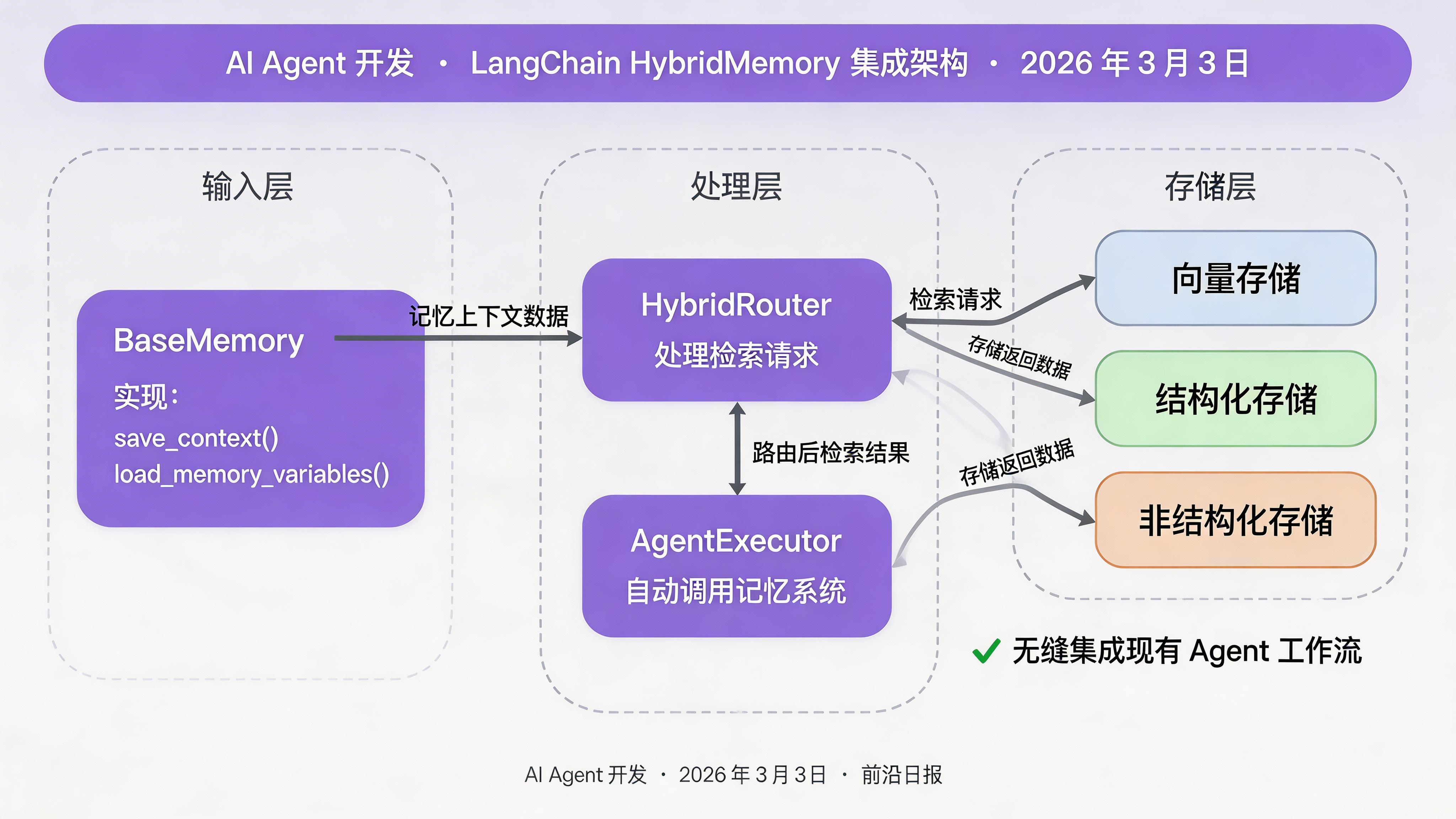
LangChain Memory 集成示例
将混合记忆系统集成为 LangChain 的 BaseMemory 接口:
from langchain.memory import BaseMemory
from typing import Dict, List
class HybridMemory(BaseMemory):
router: HybridRouter
compressor: MemoryCompressor
session_memories: List[Memory] = []
class Config:
arbitrary_types_allowed = True
def save_context(self, inputs: Dict, outputs: Dict):
"""保存对话上下文"""
user_input = inputs.get("input", "")
agent_output = outputs.get("output", "")
# 写入短期记忆
self.session_memories.extend([
Memory(
id=f"session_{len(self.session_memories)}",
type=MemoryType.SHORT_TERM,
content=user_input,
timestamp=time.time(),
ttl_hours=24
),
Memory(
id=f"session_{len(self.session_memories)+1}",
type=MemoryType.SHORT_TERM,
content=agent_output,
timestamp=time.time(),
ttl_hours=24
)
])
# 每 10 轮对话压缩一次
if len(self.session_memories) >= 20:
compressed = self.compressor.compress_session(self.session_memories)
store_memory(compressed)
self.session_memories = []
def load_memory_variables(self, inputs: Dict) -> Dict:
"""加载相关记忆"""
query = inputs.get("input", "")
results = self.router.search(query, top_k=5)
return {
"history": "\n".join(r["content"] for r in results)
}
使用示例:
from langchain.agents import AgentExecutor, create_openai_tools_agent
# 初始化混合记忆
hybrid_memory = HybridMemory(
router=HybridRouter(client, graph),
compressor=MemoryCompressor()
)
# 创建 Agent
agent = create_openai_tools_agent(llm, tools, prompt)
executor = AgentExecutor(
agent=agent,
tools=tools,
memory=hybrid_memory, # 注入记忆
verbose=True
)
# 运行
response = executor.invoke({"input": "我之前部署的 MCP 服务器在哪里?"})
print(response["output"])
常见问题 FAQ
向量数据库和图谱的存储成本对比如何?
Qdrant 存储 1536 维向量每条约 6KB(含 Payload),Neo4j 节点 + 关系约 1KB。对于 10 万条记忆,混合架构总存储约 500MB–800MB,成本可接受。
如何避免图谱中产生过多冗余关系?
设置关系阈值:同一对实体之间的相同关系只保留一条。定期运行图谱清理任务,合并弱相关关系(如 A-RELATED_TO-B 且 B-RELATED_TO-C 且时间相近 → A-RELATED_TO-C)。
生产环境中如何扩展这套架构?
向量库使用 Qdrant Cloud 或自建集群(分片 + 副本);图谱使用 Neo4j Aura 或搭建因果集群;路由器添加缓存层(Redis)加速高频查询。
是否可以用其他向量数据库替代 Qdrant?
可以。Chroma(轻量)、Weaviate(自带分类器)、Pinecone(托管服务)都支持类似 API。只需修改 store_memory 和 vector_search 的实现。
总结
- 向量存储处理模糊语义检索,图谱存储处理关系推理
- 混合路由器根据查询类型自动选择检索策略
- 记忆压缩防止短期记忆无限膨胀,TTL 管理自动清理过期数据
- LangChain 集成让现有 Agent 无缝获得混合记忆能力