想在消费级显卡上微调 Llama-3-70B 这样的百亿参数大模型?全量微调需要数百 GB 显存,但 LoRA(Low-Rank Adaptation)技术通过巧妙的矩阵分解,将可训练参数压缩到原来的 0.1-1%,却能达到 95-100% 的全量微调性能。
2026 年,LoRA 已成为大模型微调的事实标准,衍生出 QLoRA、DoRA、GraLoRA 等多个变体。本文将深入解析 LoRA 的数学原理,并手把手教你用 QLoRA 在单张 RTX 4090(24GB)上微调 Llama-3.2-3B 模型。
为什么需要 LoRA?全量微调的困境
假设你要微调 Llama-3.2-3B 模型(30 亿参数),使用 FP16 精度时:
30 亿参数 × 2 字节 = 6GB
Adam 优化器状态 ≈ 48GB
梯度 + 激活值 ≈ 12GB
总计需要 ≈ 66GB 显存
这还没考虑 batch size 和序列长度的开销。即使是 RTX 4090(24GB)也无法承受。LoRA 的核心洞察是:微调过程中的权重更新具有低秩特性——只需要在少量"方向"上调整权重,就能让模型适应新任务。

LoRA 的数学原理:低秩分解
LoRA 的核心思想:冻结预训练权重 W,用两个小矩阵的乘积 B×A 来近似权重更新 ΔW。
# 原始权重更新 (全量微调)
W_new = W_old + ΔW # ΔW 形状:(d, k),需要训练 d×k 个参数
# LoRA 权重更新
W_new = W_old + B × A # B: (d, r), A: (r, k)
# 可训练参数量:d×r + r×k ≈ r×(d+k),当 r << min(d,k) 时大幅减少秩 r 的选择:通常取 8、16、32、64。实验表明,r=16 时就能捕捉大部分微调信息,参数量减少超过 99%。
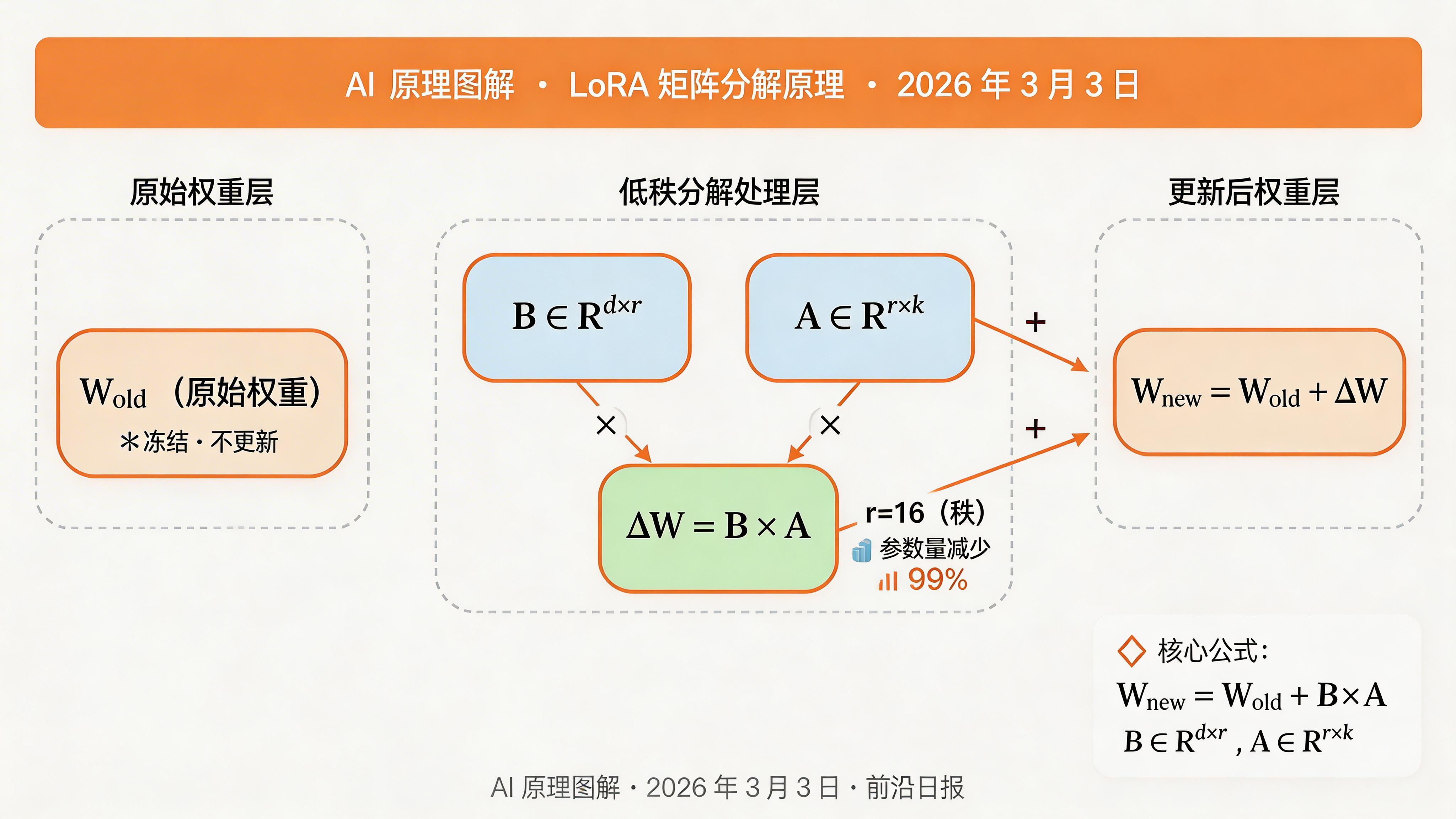
关键洞察:LoRA 假设微调所需的"新知识"可以压缩到低维子空间中。就像给一个博学的教授(预训练模型)一本薄薄的专业手册(LoRA 适配器),而不是让他重新学习整个学科。
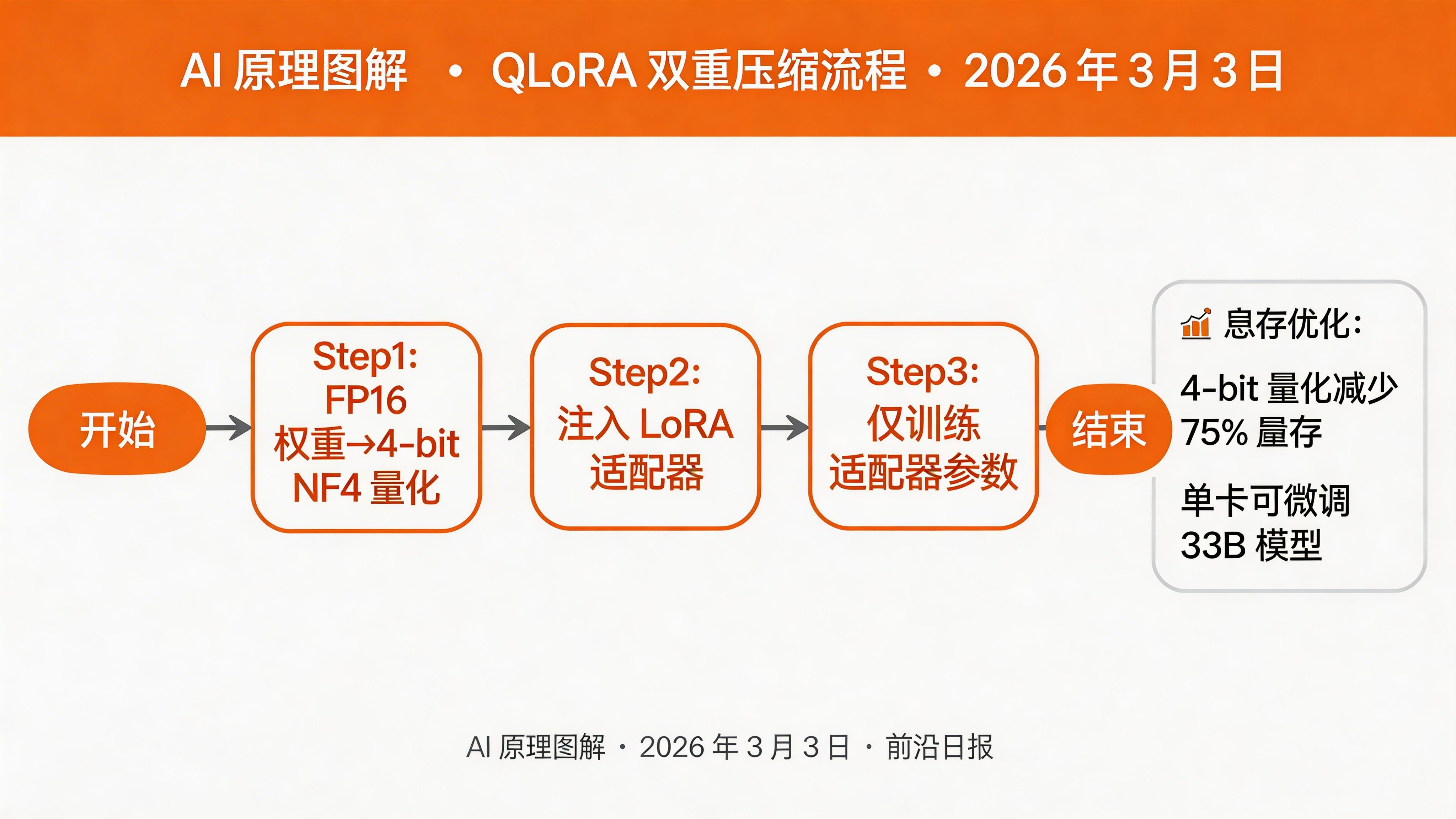
QLoRA:4 比特量化 + LoRA 的双重压缩
LoRA 虽然减少了可训练参数,但冻结的预训练权重仍需加载到显存中。QLoRA(Quantized LoRA)通过 4 比特 NF4(Normal Float 4)量化,将冻结权重的显存占用再减少 75%。
# FP16 vs 4-bit 显存对比
# Llama-3.2-3B: 3B 参数
# FP16: 3B × 2 bytes = 6GB
# 4-bit NF4: 3B × 0.5 bytes = 1.5GBQLoRA 的三项关键技术:
- 4-bit NF4 量化:针对权重分布优化的非标度量化格式
- 分页优化器:使用 CPU 内存处理优化器状态的突发分配
- 双重量化:对量化常数也进行量化,进一步压缩
准备工作:环境与依赖
Python 3.10+
推荐 3.10 或 3.11
PyTorch 2.0+
带 CUDA 11.8+ 支持
Transformers
Hugging Face 核心库
PEFT
参数高效微调库
bitsandbytes
4-bit 量化支持
GPU 显存
最低 12GB,推荐 24GB+
# 创建虚拟环境
python -m venv lora-env
source lora-env/bin/activate # Windows: lora-env\Scripts\activate
# 安装 PyTorch (CUDA 11.8)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 安装核心依赖
pip install transformers datasets accelerate peft bitsandbytes
pip install trl wandb evaluate scipy
# 验证 GPU 可用性
python -c "import torch; print(f'GPU: {torch.cuda.get_device_name(0)}')"
python -c "import bitsandbytes as bnb; print('bitsandbytes 4-bit 支持已启用')"实战:QLoRA 微调 Llama-3.2-3B
本实战将微调 Llama-3.2-3B-Instruct 模型,让它学会以结构化格式回答技术问题(类似 Stack Overflow 风格)。
1
准备数据集
使用 Hugging Face 的 tech-qa-pairs 数据集,或自定义 JSONL 格式:
import json
from datasets import Dataset
# 自定义数据格式
data = [
{
"instruction": "解释 Python 装饰器的工作原理",
"response": """**装饰器本质**:接收函数并返回新函数的可调用对象
**执行流程**:
1. Python 在模块加载时立即执行装饰器
2. 装饰器接收原函数,返回包装后的新函数
3. 原函数名被重新绑定到包装函数
**示例代码**:
```python
def timing_decorator(func):
def wrapper(*args, **kwargs):
import time
start = time.time()
result = func(*args, **kwargs)
end = time.time()
print(f"{func.__name__} 耗时:{end-start:.4f}s")
return result
return wrapper
@timing_decorator
def slow_function():
time.sleep(1)
```"""
}
# ... 更多样本
]
dataset = Dataset.from_list(data)
dataset = dataset.train_test_split(test_size=0.1)
print(f"训练集:{len(dataset['train'])} 条")
print(f"测试集:{len(dataset['test'])} 条")
2
加载 4-bit 量化模型
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_name = "meta-llama/Llama-3.2-3B-Instruct"
# 配置 4-bit NF4 量化
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True, # 双重量化
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
# 加载量化模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto", # 自动分配到 GPU
trust_remote_code=True,
)
print(f"模型已加载到:{model.device}")
print(f"显存占用:{torch.cuda.memory_allocated() / 1024**2:.2f} MB")3
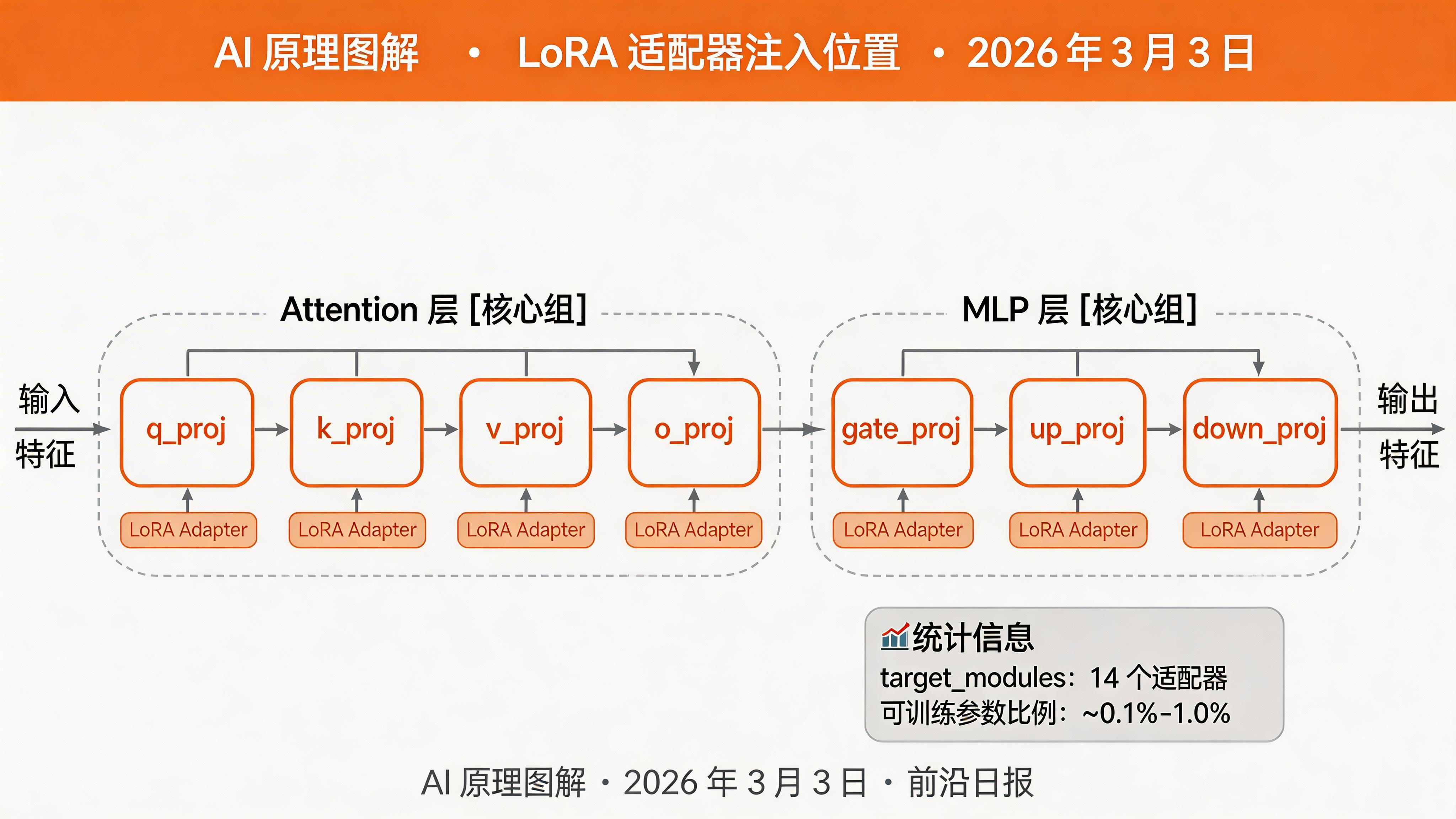
配置 LoRA 适配器
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
# LoRA 配置
lora_config = LoraConfig(
r=16, # 秩:捕获 95%+ 微调信息
lora_alpha=32, # 缩放因子:α=2r 是经验法则
lora_dropout=0.05, # 防止过拟合
bias="none",
task_type="CAUSAL_LM",
# 指定要注入 LoRA 的模块
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj", # Attention
"gate_proj", "up_proj", "down_proj", # MLP
],
)
# 准备模型用于 K-bit 训练
model = prepare_model_for_kbit_training(model)
# 应用 LoRA
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# 输出示例:
# trainable params: 4,194,304 || all params: 3,212,748,800 || trainable%: 0.1305
注意:如果显存不足,可以降低 r 到 8,或减少 target_modules(只训练 attention 层)。
4
数据预处理
def format_prompt(example):
"""将 instruction-response 转换为 Llama-3 对话格式"""
prompt = f"""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
你是一个技术问答专家,以结构化、简洁的方式回答问题。<|eot_id|>
<|start_header_id|>user<|end_header_id|>
{example['instruction']}<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
{example['response']}<|eot_id|>"""
return prompt
def tokenize_function(examples):
texts = [format_prompt({"instruction": i, "response": r})
for i, r in zip(examples['instruction'], examples['response'])]
tokenized = tokenizer(texts, truncation=True, max_length=512, padding="max_length")
tokenized["labels"] = tokenized["input_ids"].copy()
return tokenized
tokenized_dataset = dataset.map(tokenize_function, batched=True, remove_columns=dataset["train"].column_names)
print(f"输入形状:{tokenized_dataset['train']['input_ids'][0][:10]}")5
配置训练参数
from transformers import TrainingArguments
from trl import SFTTrainer
training_args = TrainingArguments(
output_dir="./lora-tech-qa",
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4, # 有效 batch size = 2×4 = 8
learning_rate=2e-4,
num_train_epochs=3,
fp16=True, # 混合精度训练
logging_steps=10,
eval_strategy="steps",
eval_steps=50,
save_steps=50,
max_steps=500, # 小数据集用 step 而非 epoch
warmup_steps=50,
lr_scheduler_type="cosine",
gradient_checkpointing=True, # 减少显存占用
optim="paged_adamw_32bit", # QLoRA 推荐优化器
logging_dir="./logs",
report_to="wandb", # 可选:使用 wandb 监控
)
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"],
tokenizer=tokenizer,
dataset_text_field="instruction", # SFTTrainer 需要
max_seq_length=512,
)
print("训练配置就绪!")6
开始训练
# 启动训练
train_result = trainer.train()
# 保存 LoRA 适配器
trainer.save_model("./lora-tech-qa-final")
tokenizer.save_pretrained("./lora-tech-qa-final")
# 打印训练指标
print(f"训练损失:{train_result.metrics['train_loss']:.4f}")
print(f"训练耗时:{train_result.metrics['train_runtime']:.2f} 秒")
# 可选:上传到 Hugging Face Hub
# model.push_to_hub("your-username/lora-tech-qa")
# tokenizer.push_to_hub("your-username/lora-tech-qa")
训练技巧:使用
gradient_checkpointing=True 可以减少 60% 显存,但会轻微降低训练速度。paged_adamw_32bit 优化器使用 CPU 内存处理突发分配,避免 OOM 错误。
7
推理与评估
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载基础模型 + LoRA 适配器
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype=torch.float16,
)
model = PeftModel.from_pretrained(base_model, "./lora-tech-qa-final")
# 推理示例
def answer_question(question):
prompt = f"""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
你是一个技术问答专家。<|eot_id|>
<|start_header_id|>user<|end_header_id|>
{question}<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>"""
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=256,
do_sample=True,
temperature=0.7,
top_p=0.9,
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# 测试
question = "Python 中如何实现单例模式?"
print(answer_question(question))常见问题 FAQ
LoRA 适配器大小是多少?
对于 Llama-3.2-3B,r=16 的 LoRA 适配器约 15-20MB。这使得可以轻松存储多个领域适配器(医疗、法律、编程),按需加载。
如何选择秩 r 的值?
经验法则:r=8 适用于简单任务(风格迁移),r=16 适用于中等任务(指令微调),r=32-64 适用于复杂任务(专业知识注入)。可以从 r=16 开始,根据验证集性能调整。
LoRA 可以合并回原模型吗?
可以。使用
model = model.merge_and_unload() 将 LoRA 权重合并到基础模型,推理速度提升 10-15%,但失去了模块化优势。为什么训练损失不下降?
检查:1) 学习率是否过小(尝试 1e-4 到 5e-4);2) 数据格式是否正确;3) target_modules 是否覆盖了关键层;4) 增加训练步数。
多 GPU 训练如何配置?
使用 Accelerate:
accelerate config 配置多 GPU,然后用 accelerate launch train.py 启动。QLoRA 的 4-bit 量化支持 ZeRO-3 优化,可实现多卡高效训练。
总结与进阶
- LoRA 核心思想:用低秩矩阵 B×A 近似权重更新,可训练参数减少 99%+
- QLoRA 双重压缩:4-bit NF4 量化 + LoRA,单张 24GB GPU 可微调 33B 模型
- 关键超参数:r=16、α=32、dropout=0.05、lr=2e-4 是良好起点
- 显存优化:gradient_checkpointing、paged_adamw_32bit、batch_size=2
- 模块化优势:一个基础模型 + 多个领域适配器,灵活切换任务
2026 年 LoRA 新进展:
- GraLoRA(2025):将权重矩阵分块,每块独立 LoRA 适配器,解决梯度纠缠问题
- DoRA(ICML 2024):分解权重为方向 + 幅度,微调质量略优于 LoRA
- AdaLoRA:动态分配秩,重要层用高秩,次要层用低秩
# 快速启动脚本(复制即用)
git clone https://github.com/huggingface/peft.git
cd peft/examples/lora_dreambooth
pip install -r requirements.txt
python train_dreambooth.py \
--pretrained_model_name_or_path "stabilityai/stable-diffusion-2-base" \
--instance_prompt "a photo of tok_dog" \
--output_dir "./lora-dog" \
--resolution 512 \
--train_batch_size 1 \
--gradient_accumulation_steps 1 \
--learning_rate 1e-4 \
--report_to wandb