为什么需要状态化 Agent?
在构建复杂的 AI 应用时,你是否遇到过这些痛点:
- 多轮对话中上下文丢失,用户需要重复描述需求
- 长任务执行到一半崩溃,无法从断点恢复
- 工具调用结果无法在后续步骤中复用
- 缺乏对 Agent 执行过程的观察和干预能力
这些问题背后,是一个共同的技术挑战:如何管理 Agent 的状态。传统的请求 - 响应模式无法胜任需要持久化、可恢复、可干预的生产级应用。
LangGraph 0.2 正是为解决这些问题而生。作为 LangChain 团队 2026 年重点推出的状态图框架,它提供了:
- 状态持久化:使用 Checkpoint 机制保存每一步的状态
- 可中断执行:在任意节点暂停,允许人类审查或修改
- 记忆管理:区分短期工作记忆和长期跨会话记忆
- 图式编排:用节点和边精确描述复杂工作流

核心概念:LangGraph 的设计哲学
LangGraph 不是一个高层抽象框架,而是一个低层编排运行时。它不替你写 Prompt,也不封装模型细节,而是提供构建可靠 Agent 的基础设施。
State(状态)
TypedDict 定义的类型化状态,贯穿整个执行流程
Node(节点)
执行计算的基本单元,可以是 LLM 调用、工具执行或状态更新
Edge(边)
定义节点间的转移逻辑,支持条件分支和并行执行
Checkpoint(检查点)
持久化存储,实现故障恢复和人类介入
环境准备与依赖
本教程使用以下工具和版本:
Python 3.10+
LangGraph 0.2 需要 Python 3.10 或更高版本
LangGraph 0.2.x
核心状态图框架
LangChain 1.x
模型和工具集成
SQLite / Postgres
检查点存储后端
# 创建虚拟环境
python -m venv langgraph-demo
cd langgraph-demo
source bin/activate
# 安装核心依赖
pip install -U langgraph langchain-core
pip install langchain-anthropic langchain-community
pip installaiosqlite # SQLite 检查点存储
实战步骤:从零构建状态化 Agent
定义状态结构
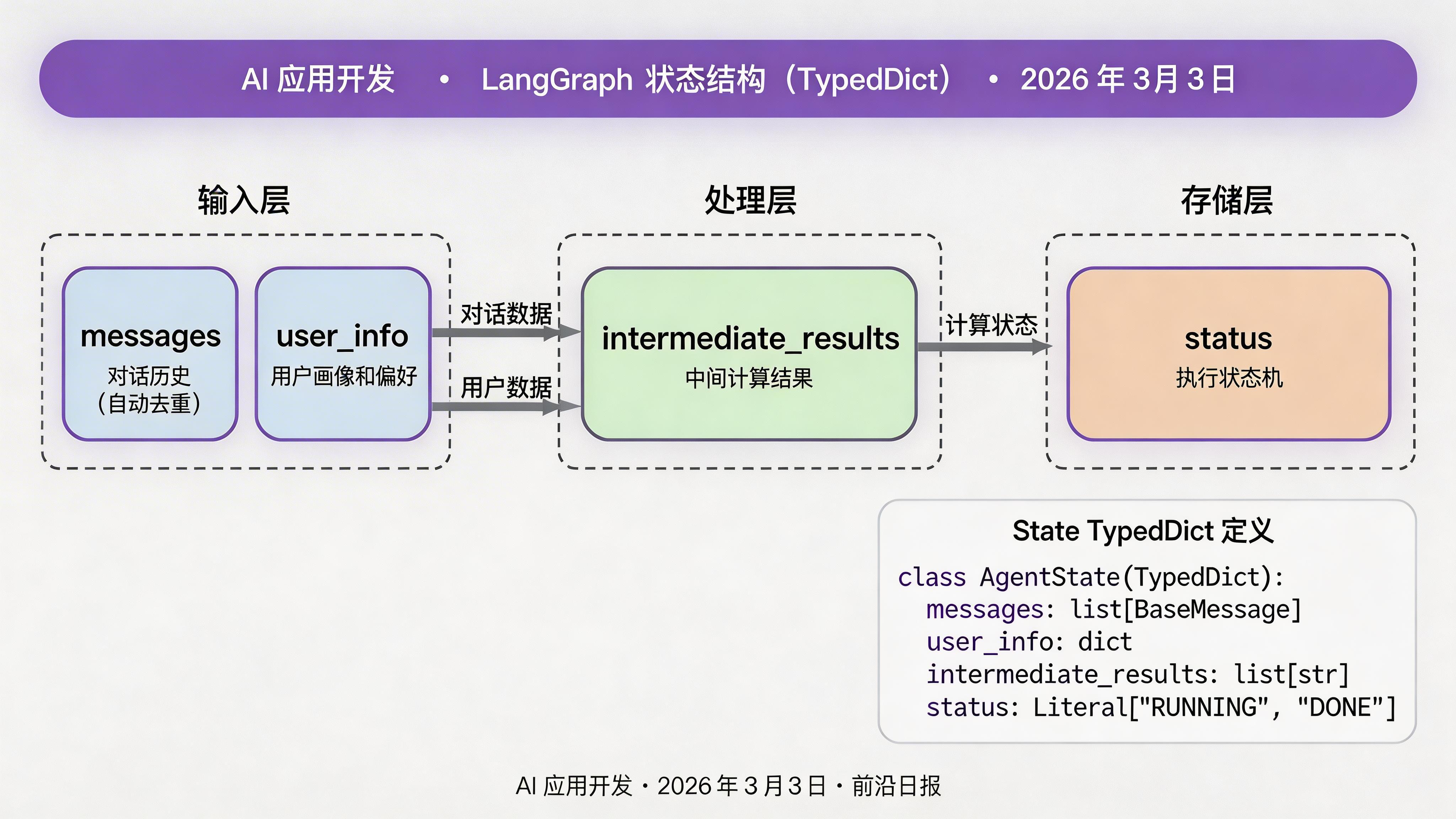
状态是 LangGraph 的核心。我们需要用 TypedDict 明确定义Agent 在整个生命周期中需要维护的数据:
from typing import TypedDict, Annotated, List, Literal
from langgraph.graph.message import add_messages
# 定义消息类型
from langchain_core.messages import HumanMessage, AIMessage
class State(TypedDict):
"""Agent 的完整状态定义"""
messages: Annotated[List, add_messages] # 对话历史(自动去重)
user_info: dict # 用户画像和偏好
current_task: str # 当前任务描述
intermediate_results: List[dict] # 中间计算结果
retry_count: int # 重试次数
status: Literal["pending", "running", "waiting", "completed", "failed"]add_messages 是一个归约函数(reducer),它会自动合并新旧消息,避免重复。
创建节点函数
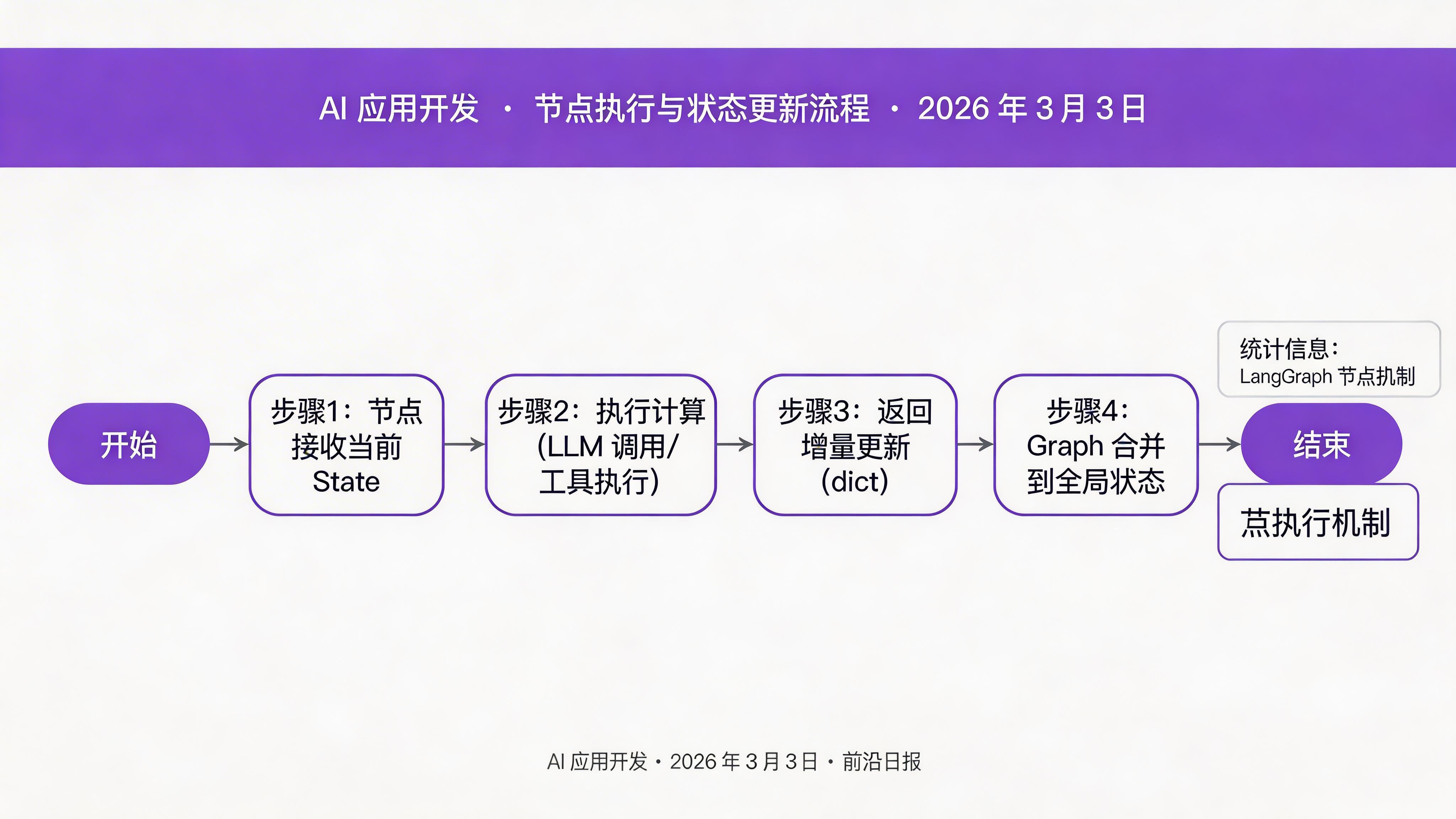
节点是执行实际计算的地方。每个节点接收当前状态,返回更新:
from langchain_anthropic import ChatAnthropic
from langchain_core.messages import HumanMessage, AIMessage
# 初始化 LLM
llm = ChatAnthropic(model="claude-sonnet-4-5-20250929", temperature=0.7)
def call_llm(state: State) -> dict:
"""LLM 调用节点:生成响应"""
messages = state["messages"]
response = llm.invoke(messages)
return {
"messages": [response],
"status": "running"
}
def analyze_task(state: State) -> dict:
"""任务分析节点:理解用户需求"""
last_message = state["messages"][-1].content
# 分析任务复杂度
prompt = f"""分析以下任务的复杂度:
{last_message}
返回 JSON: {{"complexity": "low|medium|high", "estimated_steps": int, "required_tools": []}}"""
analysis = llm.invoke([HumanMessage(content=prompt)])
return {
"current_task": last_message,
"intermediate_results": [{"step": "analysis", "result": analysis.content}]
}
添加工具调用能力
LangGraph 与 LangChain 的工具系统无缝集成。我们定义工具并让 LLM 决定是否调用:
from langchain_core.tools import tool
from langgraph.prebuilt import ToolNode
@tool
def search_web(query: str) -> str:
"""搜索网络获取最新信息"""
# 实际项目中集成 Tavily/Serper 等搜索 API
return f"搜索结果:关于{query}的最新信息..."
@tool
def calculate(expression: str) -> str:
"""执行数学计算"""
try:
result = eval(expression, {"__builtins__": {}}, {})
return f"计算结果:{result}"
except Exception as e:
return f"计算错误:{e}"
@tool
def save_to_memory(key: str, value: str) -> str:
"""保存信息到长期记忆"""
# 实际项目中写入数据库
return f"已保存:{key} = {value}"
# 绑定工具到 LLM
llm_with_tools = llm.bind_tools([search_web, calculate, save_to_memory])
# 创建工具调用节点
tool_node = ToolNode([search_web, calculate, save_to_memory])
# 条件路由:判断是否需要调用工具
def should_call_tool(state: State) -> Literal["tool_node", "call_llm"]:
last_message = state["messages"][-1]
if isinstance(last_message, AIMessage) and last_message.tool_calls:
return "tool_node"
return "call_llm"构建状态图
有了节点和边,就可以组装完整的状态图:
from langgraph.graph import StateGraph, START, END
# 创建图
builder = StateGraph(State)
# 添加节点
builder.add_node("analyze_task", analyze_task)
builder.add_node("call_llm", call_llm)
builder.add_node("tool_node", tool_node)
# 添加边(定义流程)
builder.add_edge(START, "analyze_task") # 从分析任务开始
builder.add_edge("analyze_task", "call_llm")
# 条件边:根据是否需要工具调用来路由
builder.add_conditional_edges(
"call_llm",
should_call_tool,
{
"tool_node": "call_llm", # 工具执行后返回 LLM
"call_llm": END # 无需工具,直接结束
}
)
# 编译为可执行图
app = builder.compile()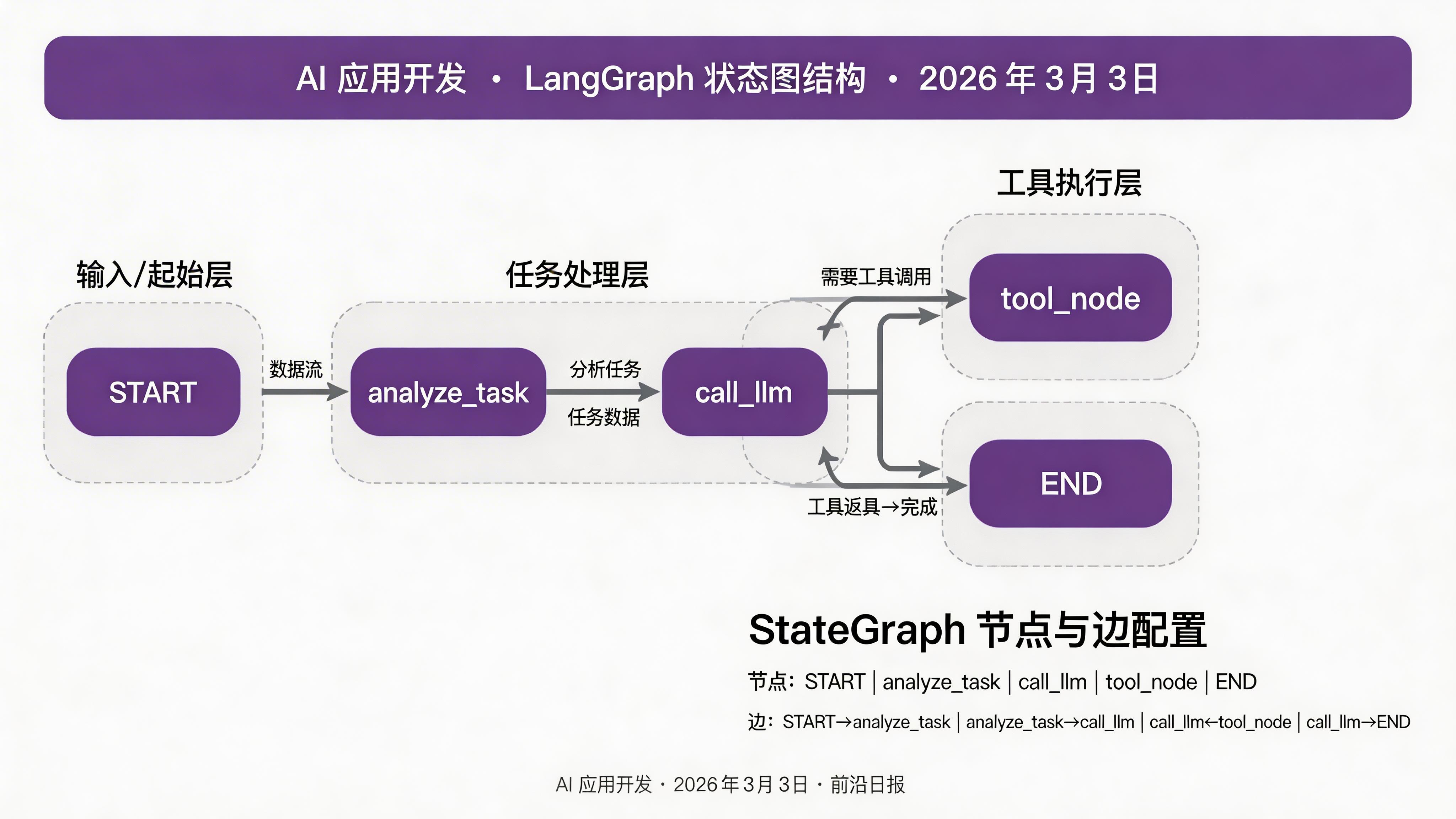
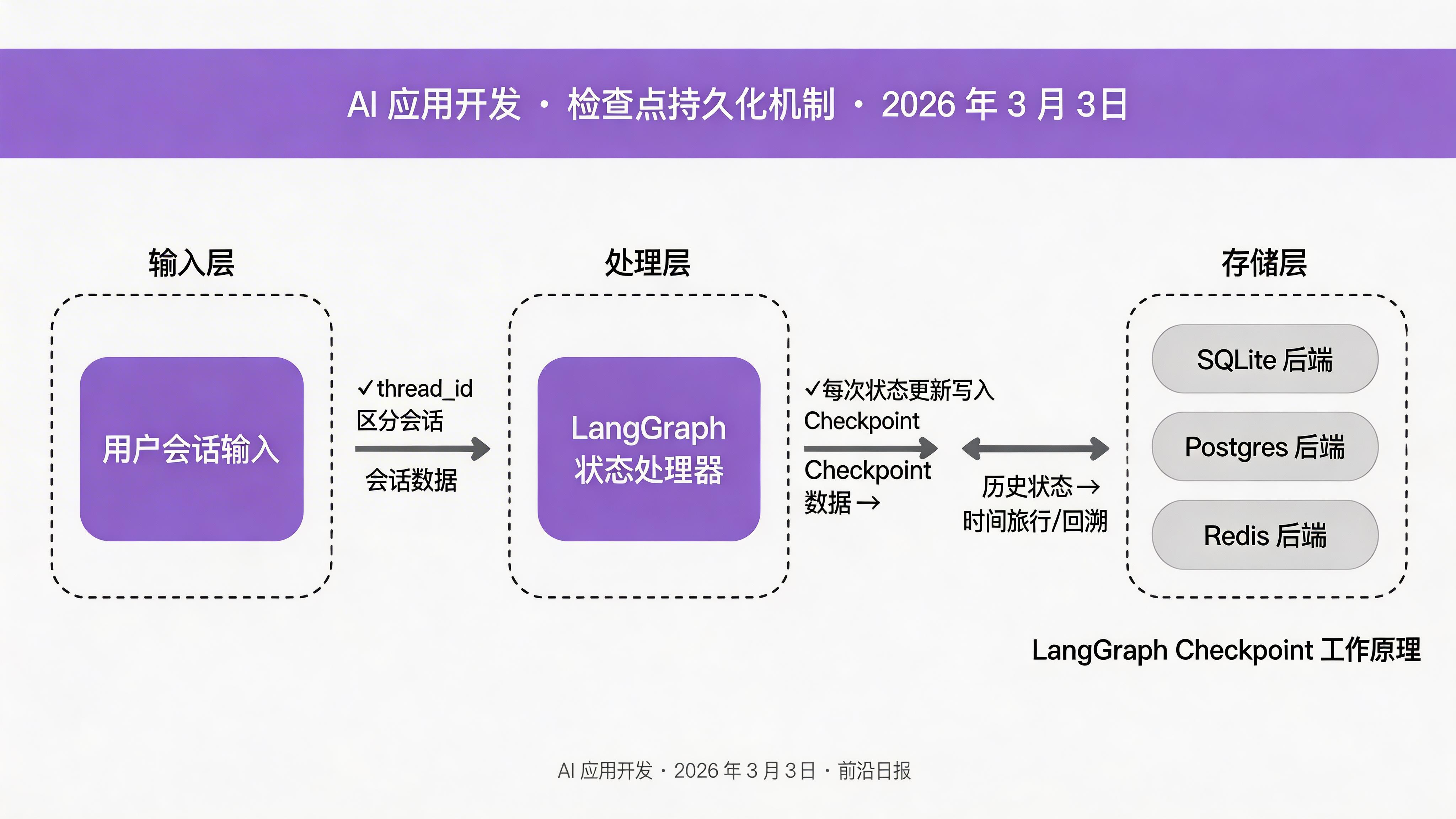
配置持久化检查点
检查点是 LangGraph 的核心特性,它让状态可以跨请求持久化:
from langgraph.checkpoint.sqlite import SqliteSaver
from langgraph.types import Thread
# 配置 SQLite 检查点存储
checkpointer = SqliteSaver.from_conn_string(":memory:") # 生产环境用文件路径
# 重新编译,传入检查点
app = builder.compile(checkpointer=checkpointer)
# 使用线程 ID 区分不同会话
thread_config = {"configurable": {"thread_id": "user-123-session-456"}}
# 运行 - 第一次请求
result1 = app.invoke(
{"messages": [{"role": "user", "content": "帮我分析 Python 异步编程的核心概念"}]},
config=thread_config
)
# 运行 - 后续请求(自动恢复之前的状态)
result2 = app.invoke(
{"messages": [{"role": "user", "content": "继续讲 async/await 的实际应用"}]},
config=thread_config
)检查点不仅保存状态,还支持时间旅行:你可以查看任意历史版本,甚至回滚到过去的状态。
实现人类介入(Human-in-the-Loop)
生产环境中,某些操作需要人类确认。LangGraph 允许在任意节点中断执行:
from langgraph.types import interrupt
def confirm_action(state: State) -> dict:
"""需要人类确认的节点"""
pending_action = state["intermediate_results"][-1]
# 中断执行,等待人类响应
confirmation = interrupt({
"type": "confirmation",
"action": pending_action,
"message": "请确认是否执行此操作"
})
if confirmation:
return {"status": "approved"}
else:
return {"status": "rejected"}
# 添加中断节点
builder.add_node("confirm_action", confirm_action)
# 编译时设置中断点
app = builder.compile(
checkpointer=checkpointer,
interrupt_before=["confirm_action"] # 在执行前中断
)
# 获取待处理的中断
pending_interrupts = app.get_state(thread_config).tasks中断机制在金融审批、医疗诊断等场景中至关重要。
流式输出与事件驱动
LangGraph 支持流式输出和事件订阅,适合实时 UI 和监控:
import asyncio
# 流式获取状态更新
async def stream_execution():
async for event in app.astream(
{"messages": [{"role": "user", "content": "写一个 FastAPI 应用"}]},
config=thread_config,
stream_mode="values" # 流式传输状态值
):
print(f"状态更新:{event['status']}")
print(f"消息数:{len(event['messages'])}")
# 事件驱动:订阅特定事件
async def subscribe_to_events():
async for event in app.astream_events(
{"messages": [{"role": "user", "content": "分析这段代码"}]},
config=thread_config,
version="v2"
):
if event["event"] == "on_chat_model_stream":
print(f"LLM 输出:{event['data']['chunk'].content}")
elif event["event"] == "on_tool_end":
print(f"工具完成:{event['name']}")
asyncio.run(stream_execution())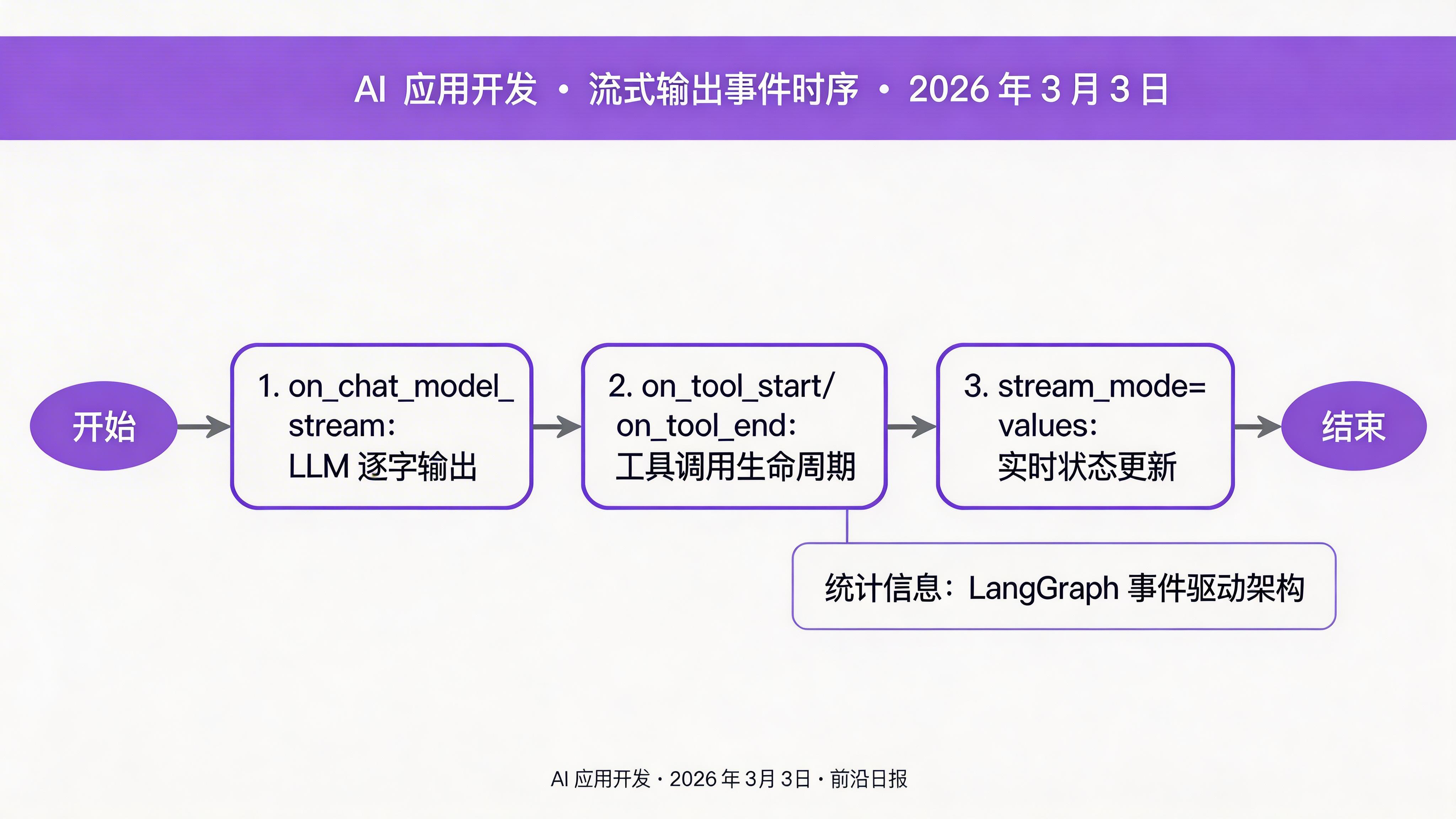
常见问题与解决方案
Q: 如何处理状态过大导致的性能问题?
LangGraph 的状态是累积的。对于大型状态,建议:
- 使用引用而非内联存储大对象(如文件内容)
- 定期清理 messages 列表,保留最近的 N 条
- 将中间结果写入外部存储,状态中只保留引用 ID
Q: 多租户场景下如何隔离状态?
使用复合 thread_id:{user_id}:{session_id}:{workflow_type}。配合数据库索引,可以高效查询特定用户的所有状态。
Q: 如何调试状态图的执行流程?
LangGraph 提供可视化调试工具:
# 获取执行图
graph_png = app.get_graph().draw_mermaid_png()
# 查看完整状态历史
state_history = app.get_state_history(thread_config)Q: 检查点存储支持哪些后端?
官方支持:SQLite(开发)、Postgres(生产)、Redis(高速缓存)、Memory(测试)。也支持自定义实现 LangGraphCheckpointSaver 接口。
总结:掌握 LangGraph 的关键要点
- ✓ 状态定义:用 TypedDict 明确定义 Agent 需要维护的所有数据
- ✓ 节点设计:每个节点应该是纯函数,接收状态返回更新
- ✓ 工具集成:使用 ToolNode 和条件边实现灵活的工具调用路由
- ✓ 持久化:检查点机制让状态可以跨请求恢复
- ✓ 人类介入:interrupt 机制实现审批和审查流程
- ✓ 流式输出:astream 和 astream_events 支持实时交互