痛点:AI Agent 的"失忆症"
你是否遇到过这样的场景:用户与 AI Agent 交互了多次,Agent 却每次都像初次见面一样,完全不记得之前的对话内容、用户偏好或历史上下文?这就是当前大多数 AI Agent 系统的核心痛点——缺乏长期记忆能力。
传统的对话系统依赖有限的 context window,一旦会话结束或超出 token 限制,所有信息都会丢失。这种"金鱼记忆"严重限制了 Agent 的实用价值:无法建立用户画像、无法积累领域知识、无法提供个性化服务。
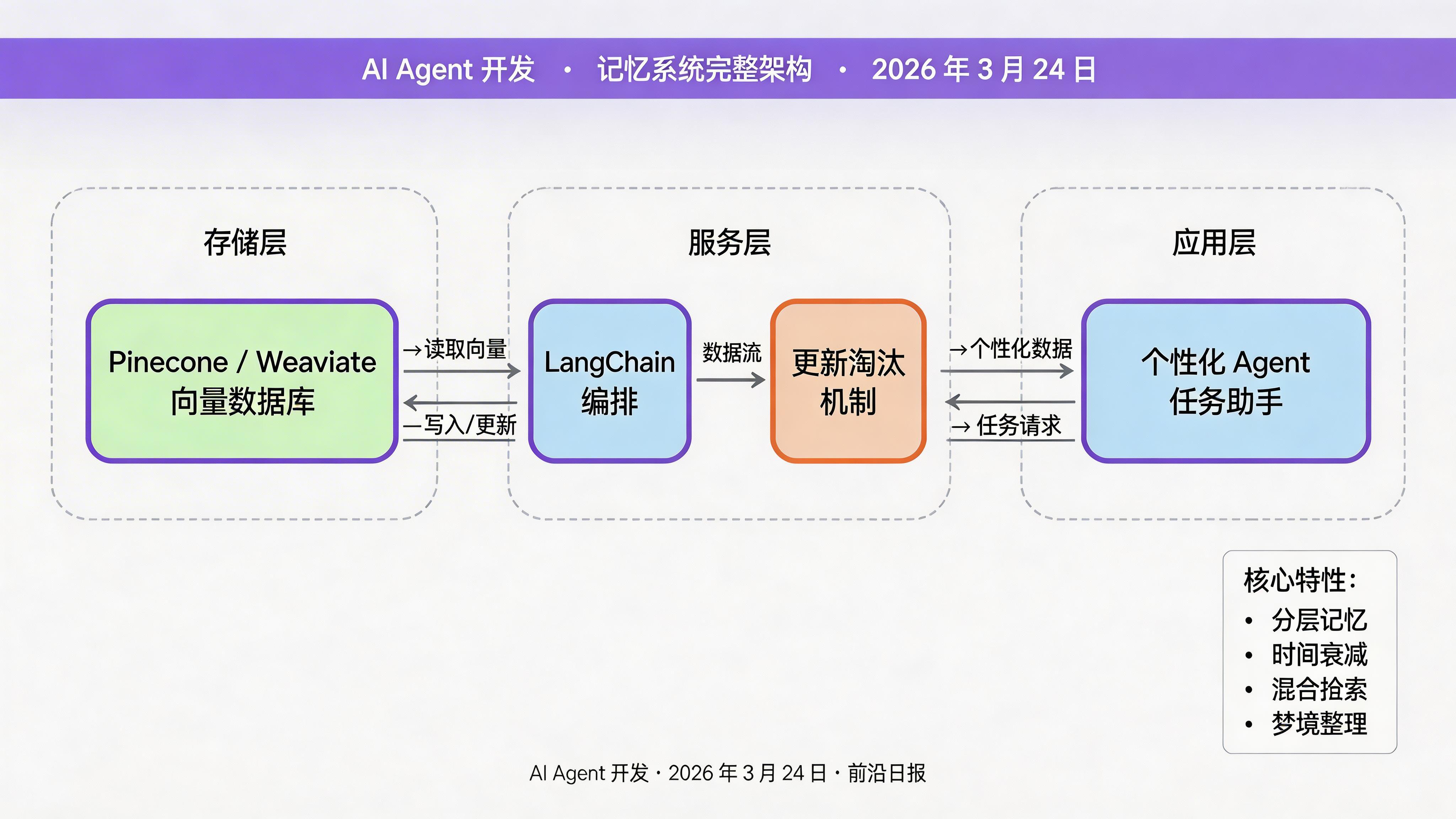
核心概念:AI Agent 记忆系统的三层架构
一个完整的 Agent 记忆系统包含三个核心层次:
- 短期记忆(Short-term Memory):当前会话的上下文,存储在 LLM 的 context window 中
- 工作记忆(Working Memory):当前任务相关的临时信息,支持动态读写
- 长期记忆(Long-term Memory):持久化存储的向量化知识,支持语义检索与跨会话调用
本教程聚焦于长期记忆系统的构建,使用向量数据库作为存储引擎,通过语义相似度实现高效检索。
准备工作:环境搭建与依赖安装
# 创建项目目录
mkdir agent-memory-system && cd agent-memory-system
# 安装核心依赖
pip install langchain langchain-openai pinecone-client
pip install weaviate-client faiss-cpu
pip install python-dotenv pydantic创建环境变量配置文件 .env:
OPENAI_API_KEY=your_openai_api_key
PINECONE_API_KEY=your_pinecone_key
PINECONE_ENVIRONMENT=us-west1-gcp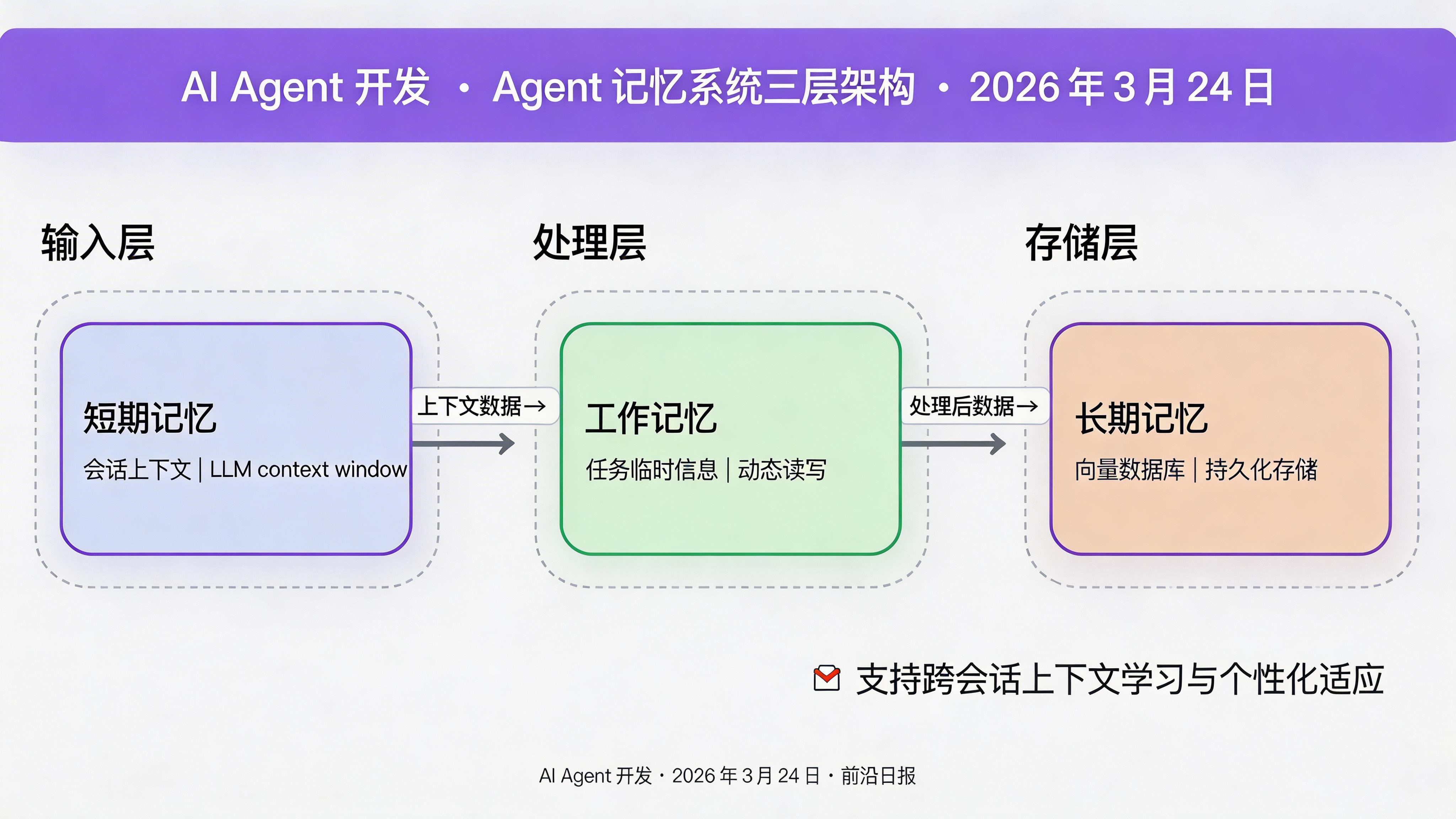
步骤 1:初始化向量数据库与索引创建
选择向量数据库
主流选择包括 Pinecone(托管服务)、Weaviate(开源 + 托管)、Milvus(开源)。本教程以 Pinecone 为例,其他数据库的 API 类似。
创建索引配置
import pinecone
from pinecone import ServerlessSpec
import os
# 初始化 Pinecone 客户端
pinecone.init(
api_key=os.getenv("PINECONE_API_KEY"),
environment=os.getenv("PINECONE_ENVIRONMENT")
)
# 检查索引是否存在
index_name = "agent-memory-system"
existing_indexes = pinecone.list_indexes()
if index_name not in existing_indexes:
# 创建新索引
pinecone.create_index(
name=index_name,
dimension=1536, # OpenAI embeddings 维度
metric="cosine", # 余弦相似度
spec=ServerlessSpec(
cloud="aws",
region="us-west-1"
)
)
print(f"索引 {index_name} 创建成功")连接索引
# 获取索引连接
index = pinecone.Index(index_name)
# 验证连接
stats = index.describe_index_stats()
print(f"索引状态:{stats}")步骤 2:文本向量化与记忆存储
将 Agent 交互过程中的关键信息(用户偏好、任务结果、领域知识)转化为向量并存入数据库。
初始化 Embedding 模型
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-3-large",
dimensions=1536
)定义记忆数据结构
from pydantic import BaseModel, Field
from typing import Optional
from datetime import datetime
class Memory(BaseModel):
"""记忆数据模型"""
id: str = Field(default_factory=lambda: f"mem_{datetime.now().timestamp()}")
content: str # 记忆内容
memory_type: str # 类型:user_preference / task_result / domain_knowledge
created_at: datetime = Field(default_factory=datetime.now)
access_count: int = 0 # 访问次数(用于热度管理)
metadata: Optional[dict] = None # 额外元数据
def to_vector_metadata(self) -> dict:
"""转换为向量元数据格式"""
return {
"memory_type": self.memory_type,
"created_at": self.created_at.isoformat(),
"access_count": self.access_count,
**(self.metadata or {})
}存储记忆到向量数据库
def store_memory(memory: Memory) -> None:
"""将记忆存储到向量数据库"""
# 生成向量
vector = embeddings.embed_query(memory.content)
# 准备元数据
metadata = memory.to_vector_metadata()
metadata["content"] = memory.content # 原始内容也存入
# 存入索引
index.upsert(
vectors=[(memory.id, vector, metadata)]
)
print(f"记忆已存储:{memory.id}")
# 示例:存储用户偏好
user_pref = Memory(
content="用户偏好使用 Python 进行数据分析,常用 pandas 和 numpy 库",
memory_type="user_preference",
metadata={"user_id": "user_123", "domain": "data_science"}
)
store_memory(user_pref)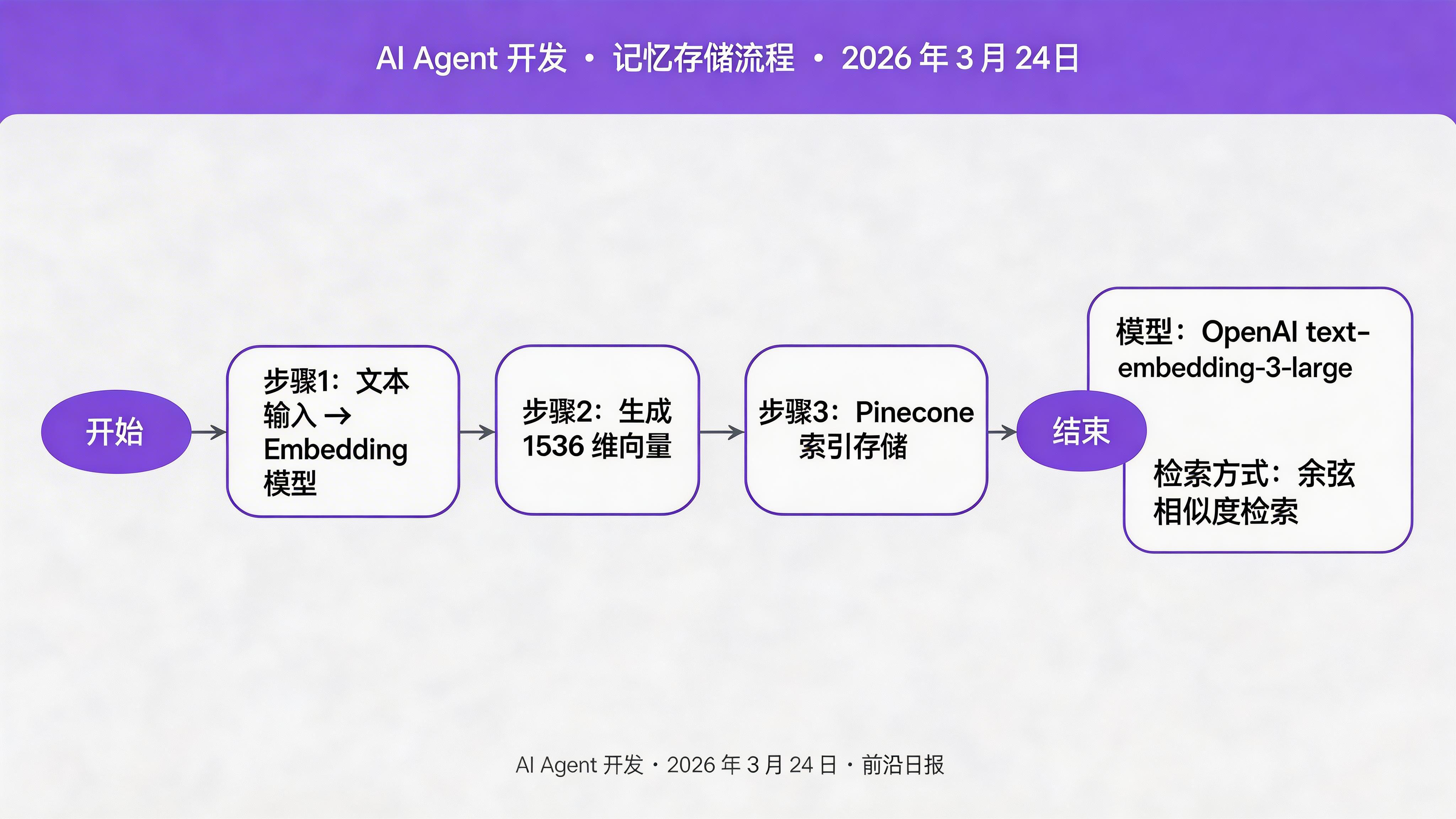
步骤 3:基于相似度的记忆检索机制
当 Agent 处理新任务时,从长期记忆中检索相关的上下文信息。
def retrieve_memories(query: str, top_k: int = 5,
memory_type: Optional[str] = None) -> list:
"""
检索相关记忆
Args:
query: 查询文本
top_k: 返回结果数量
memory_type: 可选的记忆类型过滤
"""
# 生成查询向量
query_vector = embeddings.embed_query(query)
# 构建过滤条件
filter_config = {}
if memory_type:
filter_config["memory_type"] = {"$eq": memory_type}
# 执行相似度检索
results = index.query(
vector=query_vector,
top_k=top_k,
filter=filter_config if filter_config else None,
include_metadata=True
)
# 解析结果
retrieved = []
for match in results.matches:
retrieved.append({
"id": match.id,
"content": match.metadata.get("content", ""),
"memory_type": match.metadata.get("memory_type"),
"score": match.score,
"created_at": match.metadata.get("created_at")
})
return retrieved
# 示例:检索数据分析相关的用户偏好
memories = retrieve_memories(
query="Python 数据分析工具库",
top_k=3,
memory_type="user_preference"
)
for mem in memories:
print(f"[{mem['score']:.2f}] {mem['content']}")步骤 4:集成到 Agent 工作流
将记忆系统嵌入 LangChain Agent 的执行流程中。
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
class MemoryEnhancedAgent:
"""支持长期记忆的 Agent"""
def __init__(self, memory_index, embeddings):
self.index = memory_index
self.embeddings = embeddings
self.llm = ChatOpenAI(model="gpt-4o", temperature=0.7)
def _build_context(self, user_input: str) -> str:
"""构建包含检索记忆的上下文"""
memories = retrieve_memories(user_input, top_k=3)
if not memories:
return ""
context_parts = []
for mem in memories:
context_parts.append(f"- [{mem['memory_type']}]: {mem['content']}")
return "\n相关记忆:\n" + "\n".join(context_parts)
def run(self, user_input: str) -> str:
"""执行 Agent 任务"""
# 检索相关记忆
memory_context = self._build_context(user_input)
# 构建增强 prompt
prompt = ChatPromptTemplate.from_messages([
("system", """你是一个智能助手,具备长期记忆能力。
{memory_context}
请基于以上记忆(如有)回答用户问题。"""),
("user", "{input}")
])
# 执行
chain = prompt | self.llm
response = chain.invoke({
"input": user_input,
"memory_context": memory_context
})
# 存储新记忆(可选)
self._store_if_needed(user_input, response.content)
return response.content
def _store_if_needed(self, user_input: str, response: str) -> None:
"""判断是否需要存储新记忆"""
# 简化实现:提取关键信息存储
if "偏好" in user_input or "记住" in user_input:
memory = Memory(
content=f"{user_input} -> {response}",
memory_type="user_preference"
)
store_memory(memory)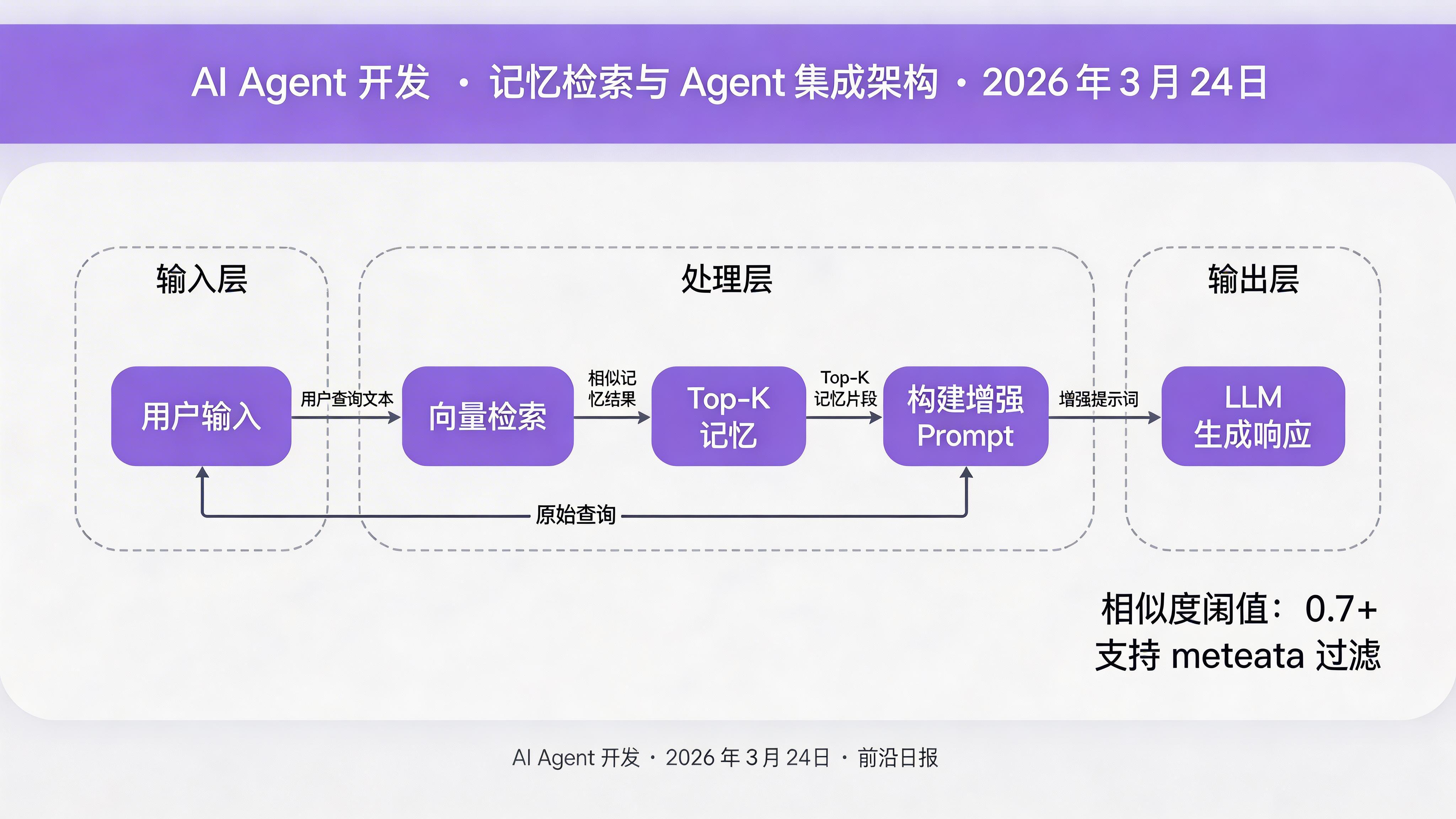
步骤 5:记忆更新与淘汰机制
长期记忆需要动态管理,避免无效信息堆积。
def update_memory_access(memory_id: str) -> None:
"""更新记忆访问计数"""
# 获取当前向量
result = index.fetch(ids=[memory_id])
if memory_id in result.vectors:
vec = result.vectors[memory_id]
metadata = vec.metadata
metadata["access_count"] = metadata.get("access_count", 0) + 1
# 重新存储
index.upsert(vectors=[(memory_id, vec.values, metadata)])
def prune_old_memories(
memory_type: str,
max_age_days: int = 90,
min_access_count: int = 3
) -> int:
"""
清理过期记忆
策略:删除超过 max_age_days 天且访问次数 < min_access_count 的记忆
"""
cutoff_date = datetime.now() - timedelta(days=max_age_days)
# 扫描指定类型的记忆
all_ids = []
# 注意:实际需要通过 list 或 scan 接口获取所有 ID
# 此处为伪代码示意
deleted_count = 0
for mem_id in all_ids:
# 检查元数据
# 如果 created_at < cutoff_date 且 access_count < min_access_count
# 则删除
# index.delete(ids=[mem_id])
deleted_count += 1
return deleted_count步骤 6:实战案例——个性化任务助手
构建一个完整的个性化任务管理 Agent,能够记住用户的工作习惯和偏好。
# 完整示例:个性化任务助手
from datetime import datetime, timedelta
class TaskAgent(MemoryEnhancedAgent):
"""任务管理 Agent"""
def manage_task(self, task_desc: str, user_id: str) -> dict:
# 1. 检索用户历史偏好
prefs = retrieve_memories(
f"用户 {user_id} 工作习惯偏好",
memory_type="user_preference"
)
# 2. 检索类似任务的历史记录
similar_tasks = retrieve_memories(
task_desc,
memory_type="task_result",
top_k=2
)
# 3. 生成任务计划
context = self._build_context(task_desc)
plan = self._generate_plan(task_desc, context, prefs)
# 4. 存储任务结果
result_memory = Memory(
content=f"任务:{task_desc}, 计划:{plan}",
memory_type="task_result",
metadata={"user_id": user_id, "status": "completed"}
)
store_memory(result_memory)
return {"plan": plan, "memories_used": len(prefs) + len(similar_tasks)}
def _generate_plan(self, task: str, context: str, prefs: list) -> str:
# 调用 LLM 生成计划
prompt = f"""
{context}
用户偏好:{prefs}
请为以下任务生成执行计划:
{task}
"""
response = self.llm.invoke(prompt)
return response.content
常见问题与解决方案
Q: 如何处理上下文污染(检索到无关记忆)?
A: 三种策略:(1) 提高相似度阈值(0.7→0.85);(2) 添加更精细的 memory_type 分类;(3) 在 Agent 层添加相关性重排序(re-ranking)步骤。
Q: 向量数据库查询延迟过高怎么办?
A: (1) 使用元数据预过滤减少扫描范围;(2) 选择适当的索引类型(Pinecone Serverless 延迟约 50ms);(3) 实现本地缓存层(如 FAISS)用于高频查询。
Q: 跨用户数据如何隔离?
A: 在 metadata 中添加 user_id 字段,查询时通过 filter 强制隔离:`filter={"user_id": {"$eq": "user_123"}}`。
进阶技巧与最佳实践
- 分层记忆架构:将记忆分为原子记忆(单一事实)、复合记忆(多事实关联)、元记忆(记忆之间的关系)
- 时间衰减权重:检索分数 = 相似度 × 时间衰减因子 × 访问热度
- 混合检索:向量检索 + 关键词检索(BM25)相结合,提升召回率
- 定期"梦境"整理:后台任务定期合并相似记忆、提取模式、删除冗余
- 多模态记忆:扩展系统支持图像、音频等多模态向量的存储与检索
总结
本教程从零构建了一个完整的 Agent 记忆系统,覆盖了以下核心内容:
- ✓ 向量数据库选型与索引创建
- ✓ 文本向量化与记忆存储机制
- ✓ 基于语义相似度的记忆检索
- ✓ LangChain Agent 集成方案
- ✓ 记忆更新、淘汰与热度管理
- ✓ 个性化任务助手实战案例
通过本系统,你的 AI Agent 将具备真正的长期记忆能力,能够跨会话学习用户偏好、积累领域知识、提供个性化服务。