痛点:云端 AI 推理的三大问题
在 2026 年的今天,AI 应用已经无处不在。但大多数开发者仍然依赖云端 API 进行推理,这带来了三个核心痛点:
- 隐私风险:用户数据必须上传到第三方服务器,违反 GDPR 等隐私法规
- 高延迟:网络往返时间 + 排队等待,实时应用体验差
- 成本不可控:按 token 计费,用户量增长时成本线性上升
本教程将教你如何使用 WebAssembly (WASM) 将 AI 模型直接部署到浏览器端运行,实现零服务器依赖、隐私保护、低延迟的边缘推理。
准备工作:工具与环境
Rust + wasm-pack
编译高性能推理引擎到 WASM
WebGPU
浏览器端 GPU 加速,性能提升 10-50 倍
ONNX Runtime
通用模型格式,支持 TensorFlow/PyTorch 导出
Transformers.js v4
Hugging Face 官方浏览器推理库,2026 年新版性能提升 4 倍
核心概念:WASM + WebGPU 架构
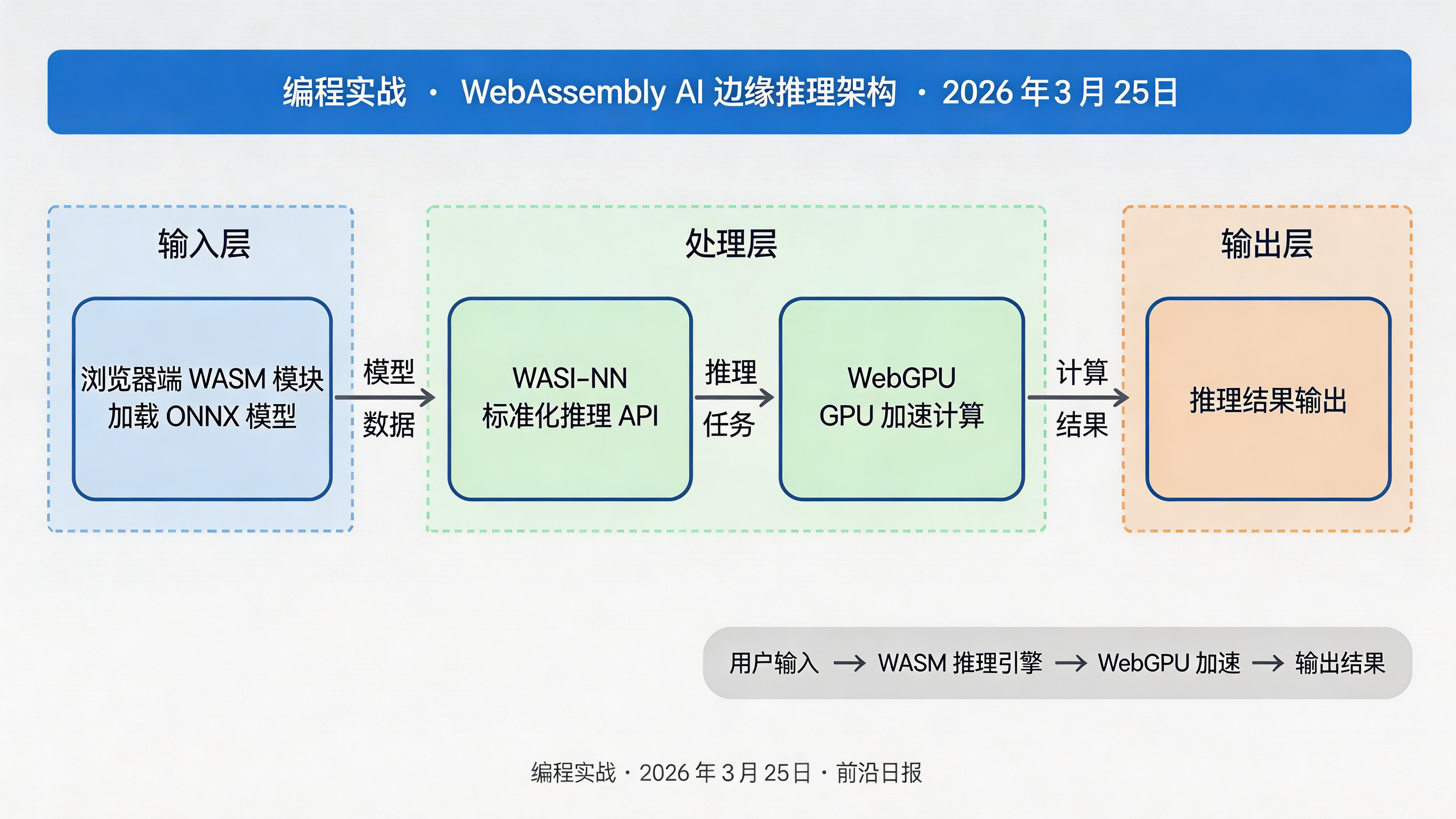
WebAssembly 是一种低级二进制指令格式,可在浏览器中以接近原生的性能运行。结合 WebGPU,我们可以充分利用客户端的 CPU 和 GPU 资源:
- WASM 沙箱:安全的执行环境,无法访问本地文件系统或网络(除非显式授权)
- WebGPU:现代图形 API,支持通用 GPU 计算(GPGPU),适合矩阵运算密集的 AI 推理
- WASI-NN:WebAssembly 系统接口的神经网络扩展,提供标准化的推理 API
实战步骤
1
安装 Rust 和 wasm-pack
# 安装 Rust(如已安装可跳过)
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
# 添加 WASM 编译目标
rustup target add wasm32-unknown-unknown
# 安装 wasm-pack(Rust 到 WASM 的编译工具链)
curl https://rustwasm.github.io/wasm-pack/installer/init.sh -sSf | sh
# 验证安装
wasm-pack --version
提示:wasm-pack 会自动处理 WASM 绑定生成和 npm 包发布,大幅简化工作流。
2
创建 Rust WASM 项目
# 创建新项目
wasm-pack new ai-inference-wasm
cd ai-inference-wasm
# 查看项目结构
# ai-inference-wasm/
# ├── Cargo.toml # Rust 依赖配置
# ├── src/
# │ └── lib.rs # 主要代码入口
# └── pkg/ # 编译输出(生成后)编辑 Cargo.toml 添加 ONNX Runtime 依赖:
[package]
name = "ai-inference-wasm"
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib"]
[dependencies]
wasm-bindgen = "0.2.100"
ort = { version = "2.0", default-features = false, features = ["half"] }
ndarray = "0.16"
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
[profile.release]
lto = true
opt-level = "z"3
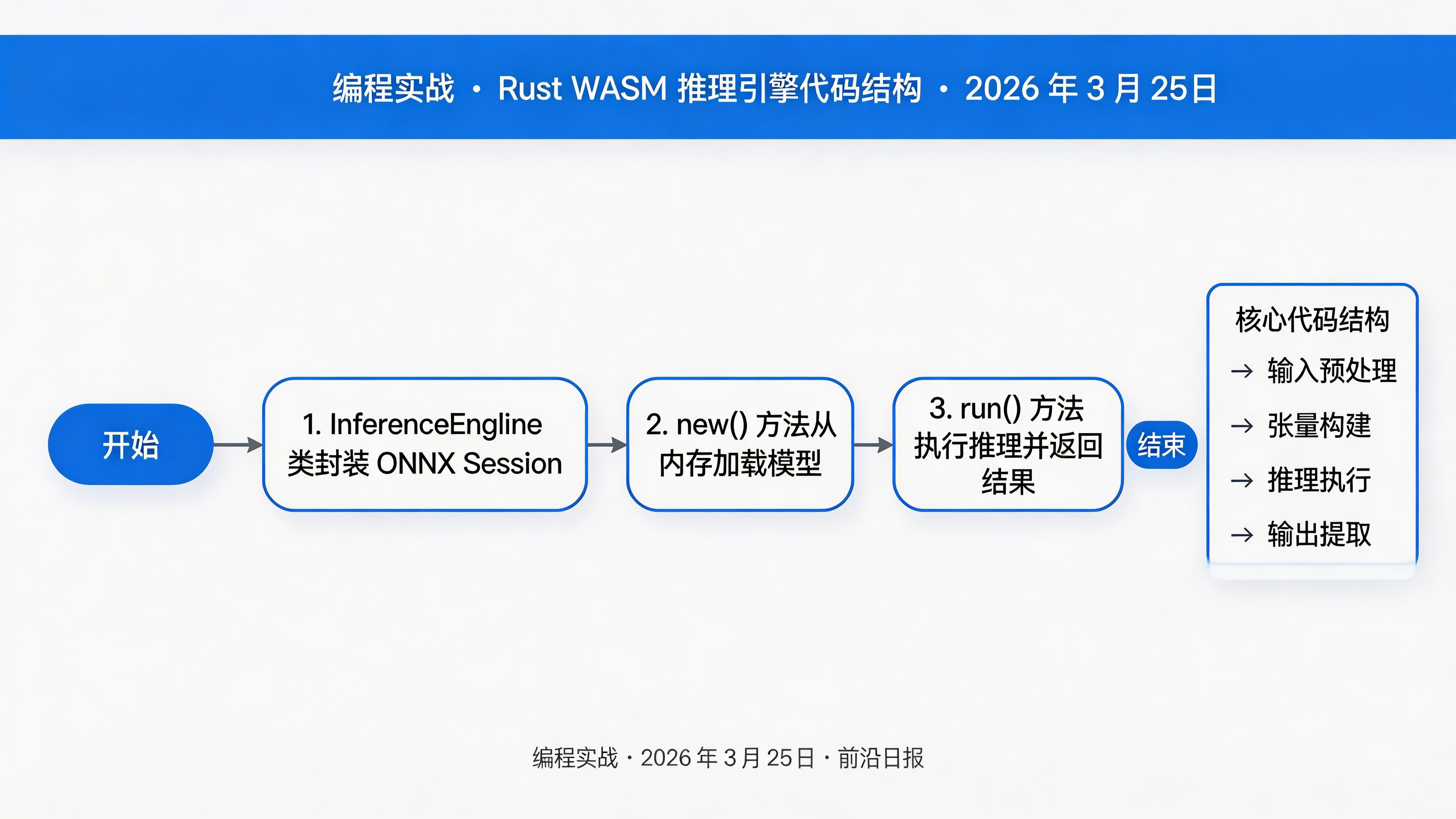
实现推理引擎核心代码
编辑 src/lib.rs,实现模型加载和推理逻辑:
use wasm_bindgen::prelude::*;
use ort::{GraphOptimizationLevel, Session};
use ndarray::{Array, IxDyn};
use serde::{Deserialize, Serialize};
#[wasm_bindgen]
pub struct InferenceEngine {
session: Session,
}
#[wasm_bindgen]
impl InferenceEngine {
#[wasm_bindgen(constructor)]
pub fn new(model_bytes: &[u8]) -> Result {
let session = Session::builder()?
.with_optimization_level(GraphOptimizationLevel::Level3)?
.commit_from_memory(model_bytes)?;
Ok(InferenceEngine { session })
}
pub fn run(&self, input_data: &[f32], input_shape: Vec) -> Result, JsValue> {
// 构建输入张量
let array = Array::from_shape_vec(IxDyn(&input_shape), input_data.to_vec())
.map_err(|e| JsValue::from_str(&format!("Invalid shape: {}", e)))?;
// 执行推理
let outputs = self.session.run(vec![array.into()])?;
// 提取输出
let output_array: Array = outputs[0]
.try_extract_tensor()
.map_err(|e| JsValue::from_str(&format!("Extract failed: {}", e)))?
.to_owned();
Ok(output_array.as_slice().unwrap().to_vec())
}
} 
4
编译为 WASM 模块
# 编译并发布到 pkg 目录
wasm-pack build --target web --release
# 输出文件:
# pkg/
# ├── ai_inference_wasm.js # JavaScript 绑定
# ├── ai_inference_wasm.wasm # WASM 二进制
# ├── package.json
# └── README.md--target web 生成适合浏览器直接使用的 ES6 模块,无需额外打包工具。
5
前端集成:初始化 WebGPU 和 WASM
<!DOCTYPE html>
<html>
<head>
<title>WebAssembly AI 推理演示</title>
</head>
<body>
<input type="file" id="modelInput" accept=".onnx" />
<textarea id="inputData" placeholder="输入文本或上传图片"></textarea>
<button id="runBtn">运行推理</button>
<pre id="output"></pre>
<script type="module">
import init, { InferenceEngine } from './pkg/ai_inference_wasm.js';
async function initWebGPU() {
if (!navigator.gpu) {
throw new Error('WebGPU 不支持,请使用 Chrome 113+ 或 Edge 113+');
}
const adapter = await navigator.gpu.requestAdapter();
const device = await adapter.requestDevice();
return device;
}
async function main() {
// 初始化 WASM
await init();
// 初始化 WebGPU
const gpuDevice = await initWebGPU();
console.log('WebGPU 初始化成功');
// 加载模型
const modelInput = document.getElementById('modelInput');
modelInput.addEventListener('change', async (e) => {
const file = e.target.files[0];
const arrayBuffer = await file.arrayBuffer();
const modelBytes = new Uint8Array(arrayBuffer);
window.engine = new InferenceEngine(modelBytes);
console.log('模型加载成功');
});
}
main();
</script>
</body>
</html>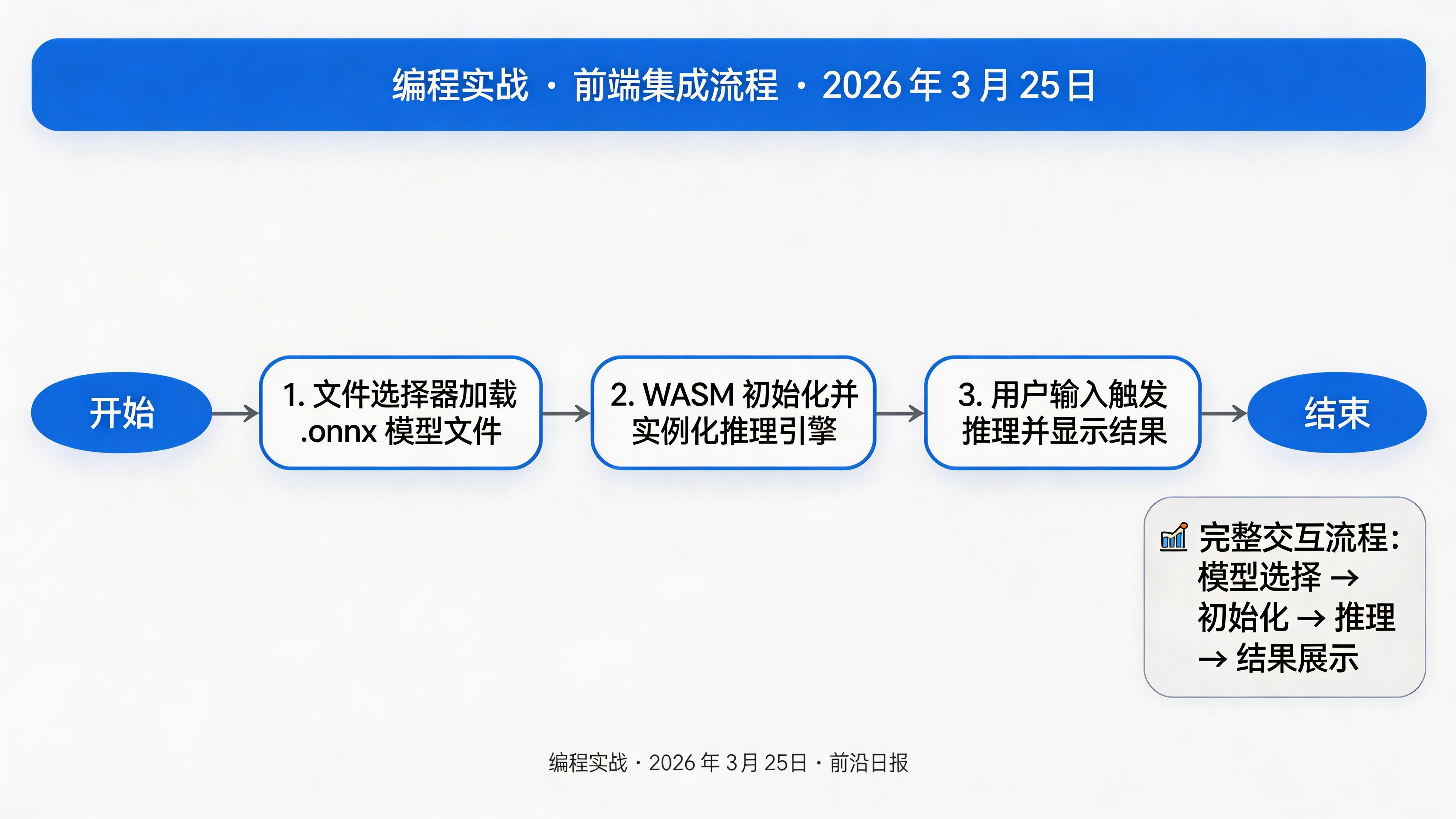
6
实现推理调用逻辑
// 继续上面的 main() 函数
document.getElementById('runBtn').addEventListener('click', async () => {
const inputData = document.getElementById('inputData').value;
// 预处理:将文本转换为 token IDs(简化示例)
const inputIds = tokenize(inputData);
const inputFloats = inputIds.map(id => parseFloat(id));
try {
// 执行推理:输入形状 [batch_size, sequence_length]
const output = window.engine.run(inputFloats, [1, inputIds.length]);
// 后处理:解码输出
const result = decodeOutput(output);
document.getElementById('output').textContent = JSON.stringify(result, null, 2);
} catch (error) {
console.error('推理失败:', error);
document.getElementById('output').textContent = '推理失败:' + error.message;
}
});
// 简化的 tokenizer(实际项目使用 BPE 或 SentencePiece)
function tokenize(text) {
// 实际项目中应使用 @xenova/transformers 库
return text.split(' ').map(word => word.length);
}
function decodeOutput(output) {
// 简化:返回最大概率的索引
const maxIndex = output.indexOf(Math.max(...output));
return { predicted_class: maxIndex, confidence: output[maxIndex] };
}7
使用 Transformers.js 简化集成(替代方案)
如果不想自己编译 WASM 模块,可直接使用 Hugging Face 官方的 Transformers.js v4:
npm install @xenova/transformersimport { pipeline, env } from '@xenova/transformers';
// 禁用从 CDN 下载,使用本地模型
env.allowLocalModels = true;
env.useBrowserCache = true;
// 创建推理管道
const classifier = await pipeline('text-classification', './models/bert-base');
// 执行推理
const result = await classifier('WebAssembly 让 AI 推理更快!');
console.log(result);
// [{ label: 'POSITIVE', score: 0.98 }]
注意:Transformers.js 会自动下载量化后的 ONNX 模型(约 100-500MB),首次加载需要时间。建议将模型放在本地服务器或使用 Service Worker 缓存。
常见问题与解决方案
Q1: 浏览器内存限制导致大模型加载失败
WASM 在浏览器中的内存限制通常为 2GB 或 4GB。解决方案:
- 使用模型量化:将 FP32 模型转换为 INT8,体积减少 75%
- 使用模型剪枝:移除不重要的权重
- 分块加载:使用 WASM 流式加载,分批传输模型
Q2: UI 阻塞问题:长推理导致页面卡顿
使用 Web Worker 将推理任务移至后台线程:
// worker.js
importScripts('./ai_inference_wasm.js');
self.onmessage = async (e) => {
const { modelBytes, inputData } = e.data;
const engine = new InferenceEngine(modelBytes);
const result = engine.run(inputData, [1, 512]);
self.postMessage(result);
};
// 主线程
const worker = new Worker('worker.js');
worker.postMessage({ modelBytes, inputData });
worker.onmessage = (e) => {
console.log('推理结果:', e.data);
};Q3: WebGPU 不支持的设备如何降级处理
检测 WebGPU 支持,降级到 CPU 推理或云端 API:
async function getComputeDevice() {
if (navigator.gpu) {
return 'WebGPU';
} else if ('webgpu' in navigator) {
return 'WebGPU (实验性)';
} else {
return 'CPU (WASM)';
}
}
const device = await getComputeDevice();
console.log('使用设备:', device);
// 根据设备选择不同的推理后端
if (device === 'CPU (WASM)') {
// 降级到 ONNX Runtime Web 或云端 API
}性能优化与最佳实践
- 模型量化:使用 ONNX Runtime 的 quantize_dynamic 工具将 FP32 转为 INT8,精度损失<1%,速度提升 2-4 倍
- Web Workers:将推理移至后台线程,避免阻塞主线程 UI
- Service Worker 缓存:缓存 WASM 模块和模型文件,二次加载速度提升 10 倍
- 流式加载:使用 WebAssembly.instantiateStreaming 边下载边编译
- 混合架构:简单模型本地推理,复杂模型卸载到云端

总结
通过本教程,你学会了如何使用 WebAssembly 和 WebGPU 将 AI 模型部署到浏览器端运行。这种边缘推理架构具有三大优势:
- ✓ 隐私保护:用户数据无需离开本地设备
- ✓ 低延迟:消除网络往返,推理响应时间从秒级降至毫秒级
- ✓ 成本可控:按用户设备计算,无需为云端 API 付费
2026 年是边缘 AI 的爆发年,WebAssembly + WebGPU 的组合已经足够成熟,可以支持从文本分类到图像生成的多种 AI 任务。开始构建你的浏览器端 AI 应用吧!