为什么需要可视化 RAG + Agent 工作流
在构建企业级 RAG(检索增强生成)系统时,开发者常常面临以下挑战:
- 代码复杂度高:需要同时处理向量数据库、LLM 调用、Agent 逻辑 orchestration
- 调试困难:多步骤流程中某个环节失败,难以定位问题所在
- 迭代缓慢:每次调整检索策略或 Agent 行为都需要修改代码并重新部署
- 缺乏可视化:团队成员难以理解整体数据流向和决策逻辑
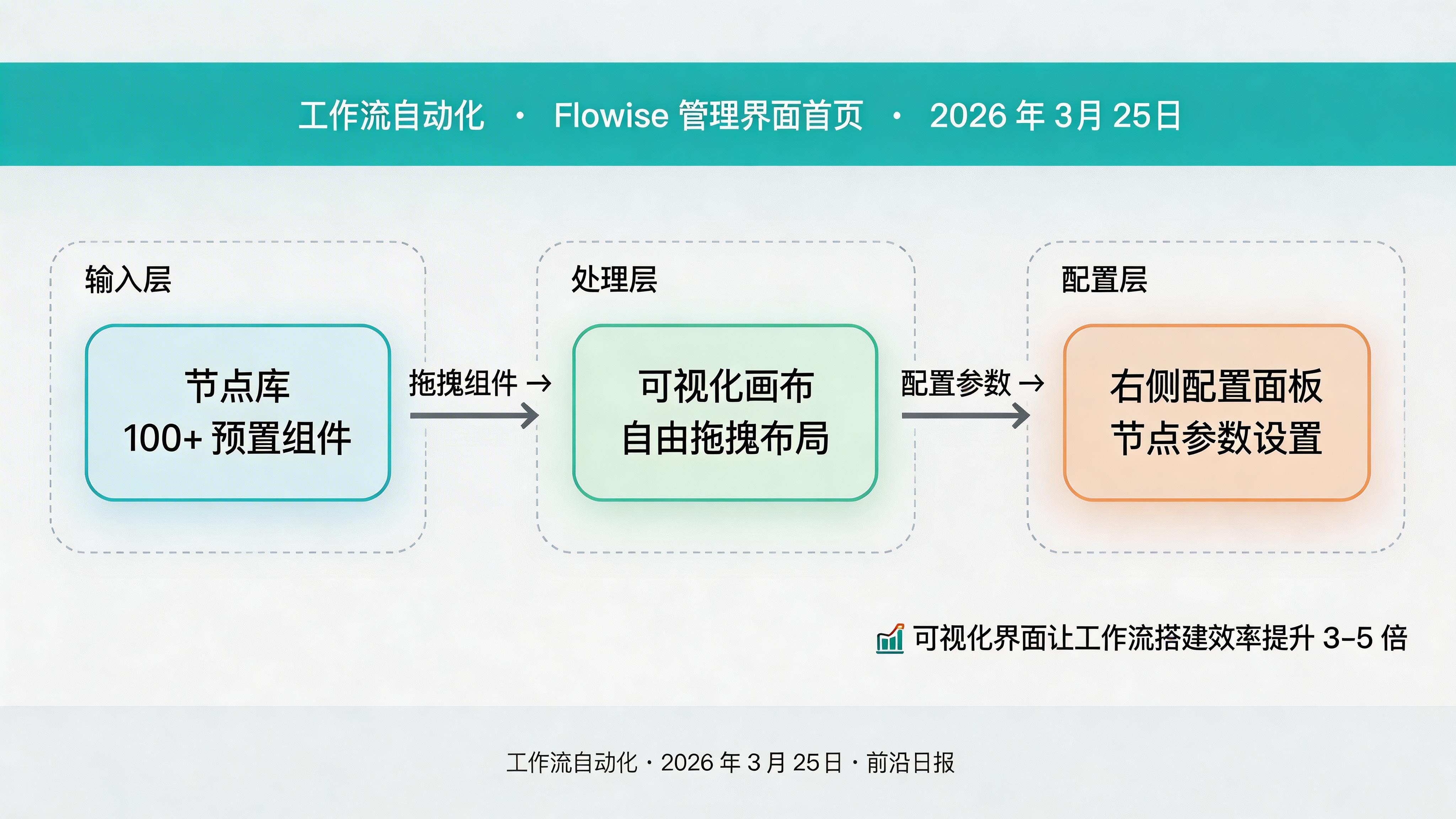
Flowise 1.5 的发布正是为了解决这些问题。作为一个开源低代码平台,Flowise 提供了超过 100 个预置节点,支持在 AWS、Azure、GCP 上自托管,让你可以通过拖拽方式快速构建复杂的 AI 工作流。
💡 本教程将带你从零开始,使用 Flowise 1.5 构建一个支持自我修正的 RAG + Agent 混合工作流。当检索结果不相关时,系统会自动重新生成查询并重试,最多支持 5 次迭代优化。
准备工作:环境与依赖
在开始之前,请确保你的开发环境满足以下要求:
步骤 1:部署 Flowise 1.5
使用 Docker Compose 快速部署
创建 docker-compose.yml 文件:
version: '3.8'
services:
flowise:
image: flowiseai/flowise:latest
ports:
- "3000:3000"
environment:
- PORT=3000
- DATABASE_TYPE=sqlite
- DATABASE_PATH=/flowise/sqlite.db
- APIKEY_PATH=/flowise/apikeys
- SECRETKEY_OVERWRITE=your-secret-key-here
- LOG_LEVEL=INFO
volumes:
- ./flowise-data:/flowise
restart: unless-stopped启动服务:
docker-compose up -d访问 http://localhost:3000 即可看到 Flowise 管理界面。
步骤 2:配置环境变量与 API 密钥
设置 LLM 凭证
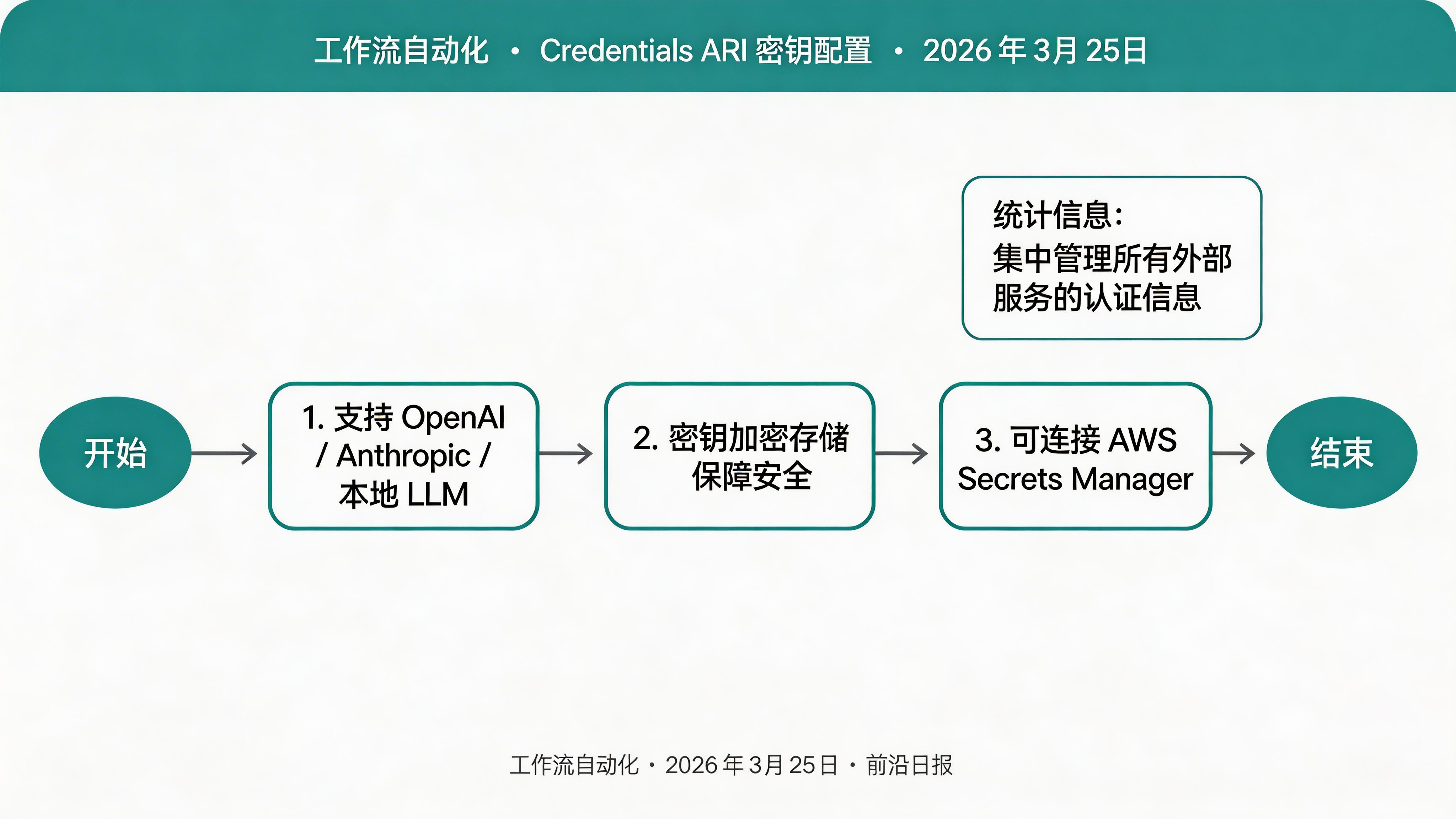
在 Flowise 界面中,点击左侧菜单的 "Credentials" → "Add New Credential":
- Name: OpenAI API Key
- Type: OpenAI API
- API Key: 填入你的
sk-...密钥
⚠️ 生产环境建议使用加密的密钥管理服务(如 AWS Secrets Manager),避免将敏感信息硬编码在配置文件中。
步骤 3:构建 Agentic RAG 工作流
添加 Start 节点(流程入口)
从左侧节点库拖拽 "Start" 节点到画布:
- Input Type: Chat Input
- Variables: 添加变量
query(类型:String)
{
"id": "start_1",
"type": "start",
"inputType": "chatInput",
"variables": [
{ "name": "query", "type": "string" }
]
}
添加 Condition Agent(查询分类路由)
添加 "Condition Agent" 节点,用于将用户查询路由到不同分支:
- AI 相关查询 → 进入 RAG 检索流程
- 通用查询 → 直接使用 LLM 回答
{
"conditionAgent": {
"conditions": [
{
"name": "AI Related",
"criteria": "query contains keywords about AI, machine learning, or data science"
},
{
"name": "General",
"criteria": "all other queries"
}
]
}
}
添加 Query Generator LLM(优化检索查询)
为 AI 相关查询分支添加 LLM 节点,将用户原始查询转换为更适合向量检索的格式:
// System Prompt 示例
你是一个查询优化专家。将用户的问题改写为更适合向量数据库检索的格式:
1. 提取核心概念和关键词
2. 移除口语化表达
3. 保持技术术语的准确性
原始查询:{{query}}
优化后的查询: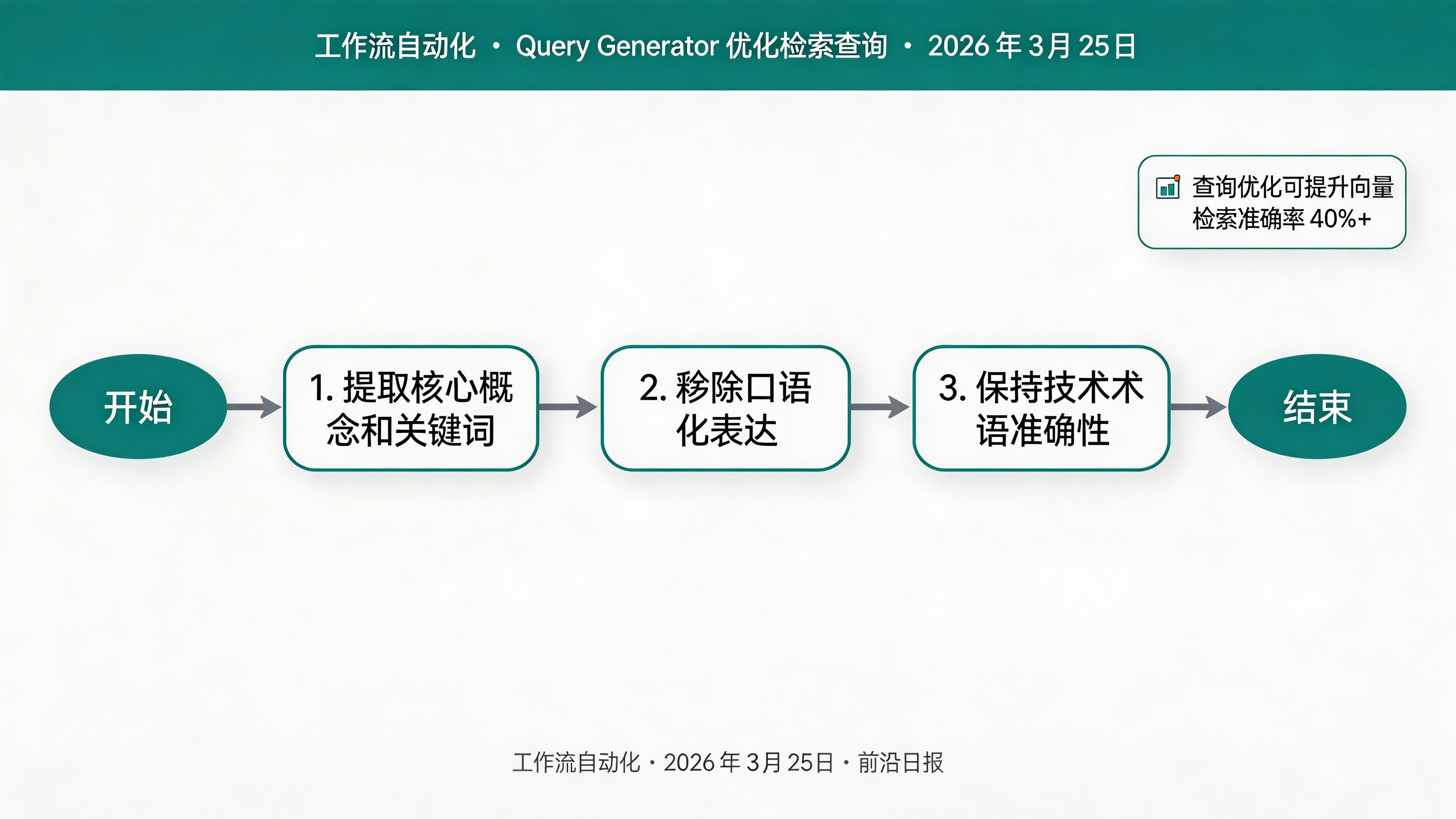
添加 Retriever 节点(向量检索)
连接向量数据库检索器:
- Vector Store: 选择 ChromaDB / Pinecone
- Top K: 5(返回最相关的 5 个文档片段)
- Threshold: 0.7(相似度阈值)
retriever:
type: vectorStore
config:
store: chromadb
collection: tech-docs
topK: 5
threshold: 0.7
添加 Relevance Checker(相关性判断)
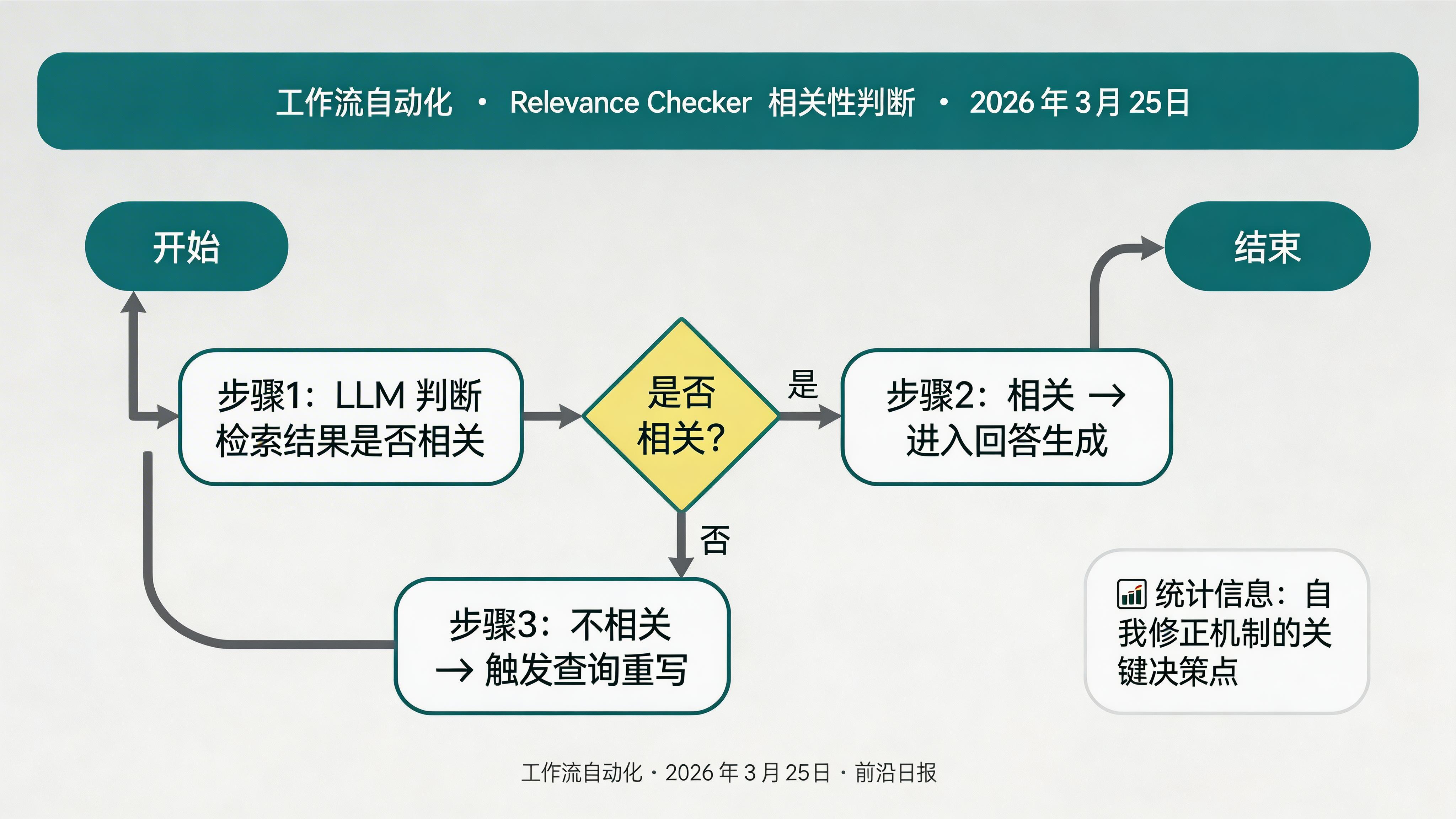
使用 LLM 判断检索结果是否与查询相关:
// Relevance Checker Prompt
请判断以下检索结果是否与用户查询相关:
用户查询:{{optimized_query}}
检索结果:{{retrieved_docs}}
如果相关,输出"RELEVANT"并提取关键信息;
如果不相关,输出"IRRELEVANT"并说明原因。相关 → 进入最终回答生成;不相关 → 进入查询重写环节。
添加 Loop 节点(自我修正循环)
当检索结果不相关时,系统自动重试:
- Max Iterations: 5
- Query Rewriter: 根据不相关原因调整查询策略
{
"loopNode": {
"maxIterations": 5,
"onIrrelevant": {
"action": "rewrite_query",
"feedback": "检索结果缺少关键概念 {{missing_concept}}"
}
}
}这是 Flowise 1.5 的核心特性之一——自修正循环,能够显著提升 RAG 系统的回答准确率。
添加最终回答生成 LLM
整合检索结果,生成最终回答:
// Answer Generator Prompt
基于以下检索结果,回答用户的问题:
原始查询:{{query}}
优化查询:{{optimized_query}}
检索结果:
{{retrieved_docs}}
要求:
1. 引用来源文档编号
2. 如信息不足,明确说明
3. 保持回答简洁专业
完整工作流架构
完成上述步骤后,你的工作流应该呈现以下结构:
💡 你可以点击右上角的 "Export" 按钮将整个工作流导出为 JSON 文件,方便版本控制和团队共享。
常见问题与解决方案
进阶技巧与最佳实践
- 版本控制: 定期 Export 工作流 JSON 并纳入 Git 管理,记录每次迭代的变更
- Prompt 工程: 为 Query Generator 和 Relevance Checker 设计高质量的 System Prompt,这是提升准确率的关键
- 监控与日志: 在生产环境使用 LOG_LEVEL=DEBUG,便于问题排查
- 性能优化: 对于高频查询,添加缓存层避免重复检索
- 安全加固: 使用 API Gateway 保护 Flowise 端点,配置速率限制和认证
总结
通过本教程,你掌握了使用 Flowise 1.5 构建 RAG + Agent 混合工作流的完整流程:
- 使用 Docker Compose 快速部署 Flowise 环境
- 配置 LLM 凭证和向量数据库连接
- 构建包含查询优化、相关性判断、自我修正循环的智能工作流
- 掌握常见问题的排查方法和最佳实践
Flowise 1.5 的可视化界面让复杂的 AI 工作流变得直观可管理,特别适合需要快速原型验证和迭代优化的团队。相比纯代码方案,开发效率可提升 3-5 倍。