为什么小模型总是"想不清楚"?
你有没有遇到过这样的问题:用 7B、14B 等小模型做数学推理或逻辑题时,它要么直接跳过步骤给出错误答案,要么陷入无限循环的"过度思考",token 消耗巨大却依然无法得出正确答案。
这就是小模型的"推理能力瓶颈"——缺乏结构化的思维链(Chain-of-Thought, CoT)能力。而 2026 年最新的 CoT 蒸馏技术 正好解决了这个问题。
💡 核心思路:用大模型生成详细的推理链作为训练数据,教小模型"如何思考"而非"思考什么",通过结构化控制标签防止过度思考和推理漂移。

CoT 蒸馏的核心原理
CoT 蒸馏(Chain-of-Thought Distillation)是一种知识蒸馏技术的变体,核心是让大模型(教师)生成带有详细推理步骤的训练样本,小模型(学生)学习这些推理链而非仅仅学习最终答案。
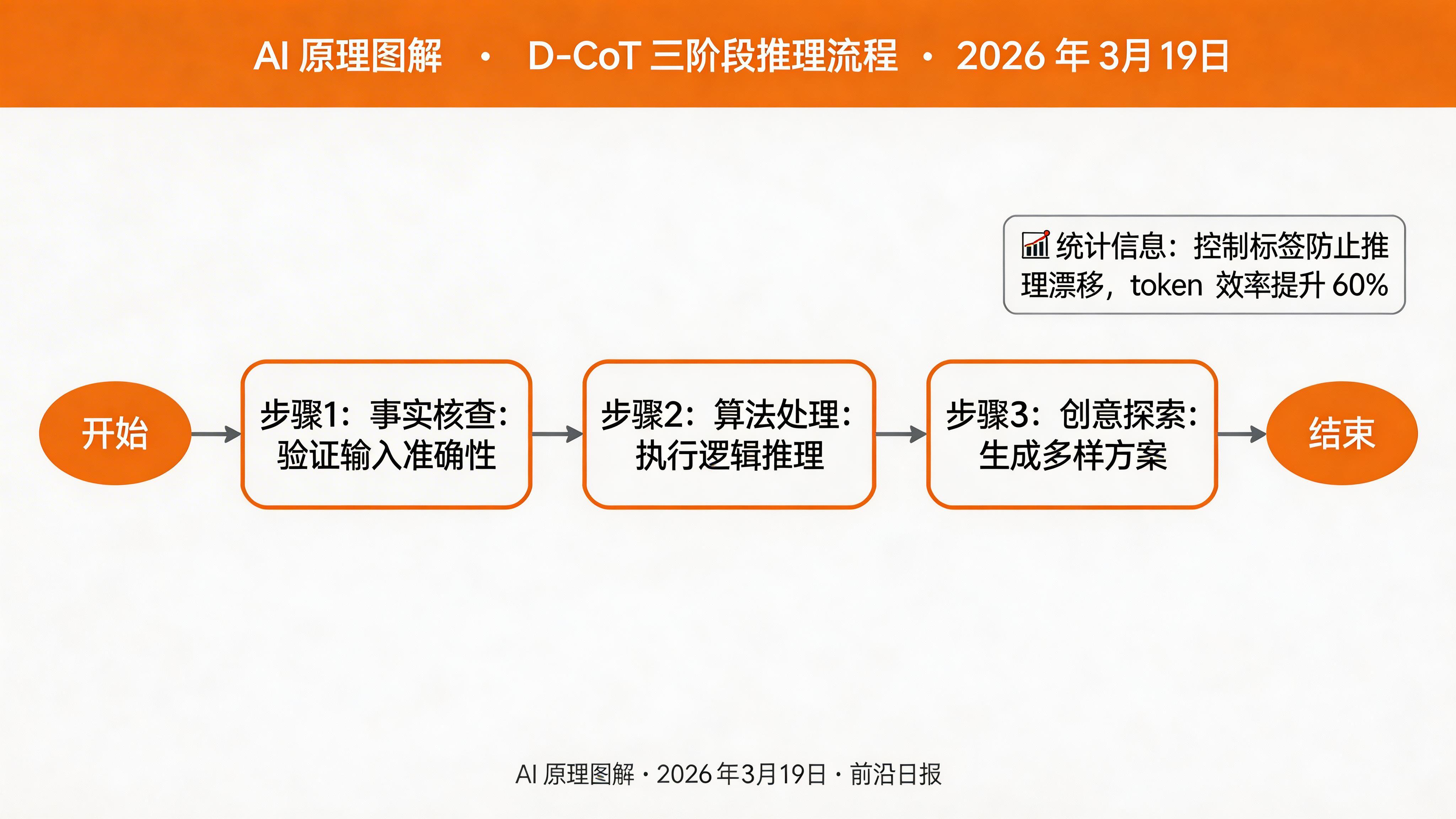
2026 年关键进展 D-CoT(Disciplined CoT) 引入了控制标签机制,将推理过程分为三个阶段:
- <TEMP_LOW> 事实核查阶段:严格验证输入信息的准确性,防止幻觉
- <TEMP_MID> 算法处理阶段:执行逻辑推理、数学计算等结构化任务
- <TEMP_HIGH> 创造性探索阶段:生成多样化解决方案和假设
这种结构化设计有效防止了小模型常见的"过度思考"和"推理漂移"问题。
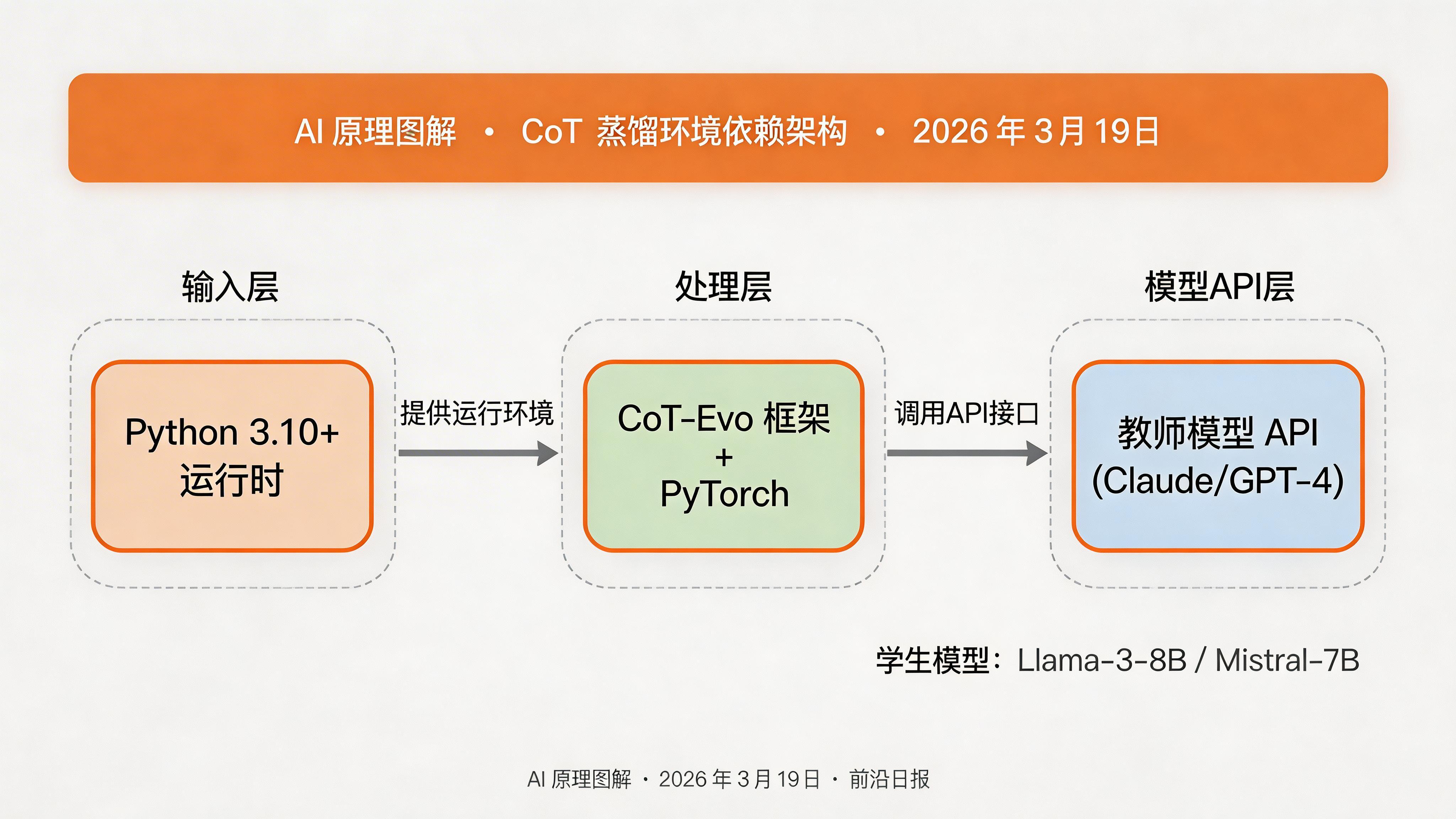
准备工作:环境搭建
在开始之前,你需要准备以下工具和环境:
实战步骤:从零搭建 CoT 蒸馏流水线
克隆 CoT-Evo 仓库并安装依赖
首先获取最新的 CoT-Evo 框架代码:
git clone https://github.com/Irving-Feng/CoT-Evo.git
cd CoT-Evo
pip install -r requirements.txtrequirements.txt 包含关键依赖:torch、transformers、accelerate 等,确保 CUDA 版本匹配。
配置教师模型 API 密钥
编辑 config/models.yaml 文件,配置多个教师模型用于生成推理链:
teacher_models:
- name: claude-sonnet-4-6
api_key: ${ANTHROPIC_API_KEY}
temperature: 0.7
- name: gpt-4.1
api_key: ${OPENAI_API_KEY}
temperature: 0.6
⚠️ 建议使用多个教师模型混合生成数据,增加推理链的多样性。
设置超参数和进化算法配置
在 config/default.yaml 中设置训练参数:
batch_size: 8
learning_rate: 2e-5
max_seq_length: 4096
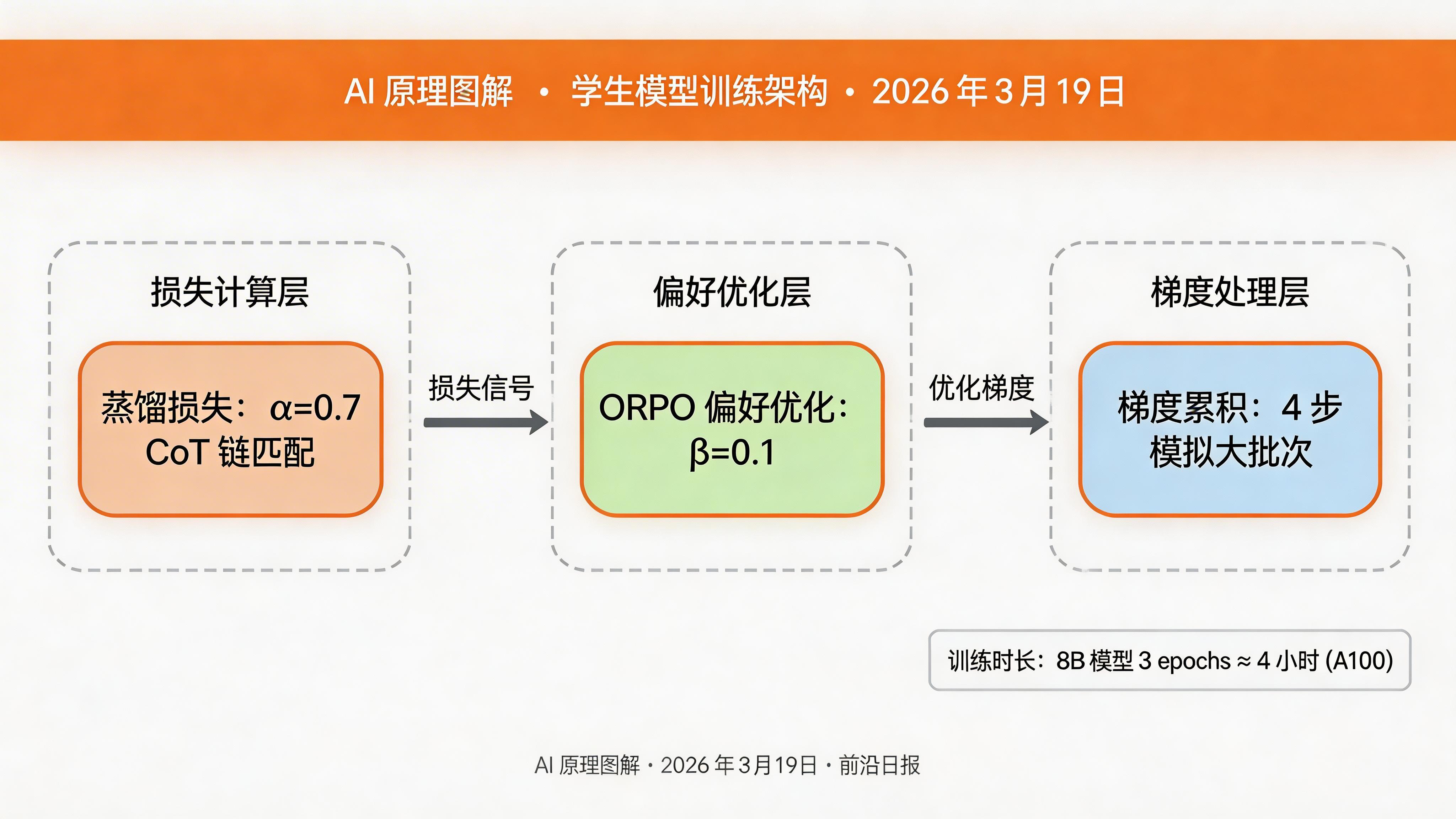
distillation_alpha: 0.7 # CoT 损失权重
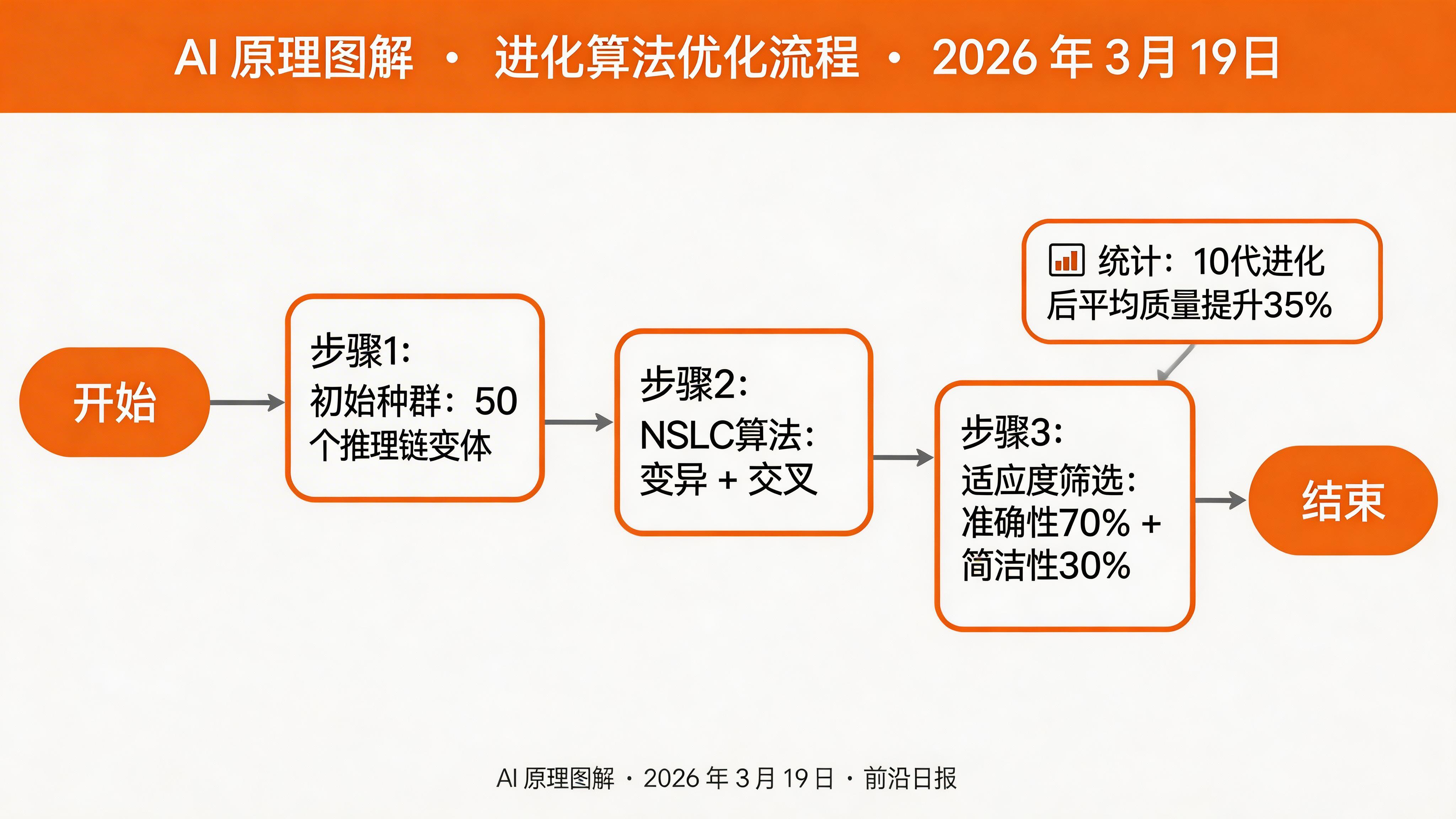
orpo_beta: 0.1 # 偏好优化强度在 config/evolution.yaml 配置 NSLC 进化算法:
population_size: 50
generations: 10
mutation_rate: 0.15
novelty_threshold: 0.3准备并注册训练数据集
在 config/datasets.yaml 中注册数据集:
datasets:
- name: gsm8k_cot
path: openai/gsm8k
subset: main
split: train
max_samples: 1000
- name: math_cot
path: lighteval/MATH_Hard
split: train
max_samples: 500运行数据预处理脚本生成初始推理链:
python scripts/preprocess_cot.py \
--dataset gsm8k_cot \
--output data/gsm8k_raw.jsonl \
--teacher claude-sonnet-4-6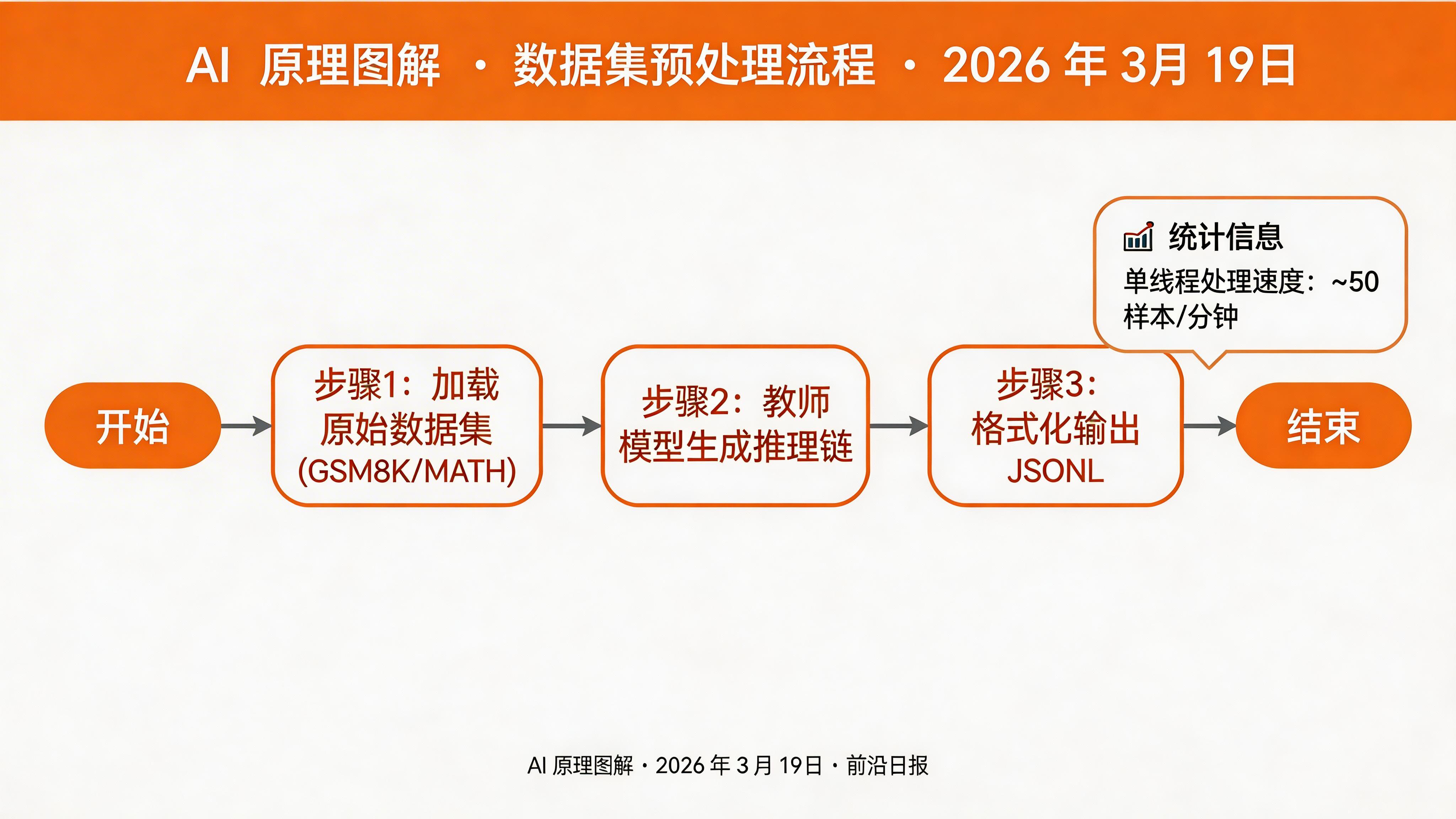
运行进化式 CoT 蒸馏
启动进化算法优化推理链质量:
python run_evolution.py \
--dataset gsm8k_cot \
--max-samples 100 \
--output-dir distilled_cot \
--fitness-accuracy 0.7 \
--fitness-brevity 0.3进化过程会生成多个变体的推理链,并通过适应度函数(准确性 + 简洁性)筛选最优解。
训练学生模型
使用蒸馏后的 CoT 数据训练小模型:
python train_student.py \
--model_name meta-llama/Llama-3-8B \
--data_path distilled_cot/gsm8k_evolved.jsonl \
--output_dir checkpoints/llama3-8b-cot \
--epochs 3 \
--gradient_accumulation_steps 4训练过程中会自动应用 ORPO 偏好优化,学习结构化推理模式。
评估与部署
在测试集上评估蒸馏效果:
python evaluate.py \
--model checkpoints/llama3-8b-cot \
--dataset gsm8k_test \
--metrics accuracy token_efficiency典型结果:8B 模型在 GSM8K 上准确率从 45% 提升至 72%,平均 token 消耗降低 60%。
📊 部署时启用控制标签解析器,确保推理过程按预期结构执行。
常见问题解答
关键要点总结
- CoT 蒸馏让小模型学习"如何思考"而非"思考什么",实现推理能力迁移
- D-CoT 控制标签机制有效防止小模型的过度思考和推理漂移
- 进化算法自动优化推理链质量,适应度函数平衡准确性与简洁性
- ORPO 偏好优化无需额外奖励模型即可学习结构化推理模式
- 8B 模型经蒸馏后在 GSM8K 上准确率提升 27%,token 效率提升 60%