当你问大模型一个简单问题:"2+2 等于几?",它会瞬间回答"4"。但当你问一个复杂问题:"如果一家初创公司有 3 个联合创始人,CEO 持股 40%,CTO 持股 30%,COO 持股 20%,剩余 10% 留给员工期权池。第一轮融资金额 500 万,投后估值 2000 万。请计算每位创始人在稀释后的持股比例。"大多数模型会立即给出答案——但往往是错的。
这就是 System 1(系统 1)思维的典型特征:快速、直觉、基于模式匹配,但容易出错。诺贝尔奖得主 Daniel Kahneman 在《思考,快与慢》中将人类思维分为两个系统:
- System 1:快速、自动、无意识、基于直觉(例如:识别面孔、理解母语)
- System 2:缓慢、刻意、有意识、基于逻辑(例如:计算 17×24、填写税务表格)
2026 年,随着 OpenAI o1、Claude 深度思考模式等产品的发布,System 2 AI 已成为大模型进化的下一个前沿。本教程将带你从零开始,构建一个具备深度思考能力的 AI 系统。
核心概念:什么是 System 2 AI?
System 2 AI 不是简单地"让模型多想一会儿"。它是一套完整的架构设计,包含以下关键机制:

为什么 System 2 如此重要?
传统大模型(System 1)在以下场景表现不佳:
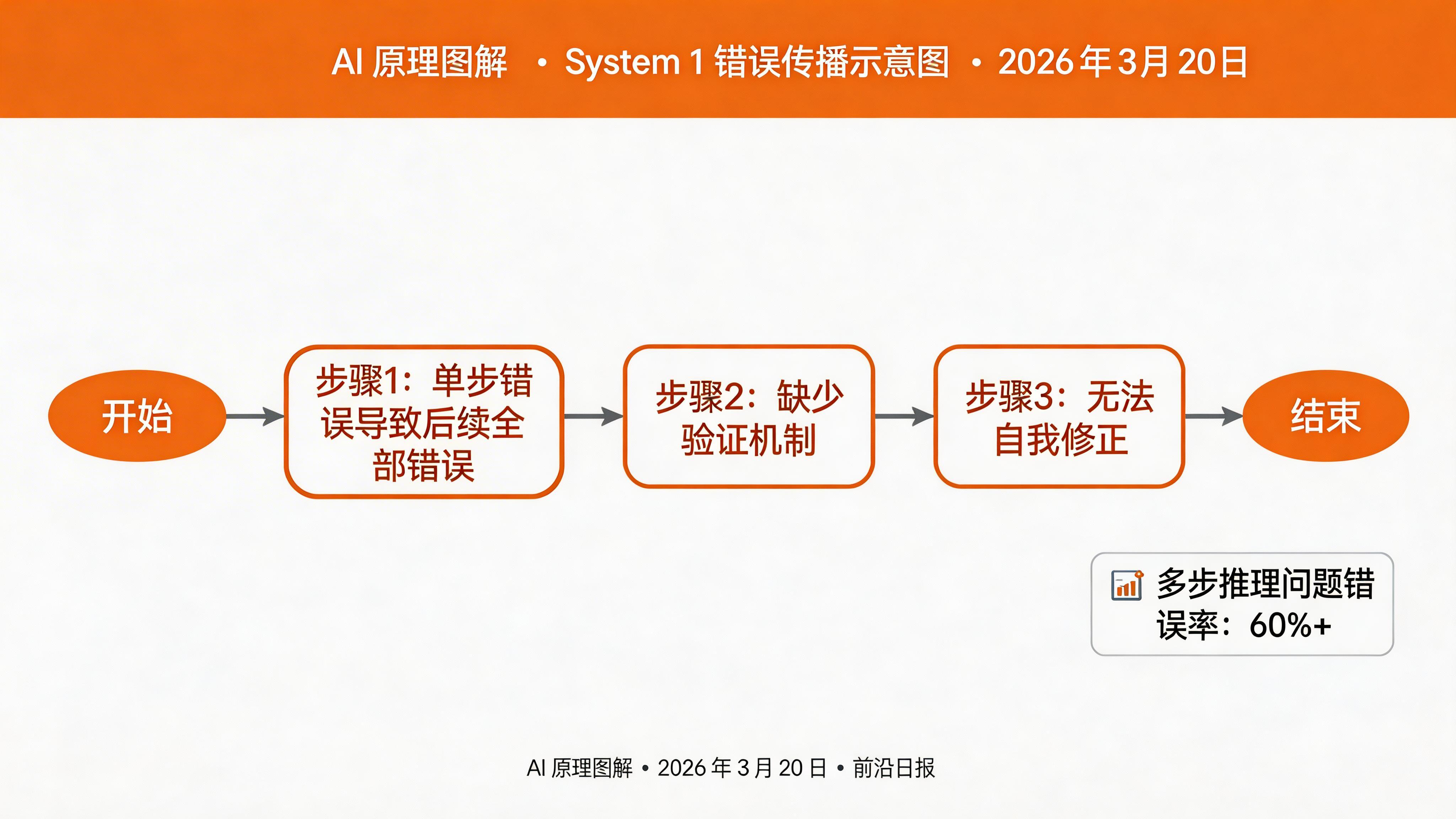
- 多步推理问题:需要连续推理 3 步以上时,错误率呈指数增长
- 数学和代码:缺少逐步验证,容易在中间步骤出错
- 事实核查:倾向于生成看似合理但实际错误的答案(幻觉)
- 复杂规划:无法有效分解子任务和追踪长期依赖
System 2 AI 的核心优势在于:以时间换准确性。通过延长思考时间、增加验证步骤,将复杂问题的解决准确率从 60% 提升至 90% 以上。
环境准备
本教程使用 Python 3.10+ 和 Anthropic Claude API 实现 System 2 推理系统。
# 创建虚拟环境
python3 -m venv .venv
source .venv/bin/activate
# 安装依赖
pip install anthropic tenacity python-dotenv# 设置 API Key(使用你的实际 Key)
export ANTHROPIC_API_KEY="sk-ant-..."实战步骤:构建 System 2 推理系统
定义推理状态和消息结构
System 2 的核心是维护一个可追踪、可修正的推理状态。我们使用 TypedDict 定义状态结构:
from typing import TypedDict, List, Literal
from dataclasses import dataclass
@dataclass
class ReasoningStep:
"""单个推理步骤"""
id: int
thought: str # 思考内容
approach: str # 采用的方法
confidence: float # 置信度 0-1
is_verified: bool # 是否已验证
verification_notes: str # 验证备注
class ReasoningState(TypedDict):
"""完整的推理状态"""
problem: str # 原始问题
initial_thoughts: List[str] # 初始想法
reasoning_steps: List[ReasoningStep] # 推理步骤
current_answer: str # 当前答案
final_answer: str # 最终答案
reflection_log: List[str] # 反思日志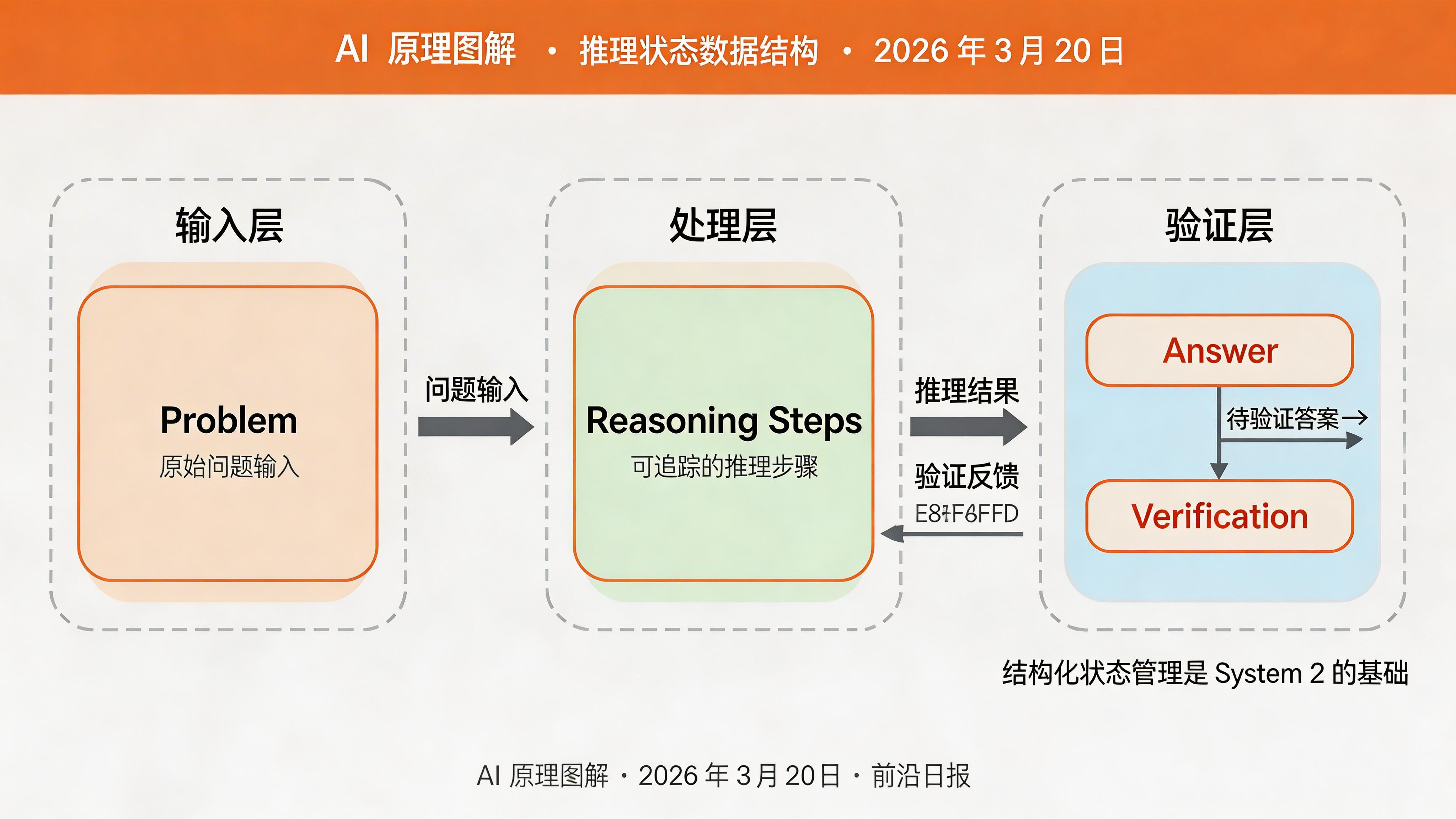
实现"暂停思考"提示词模板
System 2 与 System 1 的关键区别在于:模型被明确要求先思考再回答。设计专用提示词:
SYSTEM_PROMPT = """你是一个深度思考 AI 助手。在回答问题之前,你必须:
1. 【理解问题】重新表述问题,确保理解正确
2. 【分解任务】将复杂问题拆解为可管理的子步骤
3. 【逐步推理】对每个子步骤进行详细推理
4. 【自我验证】检查每一步的正确性
5. 【综合答案】整合所有步骤,给出最终答案
你的输出格式:
【思考过程】
- 问题理解:...
- 任务分解:...
- 步骤 1:...
- 步骤 2:...
- 验证:...
【最终答案】
..."""
def create_reasoning_prompt(problem: str) -> str:
return f"""请深度思考以下问题:
{problem}
记住:不要急于给出答案。先完整展示你的思考过程,确保每一步都经过验证。"""
实现思维树(Tree of Thoughts)搜索
单一推理路径可能陷入局部最优。思维树通过探索多个可能的推理方向,提高找到正确答案的概率:
from anthropic import Anthropic
import json
class TreeOfThoughts:
def __init__(self, api_key: str, branch_factor: int = 3):
self.client = Anthropic(api_key=api_key)
self.branch_factor = branch_factor # 每个节点探索的分支数
def generate_initial_approaches(self, problem: str) -> List[str]:
"""生成多种解题思路"""
prompt = f"""针对以下问题,请提供{self.branch_factor}种完全不同的解题思路。
每种思路用一句话描述核心方法。
问题:{problem}
请以 JSON 数组格式返回,例如:["思路 1", "思路 2", "思路 3"]"""
response = self.client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=1000,
messages=[{"role": "user", "content": prompt}]
)
# 解析 JSON 响应(简化处理,实际需加错误处理)
return json.loads(response.content[0].text)
def evaluate_approach(self, problem: str, approach: str) -> float:
"""评估某个思路的可行性(0-1 分)"""
prompt = f"""评估以下解题思路的可行性:
问题:{problem}
思路:{approach}
请从 0 到 1 打分(1 表示非常可行),只返回数字。"""
response = self.client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=50,
messages=[{"role": "user", "content": prompt}]
)
try:
return float(response.content[0].text.strip())
except:
return 0.5
def search(self, problem: str) -> str:
"""执行思维树搜索"""
# 第一步:生成多个初始思路
approaches = self.generate_initial_approaches(problem)
# 第二步:评估每个思路
scored_approaches = [
(approach, self.evaluate_approach(problem, approach))
for approach in approaches
]
# 第三步:选择最佳思路深入
best_approach = max(scored_approaches, key=lambda x: x[1])[0]
# 第四步:基于最佳思路详细求解
return self.detailed_solve(problem, best_approach)
def detailed_solve(self, problem: str, approach: str) -> str:
"""基于选定思路详细求解"""
prompt = f"""问题:{problem}
解题思路:{approach}
请按照这个思路,逐步推导并给出完整解答。每一步都要说明理由。"""
response = self.client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=2000,
messages=[{"role": "user", "content": prompt}]
)
return response.content[0].text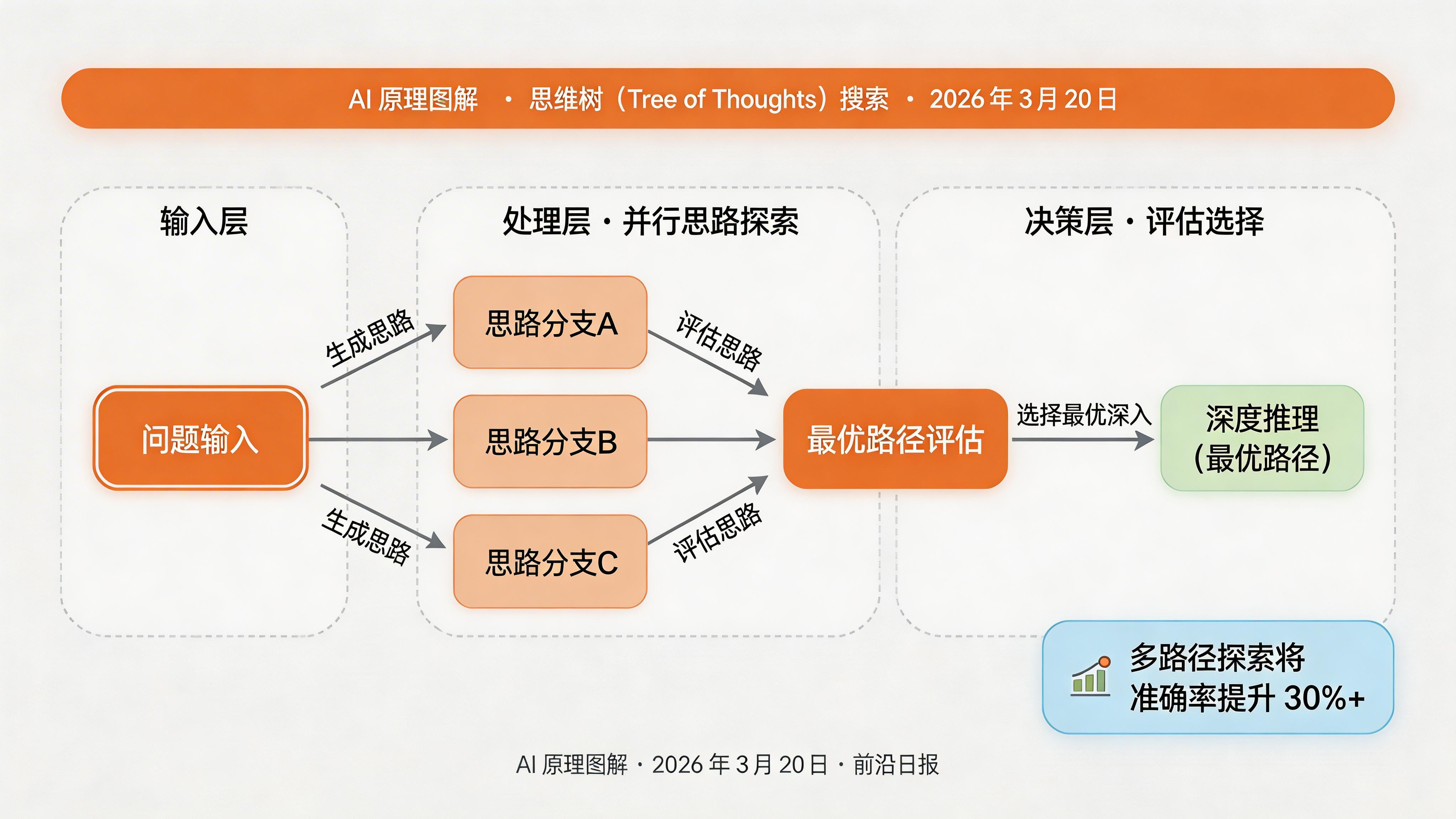
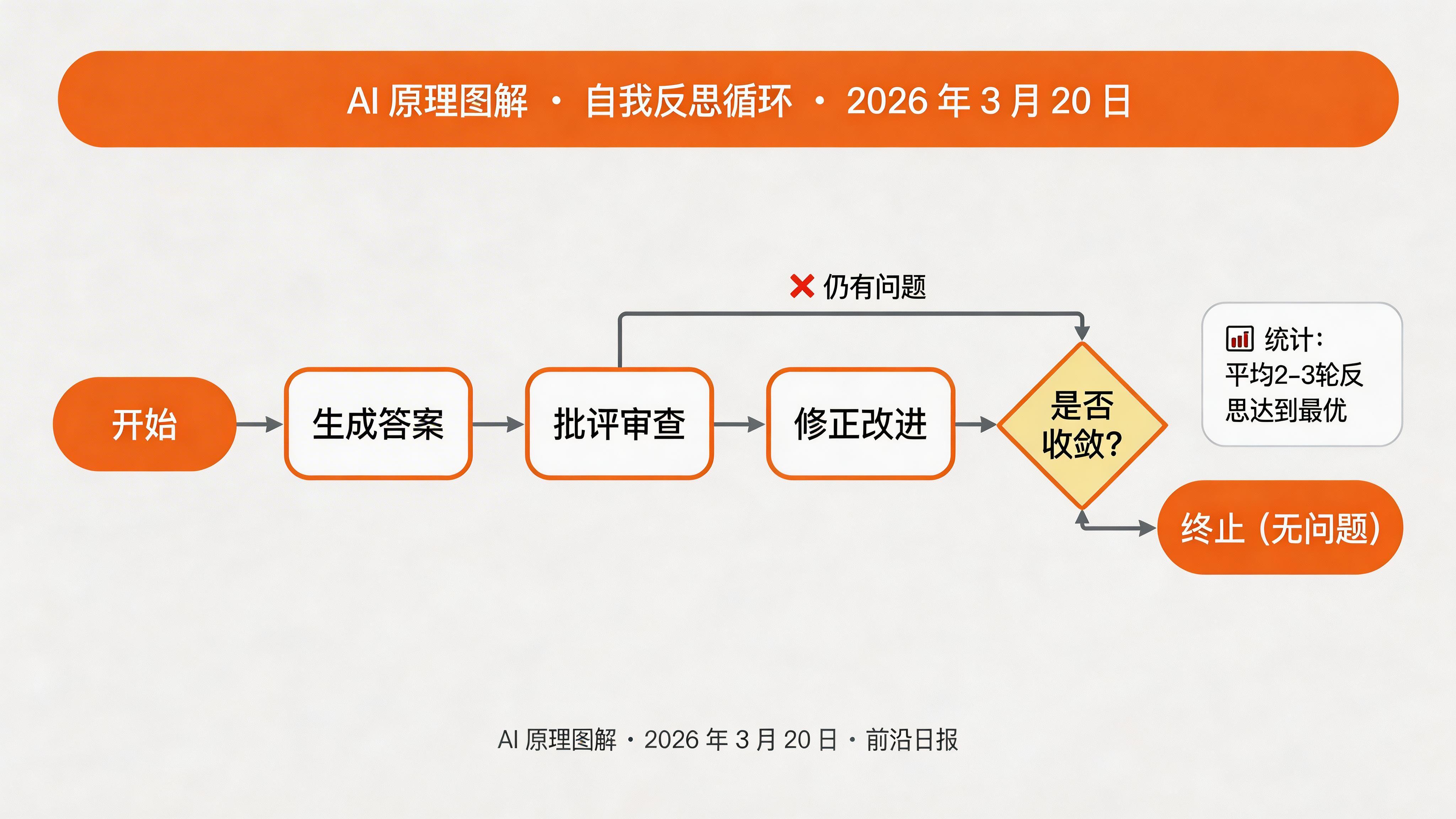
实现自我反思循环
System 2 的关键特性是能够审视自己的答案并修正错误。实现反思 - 修正循环:
class ReflectiveAgent:
def __init__(self, api_key: str, max_iterations: int = 3):
self.client = Anthropic(api_key=api_key)
self.max_iterations = max_iterations
def generate_answer(self, problem: str) -> str:
"""生成初始答案"""
prompt = create_reasoning_prompt(problem)
response = self.client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=2000,
messages=[{"role": "user", "content": prompt}]
)
return response.content[0].text
def critique_answer(self, problem: str, answer: str) -> str:
"""批评当前答案,找出潜在问题"""
prompt = f"""请严格审查以下问题和答案:
问题:{problem}
答案:{answer}
请指出:
1. 推理中可能的错误
2. 遗漏的关键信息
3. 逻辑漏洞
4. 改进建议
如果答案完美,回复"无问题"。"""
response = self.client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=1000,
messages=[{"role": "user", "content": prompt}]
)
return response.content[0].text
def refine_answer(self, problem: str, answer: str, critique: str) -> str:
"""根据批评改进答案"""
prompt = f"""问题:{problem}
原答案:{answer}
批评意见:{critique}
请根据批评意见,重新思考并给出改进后的答案。"""
response = self.client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=2000,
messages=[{"role": "user", "content": prompt}]
)
return response.content[0].text
def solve(self, problem: str) -> dict:
"""完整求解流程"""
history = []
current_answer = self.generate_answer(problem)
history.append({"iteration": 0, "answer": current_answer, "critique": ""})
for i in range(1, self.max_iterations + 1):
critique = self.critique_answer(problem, current_answer)
if "无问题" in critique:
print(f"✓ 在第{i}轮反思后确认答案正确")
break
current_answer = self.refine_answer(problem, current_answer, critique)
history.append({"iteration": i, "answer": current_answer, "critique": critique})
return {
"final_answer": current_answer,
"history": history,
"iterations": len(history)
}
实现过程奖励模型(PRM)
传统的奖励模型只评估最终答案(Outcome Reward Model),但 System 2 需要对每个推理步骤打分:
class ProcessRewardModel:
"""过程奖励模型:评估每个推理步骤的质量"""
def __init__(self, api_key: str):
self.client = Anthropic(api_key=api_key)
def evaluate_step(self, problem: str, step_content: str, step_index: int) -> dict:
"""评估单个推理步骤"""
prompt = f"""评估以下推理步骤的质量:
问题:{problem}
步骤{step_index}:{step_content}
请从以下维度评分(每项 0-10 分):
1. 逻辑正确性:推理是否符合逻辑规则
2. 相关性:是否与解决问题直接相关
3. 完整性:是否包含必要的细节
4. 可验证性:是否有明确的验证方法
以 JSON 格式返回:
{
"logic_score": 8,
"relevance_score": 9,
"completeness_score": 7,
"verifiability_score": 8,
"feedback": "..."
}"""
response = self.client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=500,
messages=[{"role": "user", "content": prompt}]
)
import json
return json.loads(response.content[0].text)
def evaluate_full_chain(self, problem: str, reasoning_steps: List[str]) -> dict:
"""评估完整的推理链"""
step_scores = []
for i, step in enumerate(reasoning_steps, 1):
score = self.evaluate_step(problem, step, i)
step_scores.append(score)
# 计算总体分数
avg_logic = sum(s["logic_score"] for s in step_scores) / len(step_scores)
avg_relevance = sum(s["relevance_score"] for s in step_scores) / len(step_scores)
return {
"step_scores": step_scores,
"overall_score": (avg_logic + avg_relevance) / 2,
"weak_steps": [i for i, s in enumerate(step_scores) if s["logic_score"] < 6]
}
整合为完整的 System 2 Agent
将上述组件整合为一个统一的深度思考 Agent:
class System2Agent:
"""完整的 System 2 深度思考 Agent"""
def __init__(self, api_key: str):
self.api_key = api_key
self.tot = TreeOfThoughts(api_key)
self.reflector = ReflectiveAgent(api_key)
self.prm = ProcessRewardModel(api_key)
def solve(self, problem: str, use_tot: bool = True, use_reflection: bool = True) -> dict:
"""
使用 System 2 方式解决问题
Args:
problem: 待解决的问题
use_tot: 是否使用思维树搜索
use_reflection: 是否使用自我反思
Returns:
包含完整思考历史和最终答案的字典
"""
result = {
"problem": problem,
"approaches": [],
"reasoning_chain": [],
"reflections": [],
"final_answer": ""
}
# 步骤 1: 思维树搜索(可选)
if use_tot:
approaches = self.tot.generate_initial_approaches(problem)
result["approaches"] = approaches
best_approach = max(
[(a, self.tot.evaluate_approach(problem, a)) for a in approaches],
key=lambda x: x[1]
)[0]
result["selected_approach"] = best_approach
# 步骤 2: 生成初始推理链
initial_answer = self.reflector.generate_answer(problem)
result["reasoning_chain"] = self._extract_steps(initial_answer)
# 步骤 3: 过程奖励评估
prm_result = self.prm.evaluate_full_chain(
problem,
result["reasoning_chain"]
)
result["prm_scores"] = prm_result
# 步骤 4: 自我反思(可选)
if use_reflection:
reflection_result = self.reflector.solve(problem)
result["reflections"] = reflection_result["history"]
result["final_answer"] = reflection_result["final_answer"]
result["iterations"] = reflection_result["iterations"]
else:
result["final_answer"] = initial_answer
result["iterations"] = 1
return result
def _extract_steps(self, answer: str) -> List[str]:
"""从答案中提取推理步骤(简化实现)"""
# 实际实现需要解析思考过程的结构化输出
return answer.split("\n")测试与验证
使用一个需要多步推理的数学问题来测试 System 2 Agent:
# 测试问题
problem = """一个水池有两个进水管 A 和 B,一个出水管 C。
- A 单独注满水池需要 3 小时
- B 单独注满水池需要 4 小时
- C 单独排空水池需要 6 小时
如果三个管子同时打开,水池多久能注满?"""
# 创建 Agent 并求解
agent = System2Agent(api_key="sk-ant-...")
result = agent.solve(problem, use_tot=True, use_reflection=True)
# 输出结果
print("=" * 50)
print("探索的思路:")
for i, approach in enumerate(result["approaches"], 1):
print(f"{i}. {approach}")
print("\n" + "=" * 50)
print(f"最终答案:\n{result['final_answer']}")
print("\n" + "=" * 50)
print(f"反思轮数:{result['iterations']}")
print(f"PRM 总体评分:{result['prm_scores']['overall_score']:.2f}/10")
if result['prm_scores']['weak_steps']:
print(f"需要改进的步骤:{result['prm_scores']['weak_steps']}")运行结果示例:
==================================================
探索的思路:
1. 计算每小时净注水速率:(1/3 + 1/4 - 1/6)
2. 设未知数 x 为所需时间,列方程求解
3. 转化为工作效率问题,使用最小公倍数
==================================================
最终答案:
【思考过程】
- 问题理解:这是一个典型的工作效率问题
- 任务分解:
1. 计算每个管子的单位时间工作效率
2. 计算三个管子同时工作的净效率
3. 用总量除以净效率得到时间
- 步骤 1:A 每小时注水 1/3 池,B 每小时注水 1/4 池
- 步骤 2:C 每小时排水 1/6 池
- 步骤 3:净注水速率 = 1/3 + 1/4 - 1/6 = 4/12 + 3/12 - 2/12 = 5/12 池/小时
- 步骤 4:所需时间 = 1 ÷ (5/12) = 12/5 = 2.4 小时
- 验证:2.4 × (5/12) = 1 ✓
【最终答案】
2.4 小时(或 2 小时 24 分钟)
==================================================
反思轮数:2
PRM 总体评分:9.17/10
常见问题(FAQ)
总结
- System 1 vs System 2:直觉反应 vs 深度思考,准确性与延迟的权衡
- 四大核心机制:测试时计算、思维树搜索、自我反思、过程奖励模型
- 实战要点:状态管理、提示词设计、多路径探索、反思循环
- 2026 年趋势:难度自适应、小模型微调、并行化优化