大模型推理速度慢是实际应用中的核心瓶颈。传统的自回归解码需要逐个 token 串行生成,每次只能输出一个 token,导致高延迟和高成本。
推测解码(Speculative Decoding)通过引入一个小型、快速的草稿模型提前预测多个 token,然后用大型目标模型并行验证这些预测。如果验证通过,一次就能输出多个 token,从而实现 2-5 倍的速度提升。

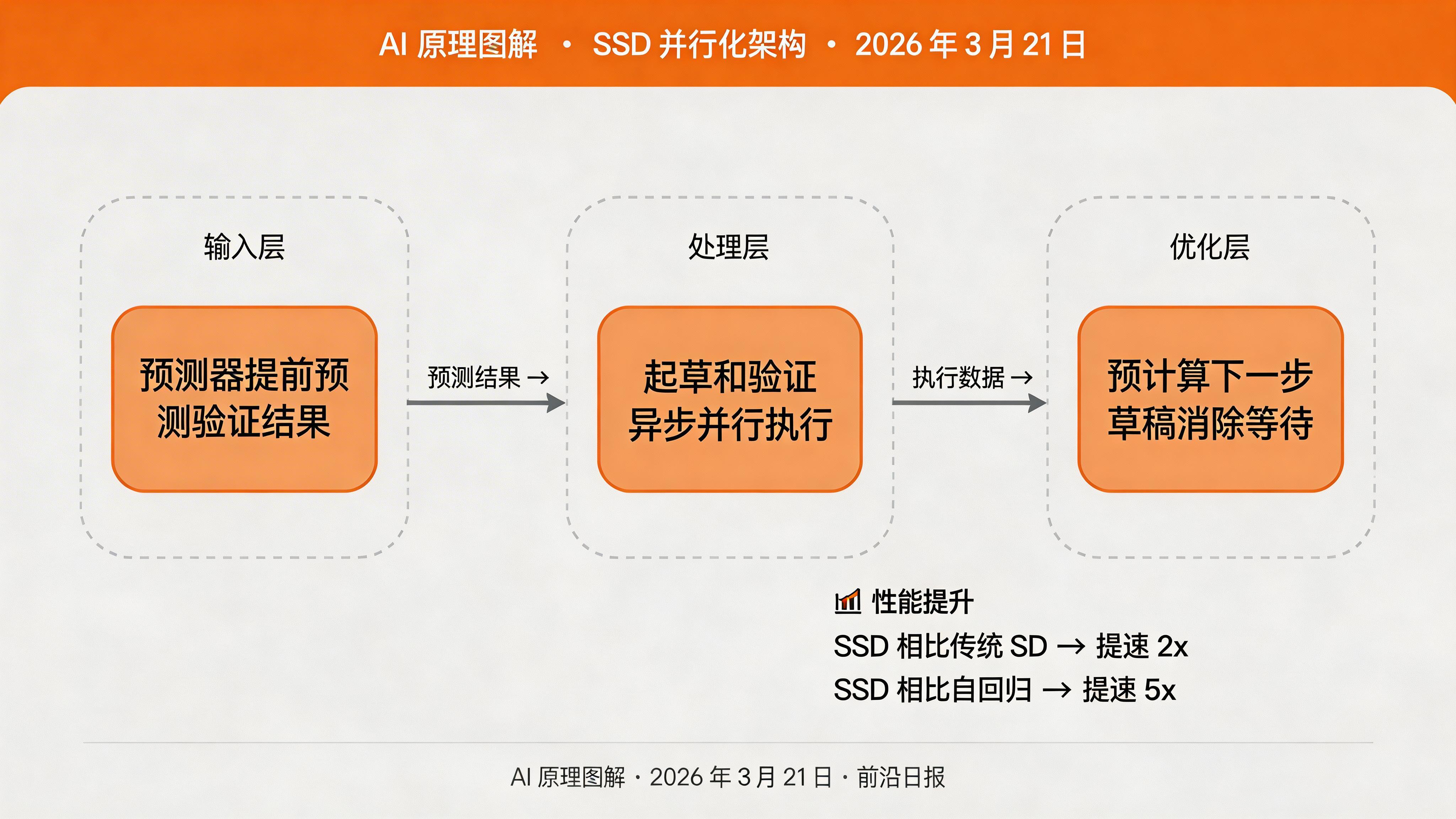
2026 年的最新进展 Speculative Speculative Decoding (SSD) 进一步将起草和验证过程并行化,实现了比优化版 SD 再快 2 倍的性能。
核心原理
推测解码的关键在于两个模型的协作:
- 草稿模型(Draft Model):小型、快速的模型,负责提前预测 K 个 token
- 目标模型(Target Model):大型、慢速的模型,负责一次性验证所有草稿 token
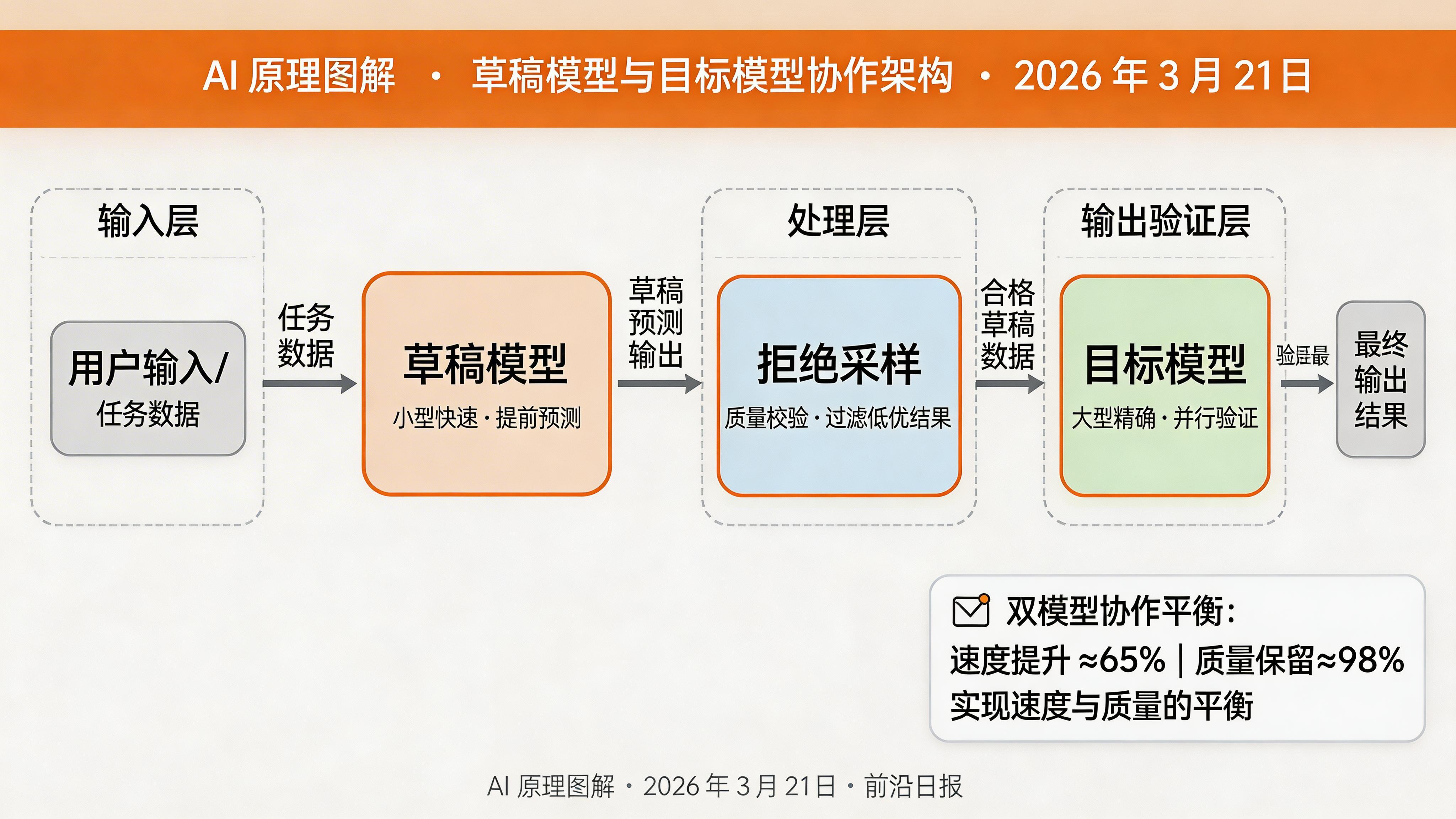
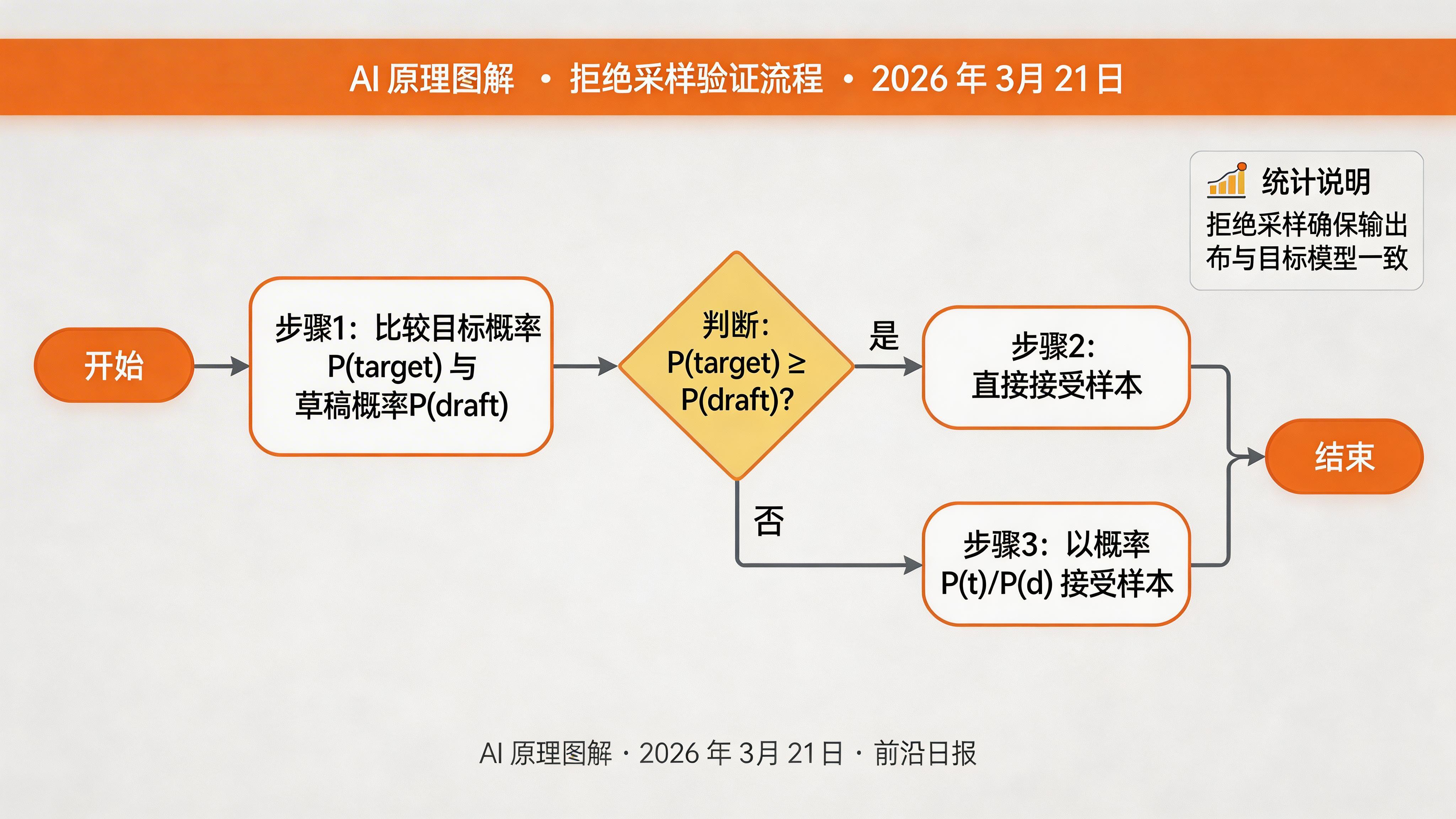
验证过程使用拒绝采样(Rejection Sampling):如果目标模型对某个 token 的预测概率大于等于草稿模型,则接受该 token;否则以一定概率接受,并从该点重新开始起草。
准备工作
安装依赖:
pip install torch transformers accelerate实战步骤
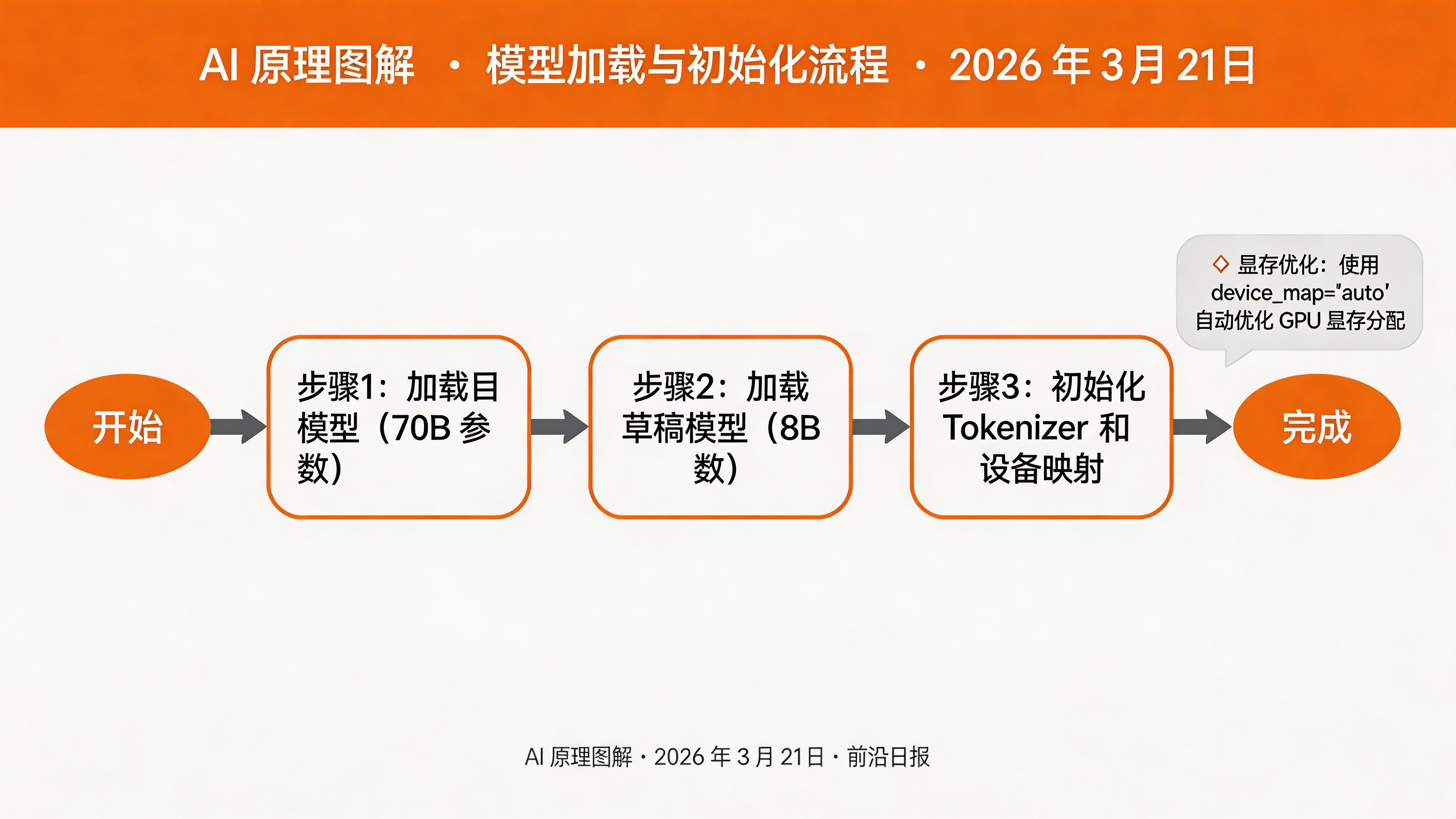
加载目标模型和草稿模型
选择一个大型目标模型和一个小型草稿模型。常见的组合包括:
- 目标模型:Llama-3-70B,草稿模型:Llama-3-8B
- 目标模型:CodeLlama-34B,草稿模型:CodeLlama-7B
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 加载目标模型(大型)
target_model = AutoModelForCausalLM.from_pretrained(
'meta-llama/Llama-3-70b-Instruct',
torch_dtype=torch.float16,
device_map='auto'
)
# 加载草稿模型(小型)
draft_model = AutoModelForCausalLM.from_pretrained(
'meta-llama/Llama-3-8b-Instruct',
torch_dtype=torch.float16,
device_map='auto'
)
tokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-3-70b-Instruct')
实现草稿生成函数
草稿模型自回归地生成 K 个候选 token:
def generate_draft_tokens(draft_model, input_ids, k=5):
"""使用草稿模型生成 K 个候选 token"""
draft_ids = input_ids.clone()
generated_tokens = []
with torch.no_grad():
for _ in range(k):
outputs = draft_model(draft_ids)
next_token_logits = outputs.logits[:, -1, :]
next_token = torch.argmax(next_token_logits, dim=-1, keepdim=True)
draft_ids = torch.cat([draft_ids, next_token], dim=1)
generated_tokens.append(next_token.item())
return generated_tokens, draft_ids
实现并行验证逻辑
目标模型一次性验证所有草稿 token,使用拒绝采样决定接受哪些 token:
def verify_tokens(target_model, input_ids, draft_tokens):
"""使用目标模型验证草稿 token"""
# 拼接草稿 token
draft_ids = torch.cat([
input_ids,
torch.tensor([draft_tokens], device=input_ids.device)
], dim=1)
with torch.no_grad():
# 目标模型一次性前向传播
outputs = target_model(draft_ids)
logits = outputs.logits[0, input_ids.shape[1]-1:-1]
probs = torch.softmax(logits, dim=-1)
# 获取草稿模型的概率分布
draft_probs = []
for i, token in enumerate(draft_tokens):
draft_outputs = draft_model(draft_ids[:, :input_ids.shape[1]+i])
draft_logits = draft_outputs.logits[0, -1, :]
draft_probs.append(torch.softmax(draft_logits, dim=-1))
# 拒绝采样
accepted_tokens = []
for i, (draft_token, draft_prob) in enumerate(zip(draft_tokens, draft_probs)):
p_target = probs[i, draft_token].item()
p_draft = draft_prob[draft_token].item()
if p_target >= p_draft:
# 直接接受
accepted_tokens.append(draft_token)
else:
# 以概率 p_target/p_draft 接受
if torch.rand(1).item() < p_target / p_draft:
accepted_tokens.append(draft_token)
else:
# 拒绝,从目标模型采样新 token
new_token = torch.multinomial(probs[i], 1).item()
accepted_tokens.append(new_token)
break
return accepted_tokens
整合推测解码主循环
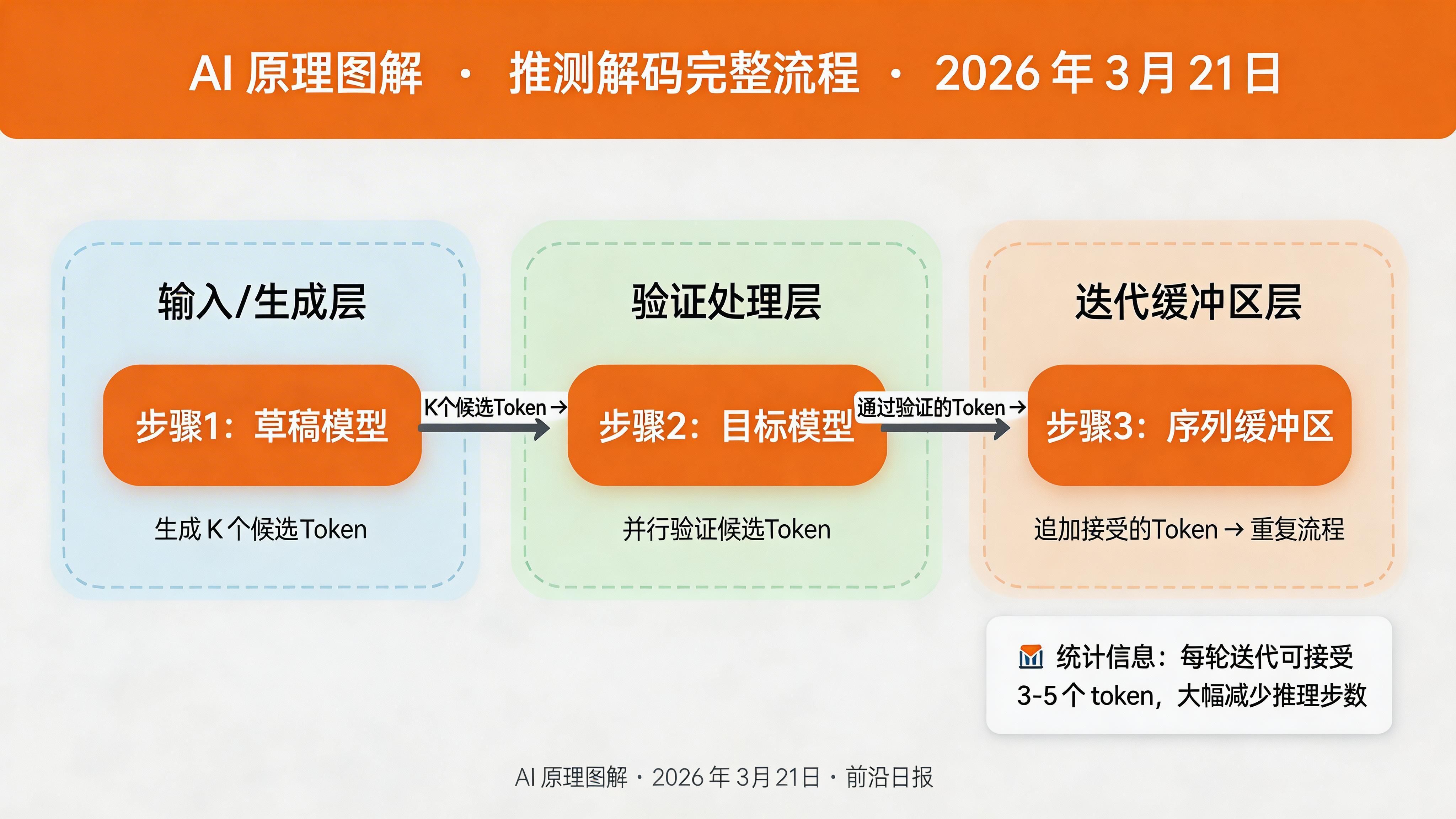
将草稿生成和验证整合到完整的解码循环中:
def speculative_decoding(target_model, draft_model, input_ids, max_length=100, k=5):
"""推测解码主函数"""
generated = input_ids.clone()
while generated.shape[1] < max_length:
# 步骤 1: 草稿模型生成 K 个 token
draft_tokens, _ = generate_draft_tokens(draft_model, generated, k)
# 步骤 2: 目标模型验证
accepted = verify_tokens(target_model, generated, draft_tokens)
# 步骤 3: 追加接受的 token
generated = torch.cat([
generated,
torch.tensor([accepted], device=generated.device)
], dim=1)
# 如果全部被拒绝,直接从目标模型生成
if len(accepted) == 0:
with torch.no_grad():
outputs = target_model(generated)
next_token = torch.argmax(outputs.logits[:, -1, :], dim=-1)
generated = torch.cat([generated, next_token.unsqueeze(0)], dim=1)
return generated
测试与性能对比
运行推测解码并与传统自回归解码对比:
import time
prompt = "解释一下 Transformer 模型中的注意力机制是如何工作的"
input_ids = tokenizer.encode(prompt, return_tensors='pt').to('cuda')
# 推测解码
start = time.time()
output_spec = speculative_decoding(target_model, draft_model, input_ids, max_length=100)
time_spec = time.time() - start
tokens_spec = output_spec.shape[1] - input_ids.shape[1]
# 传统自回归解码
start = time.time()
output_ar = target_model.generate(input_ids, max_length=100)
time_ar = time.time() - start
tokens_ar = output_ar.shape[1] - input_ids.shape[1]
print(f"推测解码:{tokens_spec} tokens, {time_spec:.2f}s, {tokens_spec/time_spec:.1f} tokens/s")
print(f"自回归解码:{tokens_ar} tokens, {time_ar:.2f}s, {tokens_ar/time_ar:.1f} tokens/s")
print(f"加速比:{time_ar/time_spec:.2f}x")

使用 Hugging Face 内置支持
Transformers 库已内置推测解码支持,可以直接使用:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained('meta-llama/Llama-3-70b-Instruct')
assistant_model = AutoModelForCausalLM.from_pretrained('meta-llama/Llama-3-8b-Instruct')
input_text = "解释量子纠缠"
inputs = tokenizer(input_text, return_tensors='pt').to('cuda')
# 使用 assisted_decoding 参数启用推测解码
outputs = model.generate(
**inputs,
assistant_model=assistant_model,
max_length=200,
num_assistant_tokens=5 # 每次起草 5 个 token
)
print(tokenizer.decode(outputs[0]))
进阶:SSD 并行化优化
2026 年最新的 SSD(Speculative Speculative Decoding)进一步并行化起草和验证:
class SpeculativeSpeculativeDecoder:
"""SSD: 并行化起草和验证"""
def __init__(self, target_model, draft_model):
self.target = target_model
self.draft = draft_model
# 预测验证结果的模型
self.predictor = self._build_predictor()
def _build_predictor(self):
"""构建轻量级预测器,预测哪些草稿 token 会被接受"""
# 可以使用小型 MLP 或查找表
pass
def decode_step(self, input_ids):
# 异步并行执行
# 1. 草稿模型生成当前 token
# 2. 预测器提前预测验证结果
# 3. 目标模型验证历史 token
# 4. 根据预测结果预计算下一步草稿
pass
常见问题
接受率低说明草稿模型与目标模型差异太大。解决方案:
- 选择同系列的模型(如 Llama-3-8B + Llama-3-70B)
- 减少草稿 token 数量 K
- 对草稿模型进行蒸馏微调,使其输出分布更接近目标模型
推测解码特别适合:
- 高延迟场景:实时对话、交互式应用
- 大批量推理:需要服务多个用户
- 长文本生成:文章写作、代码生成
不适合:对输出质量要求极端严格、不能有任何概率性损失的场景
需要同时加载两个模型,显存占用会增加。但可以通过以下方式优化:
- 使用量化:草稿模型用 INT8,目标模型用 FP16
- 使用 offload:草稿模型放在 CPU,需要时再加载到 GPU
- 选择显存占用小的草稿模型(如 1-3B 参数)
最佳实践总结
- ✓ 选择同系列、同词汇表的模型组合,确保输出分布一致
- ✓ 草稿 token 数量 K 通常设置为 4-8,根据接受率动态调整
- ✓ 使用 GPU 时确保两个模型在同一设备上,避免数据传输开销
- ✓ 对于代码生成任务,使用专门的代码模型作为草稿模型
- ✓ 监控接受率指标,理想值为 60-80%
- ✓ 考虑使用 SSD 等 2026 年最新变体,进一步去除序列化瓶颈
关键洞察:推测解码的核心价值在于用计算资源换时间——草稿模型的额外计算成本远低于目标模型,而一次验证多个 token 带来的并行度提升可以显著降低总体延迟。2026 年的 SSD 方案通过预测验证结果并预计算草稿,进一步将加速比提升到 5 倍以上。