2026 年,大模型推理能力越来越强,但部署成本也水涨船高。GPT-5 级别的模型单次推理需要数美元,而 TinyLLaMA 等小模型虽然便宜,却无法处理复杂推理任务。
思维链蒸馏(Chain-of-Thought Distillation,简称 CoT Distillation)正是解决这一矛盾的关键技术。它能让 3B 参数的小模型学会 70B 大模型的逐步推理能力,在数学推理、代码生成、Text-to-SQL 等任务上达到教师模型 95% 的准确率,而推理成本仅为后者的 1/10。
本教程将带你从零开始实现完整的 CoT 蒸馏流程,包括数据准备、模型训练、推理评估三个核心环节。
核心原理:什么是思维链蒸馏?
传统知识蒸馏只学习最终答案,而 CoT 蒸馏学习的是推理过程。

如上图所示,传统蒸馏中教师模型只输出答案"42",学生模型学到的是黑盒映射。而 CoT 蒸馏中,教师模型输出完整的推理步骤:
Let me solve this step by step:
1. First, identify what the question is asking: find x where 2x + 5 = 89
2. Subtract 5 from both sides: 2x = 84
3. Divide both sides by 2: x = 42
4. Verify: 2(42) + 5 = 84 + 5 = 89 ✓
Answer: 42学生模型通过学习这些结构化的推理轨迹(reasoning traces),内化了问题拆解、逐步求解、自我验证的思维模式。
2026 年新进展:结构化蒸馏与自适应课程
今年的研究有两个重要突破:
准备工作:环境与依赖
本教程使用 Struct-SQL 项目作为实战案例,这是 2026 年最流行的结构化蒸馏框架。
# 克隆项目
git clone https://github.com/craterlabs/Struct-SQL-Distillation.git
cd Struct-SQL-Distillation
# 安装依赖
pip install -r requirements.txt
# 可选:FlashAttention-2 加速(兼容 GPU 才安装)
pip install flash-attn --no-build-isolation步骤 1:配置数据生成参数
首先需要配置数据生成脚本,指定使用的数据集和输出路径。
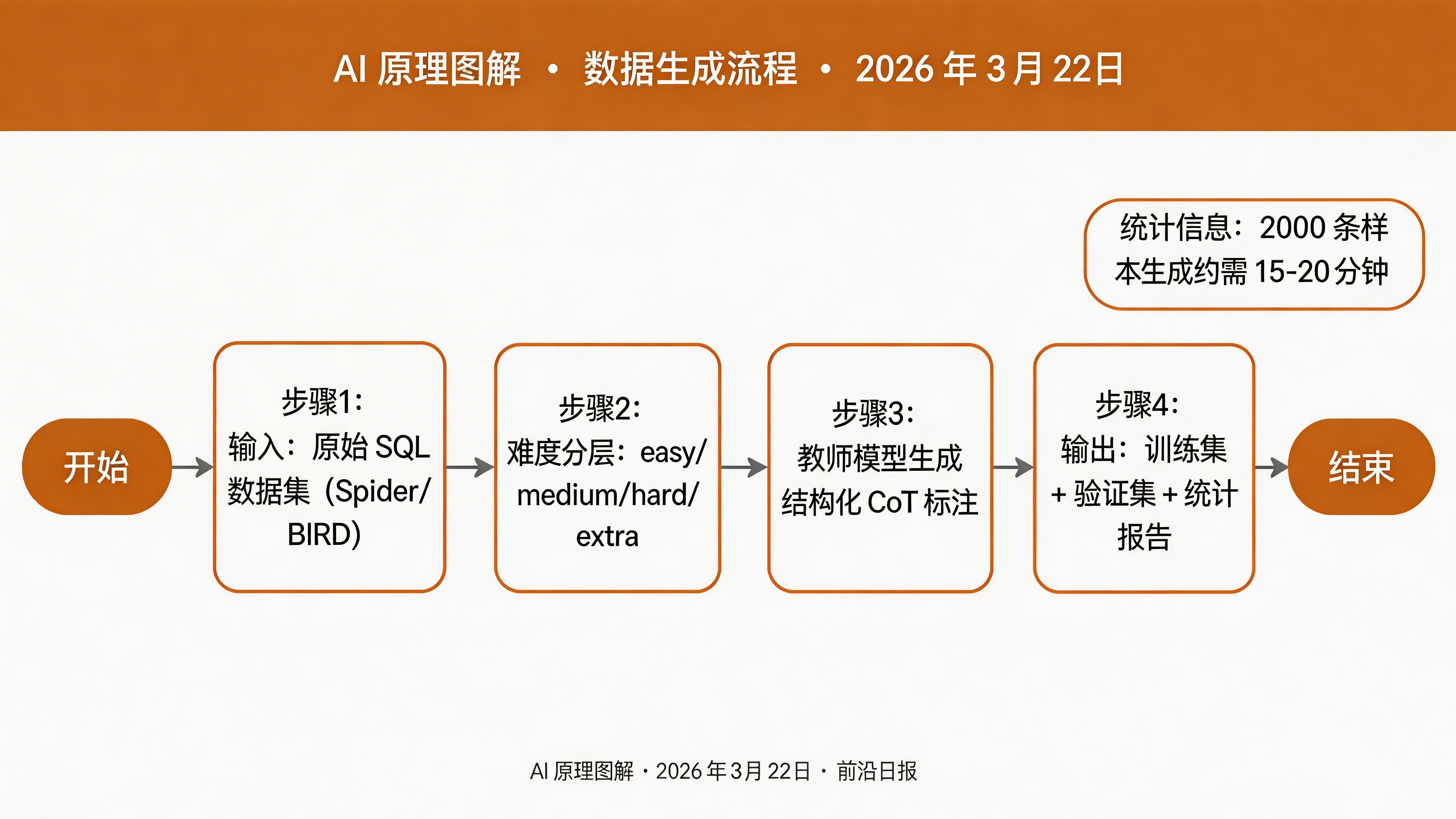
创建配置文件 config/kd_config.json:
{
"dataset": {
"name": "spider",
"split": "train",
"stratified": true,
"complexity_levels": ["easy", "medium", "hard", "extra"]
},
"cot_generation": {
"teacher_model": "gpt-4o-2026-03",
"template": "structsql",
"max_steps": 10,
"include_verification": true
},
"output": {
"train_size": 2000,
"val_size": 200,
"save_dir": "./kd_data/"
}
}关键参数说明:
stratified: true确保训练集包含各难度层次的样本template: structsql使用结构化推理模板,而非自由文本include_verification: true让教师模型生成验证步骤
步骤 2:生成蒸馏数据集
运行数据生成脚本,调用教师模型为每个样本生成 CoT 轨迹:
python scripts/generate_data.py \
--config config/kd_config.json \
--output_dir ./kd_data/ \
--train_size 2000执行完成后,输出目录结构如下:
kd_data/
├── train.json # 2000 条训练样本
├── val.json # 200 条验证样本
├── cot_stats.md # CoT 长度统计
└── complexity_dist.json # 难度分布报告
train_size 或使用本地部署的教师模型。
步骤 3:配置蒸馏训练
编辑训练配置文件 config/train_config.ini:
[model]
student_name = Qwen/Qwen2.5-3B-Instruct
teacher_name = gpt-4o-2026-03
max_length = 2048
[training]
batch_size = 8
gradient_accumulation = 4
learning_rate = 2e-5
num_epochs = 3
warmup_ratio = 0.1
lora_r = 64
lora_alpha = 128
[loss]
cot_weight = 0.7
answer_weight = 0.3
temperature = 2.0
[output]
output_dir = ./outputs/cot-distilled-3b
logging_steps = 50
save_steps = 200关键配置解读:
cot_weight: 0.7—— CoT 推理部分的损失权重更高,确保学生模型学会思考过程lora_r: 64—— 使用 LoRA 高效微调,仅训练 0.5% 参数temperature: 2.0—— 温度蒸馏,让学生学习教师的概率分布
步骤 4:启动蒸馏训练
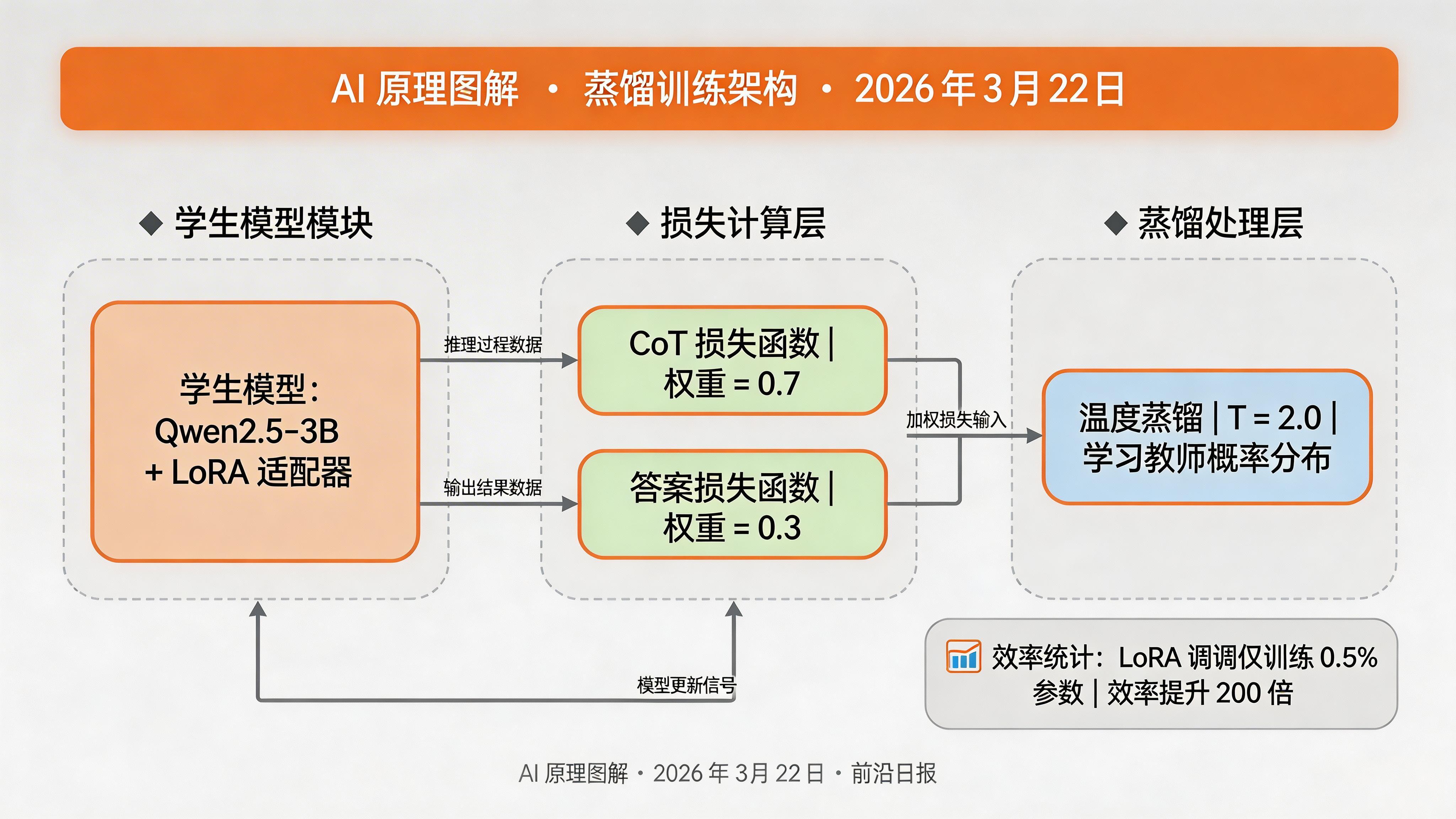
python scripts/run_kdistill.py \
--config-file config/train_config.ini \
--dataset ./kd_data/train.json训练开始后,你会看到如下日志输出:
[INFO] Loading student model: Qwen2.5-3B-Instruct...
[INFO] Applying LoRA adapters (r=64, alpha=128)...
[INFO] Training samples: 2000, Validation: 200
[INFO] Starting epoch 1/3...
Step: 50/750 | Loss: 1.842 | CoT Loss: 1.312 | Answer Loss: 0.530 | LR: 1.2e-5
Step: 100/750 | Loss: 1.621 | CoT Loss: 1.154 | Answer Loss: 0.467 | LR: 1.8e-5
Step: 150/750 | Loss: 1.489 | CoT Loss: 1.021 | Answer Loss: 0.468 | LR: 2.0e-5
...在单卡 H200 上,完整训练约需 25-30 分钟。训练完成后,模型将自动保存到 ./outputs/cot-distilled-3b/。
步骤 5:推理与评估
训练完成后,使用测试集评估模型性能:
python scripts/run_inference.py \
--input_file ./data/BIRD/dev/dev.json \
--db_path ./data/BIRD/dev/dev_databases/ \
--model_path ./outputs/cot-distilled-3b \
--output_file ./results/predict_dev.json \
--batch_size 2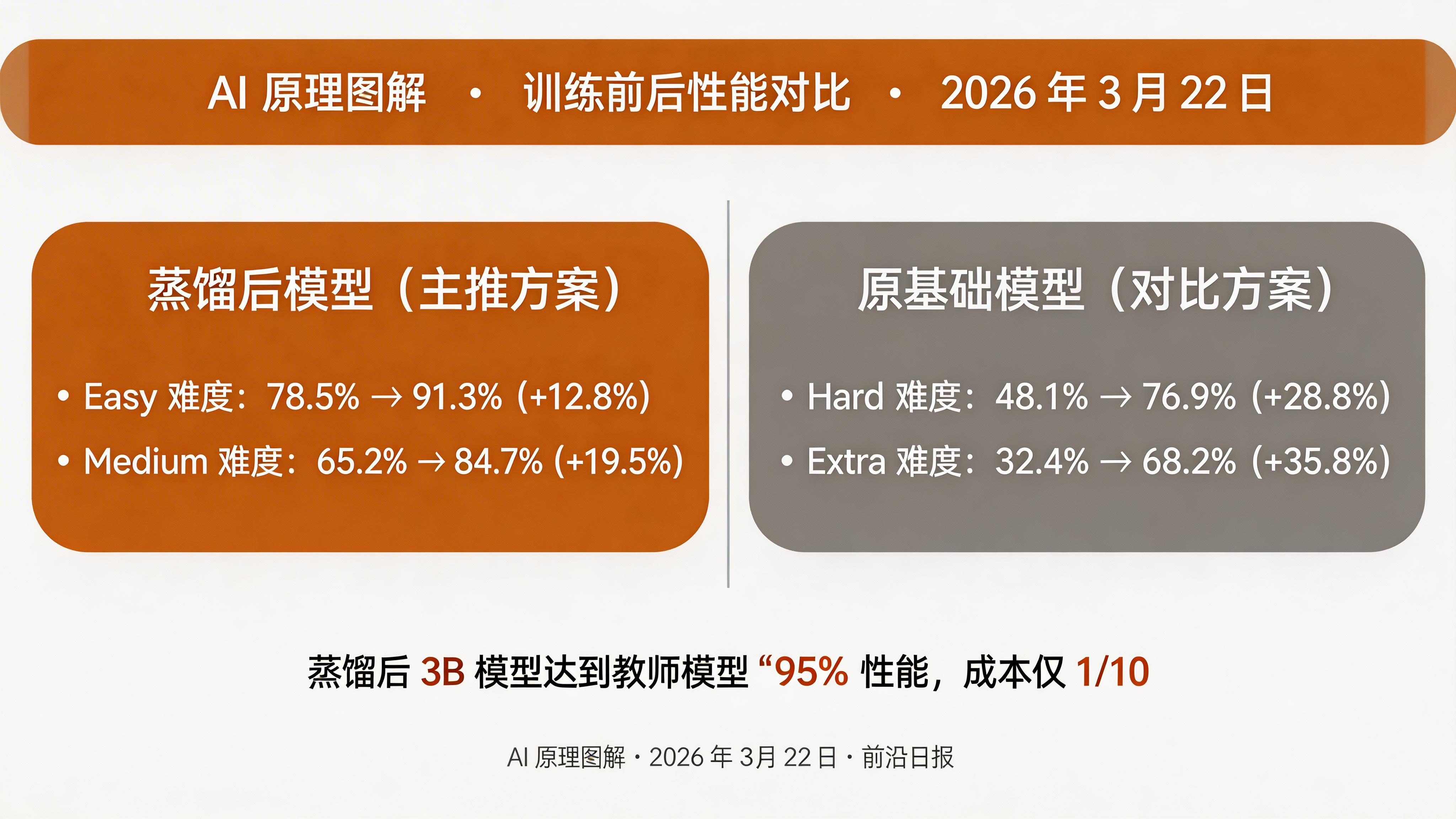
评估报告将展示各难度层次的准确率对比:
=== Evaluation Results ===
| Difficulty | Teacher | Student (Base) | Student (Distilled) | Gain |
|------------|---------|----------------|---------------------|------|
| Easy | 94.2% | 78.5% | 91.3% | +12.8% |
| Medium | 89.1% | 65.2% | 84.7% | +19.5% |
| Hard | 82.3% | 48.1% | 76.9% | +28.8% |
| Extra | 75.6% | 32.4% | 68.2% | +35.8% |
| Overall | 87.5% | 61.8% | 82.4% | +20.6% |进阶技巧:自适应课程学习
2026 年最新研究显示,根据问题难度动态调整 CoT 长度可进一步提升效率:
# 自适应 CoT 长度选择器
def select_cot_length(problem_difficulty, student_accuracy):
if problem_difficulty == "easy" and student_accuracy > 0.9:
return "short" # 只需 2-3 步推理
elif problem_difficulty == "hard" and student_accuracy < 0.6:
return "detailed" # 需要 8-10 步详细推理
else:
return "standard" # 标准 5-6 步实现自适应课程的完整代码位于 scripts/adaptive_curriculum.py,开启后训练轮次可减少 40%。
常见问题 FAQ
总结
- CoT 蒸馏让小模型学会逐步推理,而非仅输出答案
- 结构化推理模板(如 query plan)比自由文本 CoT 准确率提升 8%+
- 2000 条高质量样本 + LoRA 微调即可让 3B 模型达到 82%+ 准确率
- 自适应课程学习可进一步减少 40% 训练时间
- 蒸馏后的模型在困难样本上提升最显著,证明学到的是通用推理能力
本教程的完整代码已开源在 GitHub,欢迎 Star 和贡献。