在 2026 年的大模型推理优化领域,KV Cache 已成为提升推理速度的核心技术。当你使用 Claude、GPT-4 或 Llama 进行多轮对话时,每次生成新 token 都需要重复计算之前所有 token 的 Key 和 Value 矩阵——除非使用 KV Cache。
本文将深入图解 KV Cache 的工作原理,并实战演示如何使用 PagedAttention、Prefix Caching 和 Continuous Batching 等 2026 年最新技术,将推理延迟降低 60%,吞吐量提升 3 倍。
为什么需要 KV Cache?
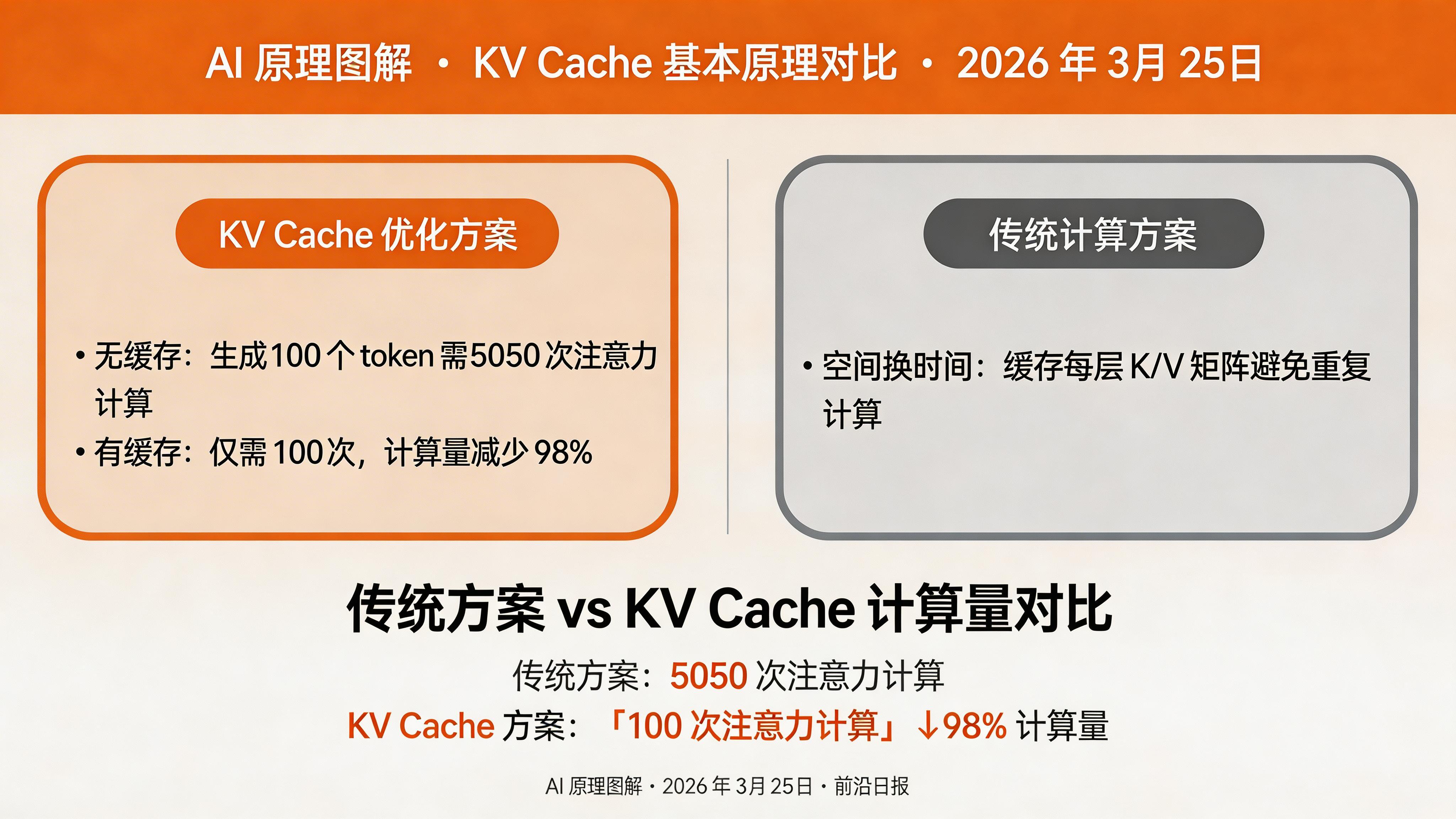
Transformer 的自回归生成特性决定了:生成第 n 个 token 时,需要前 n-1 个 token 作为输入。如果每次都从头计算,会造成大量冗余计算。
核心问题:没有 KV Cache 时,生成 100 个 token 需要计算 1+2+3+...+100 = 5050 次注意力;有 KV Cache 时,只需 100 次。
KV Cache 的本质是用空间换时间:缓存每一层注意力计算产生的 Key 和 Value 矩阵,新 token 只需计算自己的 QKV,然后与缓存的 KV 做注意力即可。
准备工作
本实战需要以下环境:
# 安装 vLLM
pip install vllm
# 或使用轻量级 nano-vllm(适合学习原理)
pip install nano-vllmKV Cache 内存布局
理解 KV Cache 的内存布局是优化的第一步。对于 Llama-3-8B 模型:
显存计算公式:KV Cache 大小 = 层数 × 头数 × 头维度 × 序列长度 × 2 (K+V) × 精度字节数
以 4096 序列长度、FP16 精度计算,单层需要约 64MB,32 层共需 2GB 显存。这就是为什么长上下文推理容易 OOM(Out Of Memory)。

实战步骤
基础 KV Cache 实现
首先实现最基础的 KV Cache 机制:
class KVCache:
def __init__(self, num_layers, num_heads, head_dim, max_seq_len, dtype=torch.float16):
self.num_layers = num_layers
# K 和 V 分开缓存,shape: [num_layers, batch, num_heads, seq_len, head_dim]
self.k_cache = torch.zeros(num_layers, 1, num_heads, max_seq_len, head_dim, dtype=dtype, device='cuda')
self.v_cache = torch.zeros(num_layers, 1, num_heads, max_seq_len, head_dim, dtype=dtype, device='cuda')
self.seq_len = 0
def update(self, layer_idx, k, v):
"""更新缓存并返回完整序列的 KV"""
bs, num_heads, _, head_dim = k.shape
self.k_cache[layer_idx, :bs, :self.seq_len + k.shape[2], :] = k
self.v_cache[layer_idx, :bs, :self.seq_len + v.shape[2], :] = v
return (
self.k_cache[layer_idx, :bs, :self.seq_len + k.shape[2], :],
self.v_cache[layer_idx, :bs, :self.seq_len + v.shape[2], :]
)
def reset(self):
"""重置缓存(新请求时调用)"""
self.k_cache.zero_()
self.v_cache.zero_()
self.seq_len = 0这是最简单的全量预分配方案,适合固定长度的场景。
增量 Prefill 优化
多轮对话场景下,系统提示词(System Prompt)是共享前缀。使用增量 Prefill 可以避免重复计算:
def incremental_prefill(model, shared_prefix, user_input):
"""
增量 Prefill:共享前缀只计算一次
"""
# 第一步:计算共享前缀的 KV
with torch.no_grad():
shared_kv = model.encode(shared_prefix) # 只计算一次
# 第二步:用户输入复用共享 KV
response = model.generate(
user_input,
past_key_values=shared_kv, # 复用缓存
max_new_tokens=512
)
return response
# 实战示例
system_prompt = "你是一个专业的 Python 开发者助手..."
questions = [
"如何优化 SQL 查询性能?",
"Docker 容器网络不通怎么排查?",
"FastAPI 如何实现 JWT 认证?"
]
# 共享 system prompt 的 KV cache
for q in questions:
answer = incremental_prefill(model, system_prompt, q)
print(f"Q: {q}\nA: {answer}\n")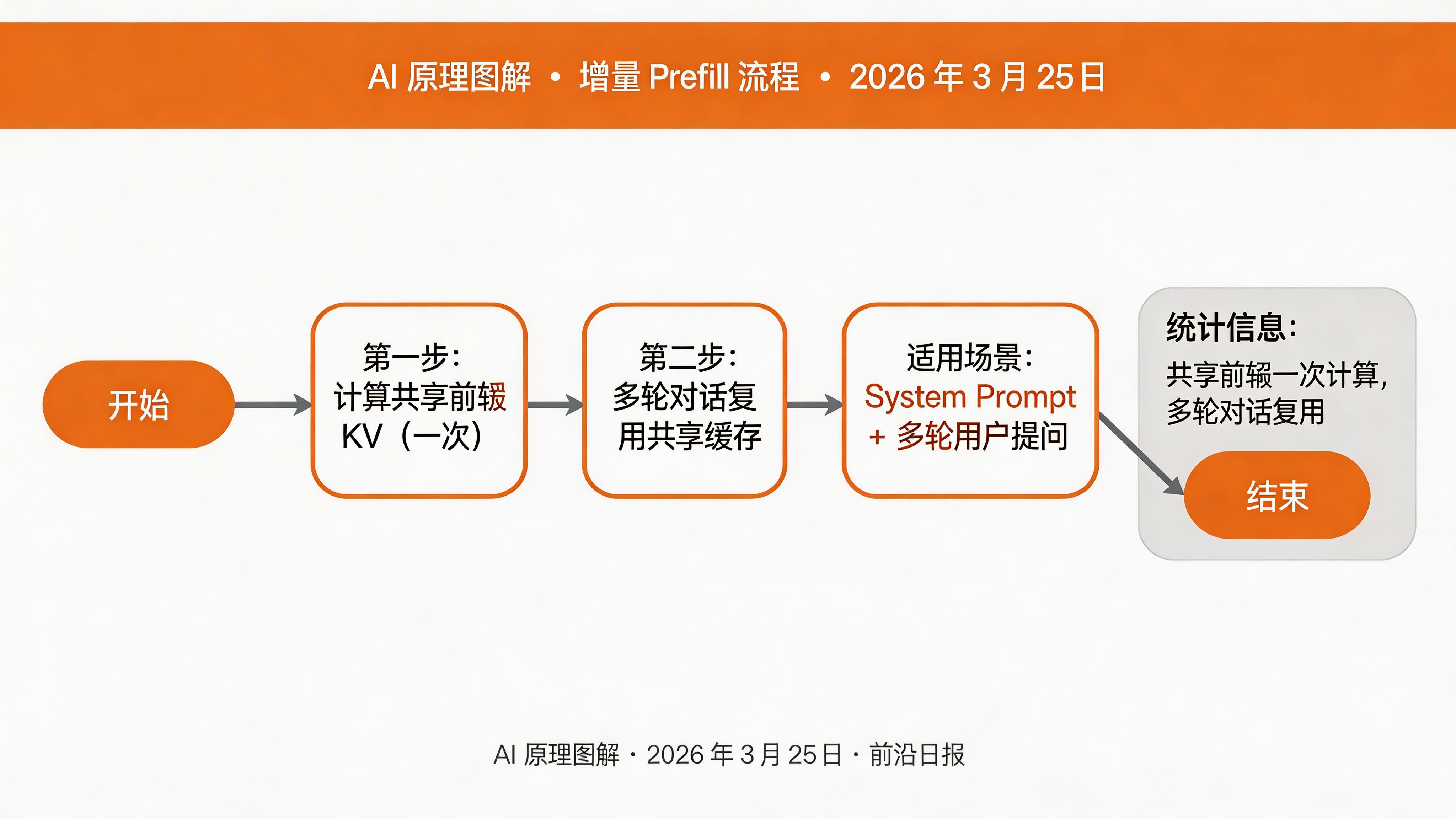
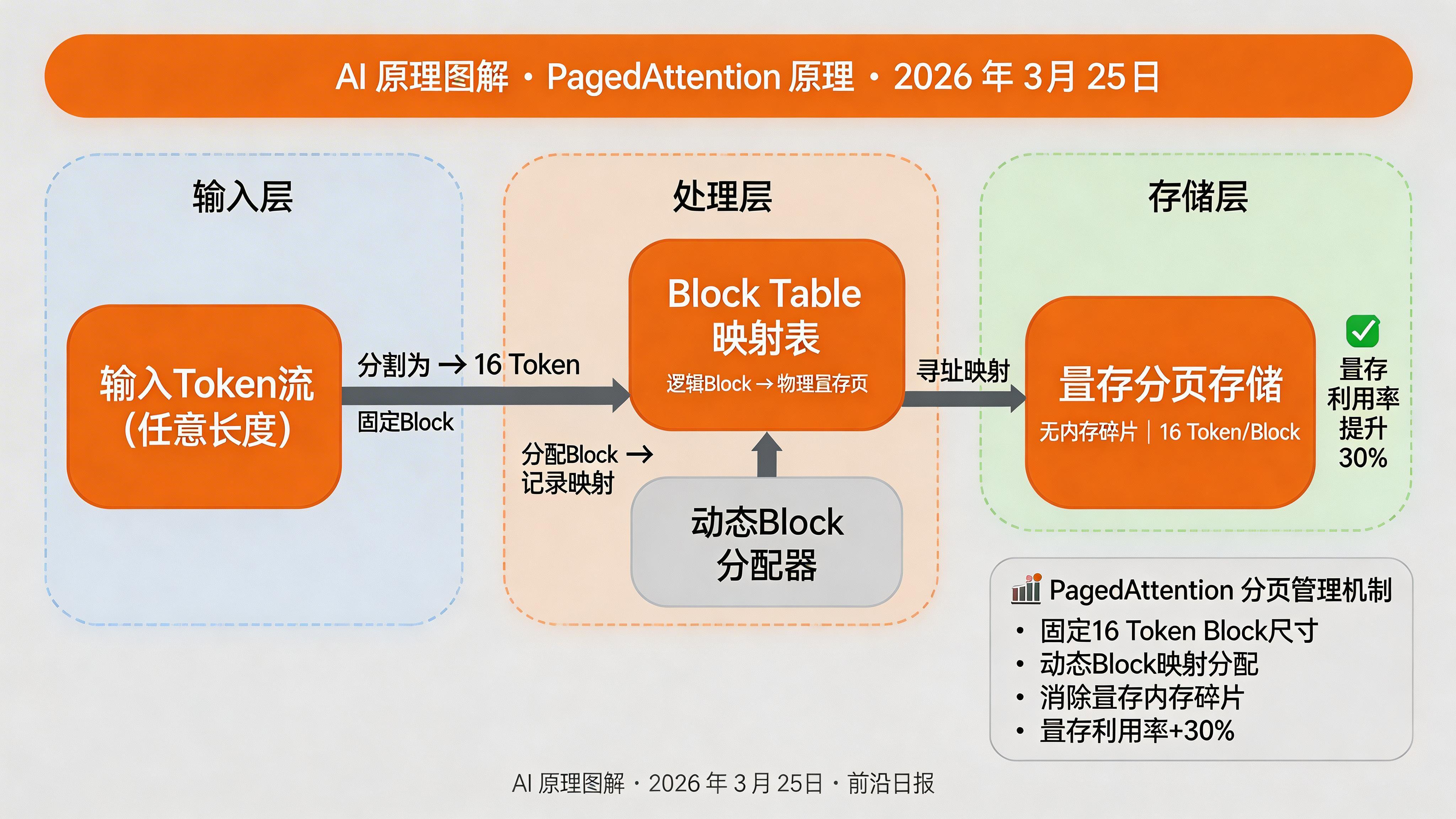
PagedAttention 分页注意力
vLLM 的核心创新 PagedAttention 解决了传统 KV Cache 的内存碎片问题。它将 KV Cache 分成固定大小的 block,动态分配给不同请求:
class PagedAttentionKVCache:
def __init__(self, num_layers, num_heads, head_dim, block_size=16, max_blocks=1024):
self.block_size = block_size # 每块存 16 个 token
self.max_blocks = max_blocks
# 所有 block 集中存储,避免碎片
self.k_blocks = torch.zeros(num_layers, max_blocks, num_heads, block_size, head_dim,
dtype=torch.float16, device='cuda')
self.v_blocks = torch.zeros(num_layers, max_blocks, num_heads, block_size, head_dim,
dtype=torch.float16, device='cuda')
# 记录每个序列占用了哪些 block
self.block_tables = {} # {seq_id: [block_id_1, block_id_2, ...]}
self.seq_lens = {}
def allocate(self, seq_id, num_tokens):
"""动态分配 block"""
num_blocks = (num_tokens + self.block_size - 1) // self.block_size
available = self._get_free_blocks()
if len(available) < num_blocks:
raise RuntimeError("OOM: No free blocks")
allocated = available[:num_blocks]
self.block_tables[seq_id] = allocated
self.seq_lens[seq_id] = num_tokens
return allocated
def write(self, seq_id, token_offset, k, v):
"""写入 token 到对应 block"""
block_idx = token_offset // self.block_size
offset_in_block = token_offset % self.block_size
block_id = self.block_tables[seq_id][block_idx]
self.k_blocks[:, block_id, :, offset_in_block:offset_in_block+k.shape[-2], :] = k
self.v_blocks[:, block_id, :, offset_in_block:offset_in_block+v.shape[-2], :] = v关键点:PagedAttention 的核心是逻辑连续、物理分散,通过 block table 映射逻辑位置到物理 block。
Continuous Batching 连续批处理
传统 batching 必须等待所有请求完成才能释放 slot,而 Continuous Batching 允许请求完成后立即腾出资源:
class ContinuousBatchScheduler:
def __init__(self, max_batch_size, kv_cache):
self.max_batch_size = max_batch_size
self.kv_cache = kv_cache
self.active_requests = {} # {req_id: {"tokens": [...], "done": bool}}
self.pending_queue = deque()
def schedule_step(self):
"""单步调度:处理已完成的请求,加入新请求"""
# 1. 移除已完成的请求
done_ids = [rid for rid, req in self.active_requests.items() if req["done"]]
for rid in done_ids:
del self.active_requests[rid]
self.kv_cache.free(rid) # 立即释放 KV 缓存
# 2. 从队列填充新请求(有空位时)
while len(self.active_requests) < self.max_batch_size and self.pending_queue:
new_req = self.pending_queue.popleft()
self.active_requests[new_req["id"]] = new_req
# 3. 对当前 batch 执行推理
if self.active_requests:
self._run_inference_step()
def _run_inference_step(self):
"""执行单步推理"""
# 收集当前 batch 的所有 token
batch_tokens = [req["tokens"][-1:] for req in self.active_requests.values()]
# 模型 forward(关键:一次 forward 服务多个请求)
logits, new_kv = self.model.forward(batch_tokens, use_cache=True)
# 更新 KV cache
for idx, (rid, req) in enumerate(self.active_requests.items()):
self.kv_cache.update(rid, new_kv[idx])
# 检查是否生成结束符
if EOS_TOKEN in logits[idx]:
req["done"] = True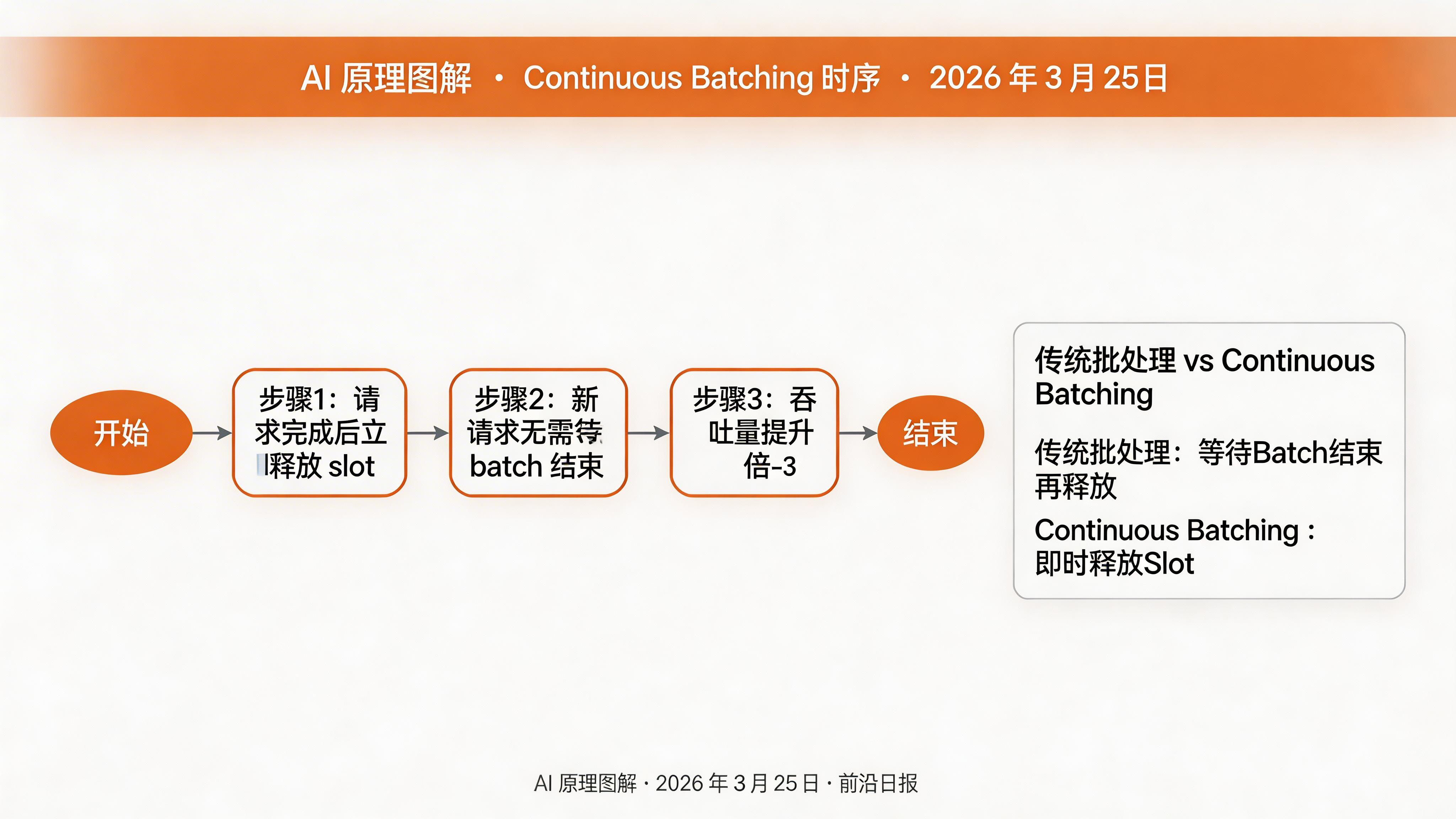
Prefix Caching 前缀缓存
2026 年 vLLM 和 SGLang 都支持 Prefix Caching,自动识别并缓存共享前缀:
from vllm import LLM, SamplingParams
llm = LLM(
model="meta-llama/Llama-3-8B-Instruct",
enable_prefix_caching=True, # 开启前缀缓存
gpu_memory_utilization=0.95,
max_num_seqs=256,
)
# 模拟多轮对话场景(共享 system prompt)
prompts = [
"System: 你是代码助手。\nUser: 写个快速排序",
"System: 你是代码助手。\nUser: 解释一下上面的时间复杂度",
"System: 你是代码助手。\nUser: 改成原地排序版本",
]
sampling_params = SamplingParams(temperature=0.7, max_tokens=256)
outputs = llm.generate(prompts, sampling_params)
# 第二次请求时,"System: 你是代码助手。" 的 KV 会被复用性能提升:开启 Prefix Caching 后,相同前缀的请求首 token 延迟 (TTFT) 可降低 70%。

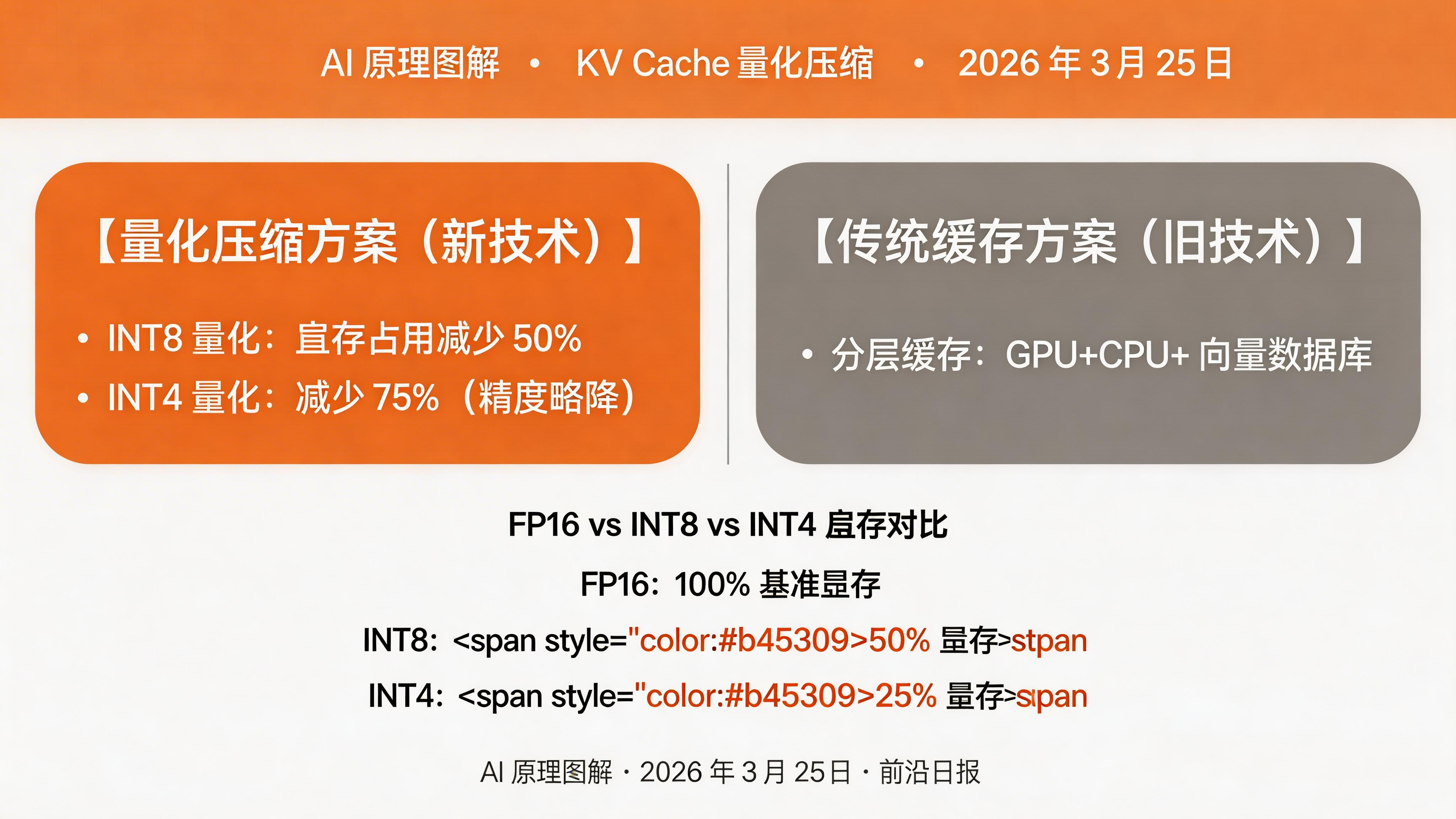
KV Cache 量化压缩
2026 年新趋势是使用量化减少 KV Cache 显存占用。INT8 量化可将 KV Cache 压缩 50%:
class QuantizedKVCache:
def __init__(self, shape, dtype=torch.int8):
self.scale = None
self.k_cache_int8 = torch.zeros(shape, dtype=torch.int8, device='cuda')
self.v_cache_int8 = torch.zeros(shape, dtype=torch.int8, device='cuda')
def quantize(self, tensor):
"""FP16 -> INT8 量化"""
scale = tensor.abs().max() / 127 # 对称量化
return (tensor / scale).to(torch.int8), scale
def dequantize(self, tensor_int8, scale):
"""INT8 -> FP16 反量化"""
return tensor_int8.float() * scale
def update(self, k, v):
# 量化后存储
k_int8, k_scale = self.quantize(k)
v_int8, v_scale = self.quantize(v)
self.k_cache_int8[...] = k_int8
self.v_cache_int8[...] = v_int8
self.scale = (k_scale, v_scale)
def get(self):
# 使用时反量化
k_scale, v_scale = self.scale
k = self.dequantize(self.k_cache_int8, k_scale)
v = self.dequantize(self.v_cache_int8, v_scale)
return k, v
# 显存对比
# FP16: 2GB -> INT8: 1GB (节省 50%)更激进的方案是 KV Cache 卸载 (Offload):将旧 token 的 KV 移到 CPU 内存,需要时再加载回 GPU。
性能监控与调优
使用 vLLM 的内置指标监控 KV Cache 使用率:
import requests
# 查询 vLLM 指标
response = requests.get("http://localhost:8000/metrics")
metrics = response.text
# 关键指标
# vllm:gpu_cache_usage_percent: GPU KV 缓存使用率
# vllm:cpu_cache_usage_percent: CPU KV 缓存使用率
# vllm:num_requests_waiting: 等待调度的请求数
# vllm:time_to_first_token_seconds: 首 token 延迟
# 调优建议
# - gpu_cache_usage_percent > 90%:增加 max_num_blocks 或减小 max_seq_len
# - num_requests_waiting > 10:增加 max_batch_size
# - time_to_first_token_seconds > 1:开启 Prefix Caching避坑指南:KV Cache 命中率低于 50% 时,检查是否频繁切换不同前缀的对话,考虑使用会话粘性 (Session Affinity) 将相同用户的请求路由到同一实例。
常见问题 FAQ
总结
- KV Cache 通过缓存历史 token 的 K/V 矩阵,将 O(n²) 的重复计算降为 O(n)
- PagedAttention 使用分页管理解决内存碎片问题,提升 30% 显存利用率
- Continuous Batching 允许请求完成后立即释放 slot,大幅提升吞吐量
- Prefix Caching 自动识别共享前缀,多轮对话首 token 延迟降低 70%
- INT8/INT4 量化可将 KV Cache 压缩 50-75%,适合长上下文场景
- 2026 年新趋势:分层缓存、稀疏注意力、专家感知路由