你的 Agent 通过了演示测试,却在生产环境烧掉了 153 美元预算?这不是假设 —— 这是 2026 年 AI Agent 开发者最常面临的困境。AI Agent 具有非确定性、多步骤执行和工具调用复杂性三大特征,传统测试方法完全失效。
本教程将手把手教你使用 LangSmith 构建完整的 AI Agent 评估系统,涵盖:
你将掌握:Trace 驱动的执行追溯、LLM-as-Judge 自动评估、自定义指标量化、生产环境实时监控告警、迭代优化闭环
核心概念:为什么 Agent 评估如此特殊
传统 LLM 应用评估只需关注输入输出质量,但 AI Agent 的评估需要追踪整个决策链路:

Trace 驱动
记录 Agent 每一步决策和执行路径
多维度评估
工具选择、规划质量、推理连贯性独立打分
实时监控
成本、延迟、错误率、质量指标告警
迭代闭环
离线评估 + 在线反馈驱动持续优化
关键洞察:仅评估最终输出就像批改数学卷子只看最后一题答案 —— 你会错过推理错误、公式用错、以及正确步骤导致的错误结论。
环境准备与依赖
Python 3.10+
推荐 3.11 或更高版本
LangChain
AI Agent 框架
LangSmith
评估与可观测性平台
OpenAI API
或其他支持的 LLM 提供商
安装依赖:
pip install langchain langsmith langchain-openai配置 LangSmith 环境变量:
export LANGSMITH_API_KEY="your_api_key"
export LANGSMITH_TRACING=true
export LANGSMITH_PROJECT="agent-evaluation-demo"实战步骤
01
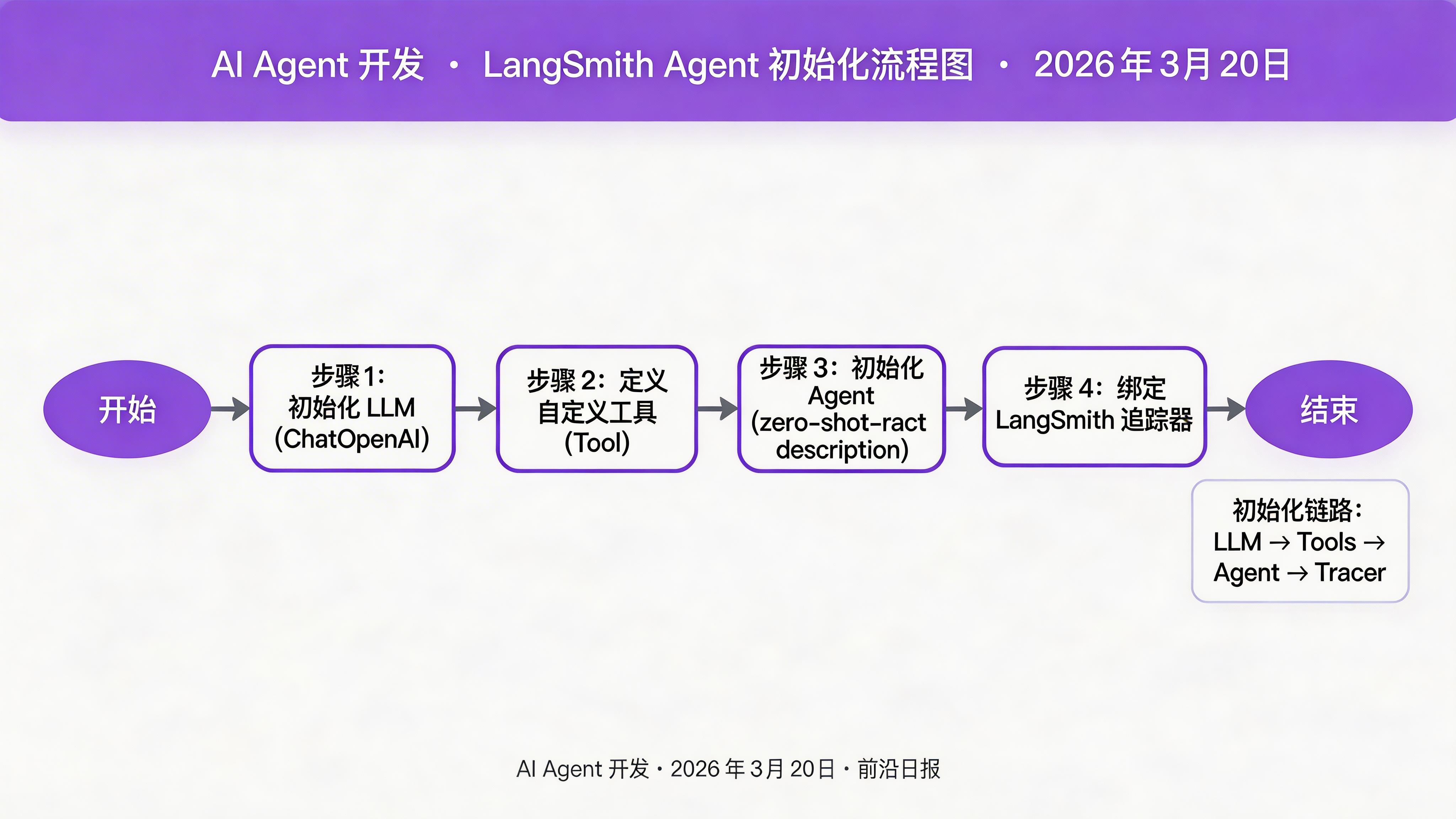
初始化 LangSmith 客户端与 Agent
首先配置 LangSmith 追踪器并初始化 Agent:
from langchain.agents import initialize_agent, Tool
from langchain_openai import ChatOpenAI
from langsmith import traceable
# 初始化 LLM
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# 定义自定义工具
def search_web(query: str) -> str:
"""搜索网络获取信息"""
return f"搜索 '{query}' 的结果..."
# 初始化工具列表
tools = [
Tool(
name="WebSearch",
func=search_web,
description="用于搜索实时信息"
)
]
# 初始化 Agent
agent = initialize_agent(
tools=tools,
llm=llm,
agent="zero-shot-react-description"
)
02
运行 Agent 并采集 Trace
使用 @traceable 装饰器自动记录执行轨迹:
from langsmith import traceable
@traceable(run_type="chain", name="Agent Execution")
def run_agent_with_trace(query: str):
"""运行 Agent 并记录 Trace"""
response = agent.run(query)
return response
# 执行测试
result = run_agent_with_trace("帮我写一封产品推广邮件")
print(f"结果:{result}")运行后,在 LangSmith 仪表盘查看完整的执行 Trace,包括:
- 每一步的工具调用和参数
- LLM 输入输出和 token 消耗
- 执行时间和错误信息

03
定义自定义评估指标
LangSmith 支持 Python 函数形式的自定义评估器:
from langsmith.evaluation import evaluate
from langsmith.schemas import Run, Example
def tool_selection_accuracy(run: Run, example: Example) -> dict:
"""评估工具选择准确率"""
# 检查是否调用了正确的工具
tool_calls = run.serialized.get('tool_calls', [])
expected_tool = example.outputs.get('expected_tool')
if expected_tool:
correct = any(call['name'] == expected_tool for call in tool_calls)
return {'score': 1.0 if correct else 0.0, 'key': 'tool_accuracy'}
return {'score': None}
def planning_quality(run: Run, example: Example) -> dict:
"""评估规划质量:步骤是否连贯、是否有冗余"""
steps = run.outputs.get('steps', [])
# 检查步骤连贯性
has_redundant = len(steps) > 10 # 简化示例
has_logical_flow = len(steps) >= 2
score = 0.5
if has_logical_flow and not has_redundant:
score = 1.0
elif has_redundant:
score = 0.3
return {'score': score, 'key': 'planning_quality'}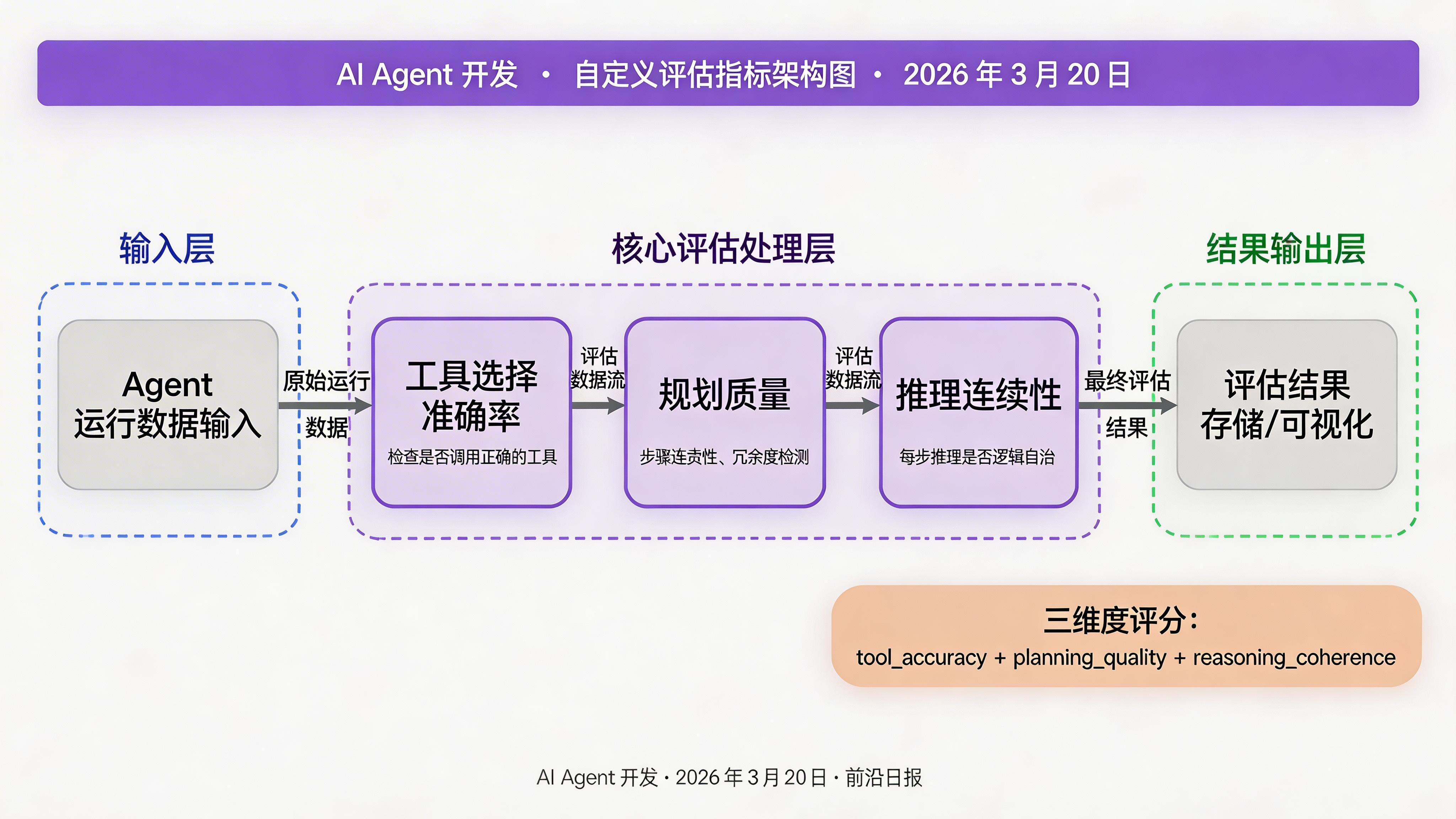
04
使用 LLM-as-Judge 进行自动评估
让 LLM 充当评判者,评估 Agent 输出质量:
from langsmith import Client
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
client = Client()
judge_llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
def llm_judge(run: Run, example: Example) -> dict:
"""使用 LLM 评估回答的相关性和准确性"""
prompt = ChatPromptTemplate.from_messages([
("system", "你是 AI Agent 评估专家。请评估以下回答的质量。"),
("human", """问题:{question}
期望答案:{expected}
实际回答:{actual}
请从以下维度打分(1-5 分):
1. 相关性:回答是否切题
2. 准确性:信息是否正确
3. 完整性:是否覆盖关键点
返回 JSON 格式:{{"relevance": 1-5, "accuracy": 1-5, "completeness": 1-5}}""")
chain = prompt | judge_llm
response = chain.invoke({
'question': example.inputs['query'],
'expected': example.outputs.get('expected_answer', 'N/A'),
'actual': run.outputs.get('output', '')
})
import json
scores = json.loads(response.content)
return {
'score': (scores['relevance'] + scores['accuracy'] + scores['completeness']) / 15,
'key': 'llm_judge'
}
05
执行批量评估
使用 LangSmith 的 evaluate 函数批量运行评估:
def run_agent(query: str) -> str:
"""Agent 运行函数"""
return agent.run(query)
# 准备测试数据集
test_examples = [
{"inputs": {"query": "帮我写一封产品推广邮件"}, "outputs": {"expected_tool": "WebSearch"}},
{"inputs": {"query": "查询今天北京的天气"}, "outputs": {"expected_tool": "WebSearch"}},
{"inputs": {"query": "总结这篇文章的核心观点"}, "outputs": {"expected_tool": None}},
]
# 执行评估
results = evaluate(
run_agent,
data=test_examples,
evaluators=[
tool_selection_accuracy,
planning_quality,
llm_judge
],
experiment_prefix="agent-eval-march-2026"
)
# 查看结果
for result in results:
print(f"得分:{result.scores}")
06
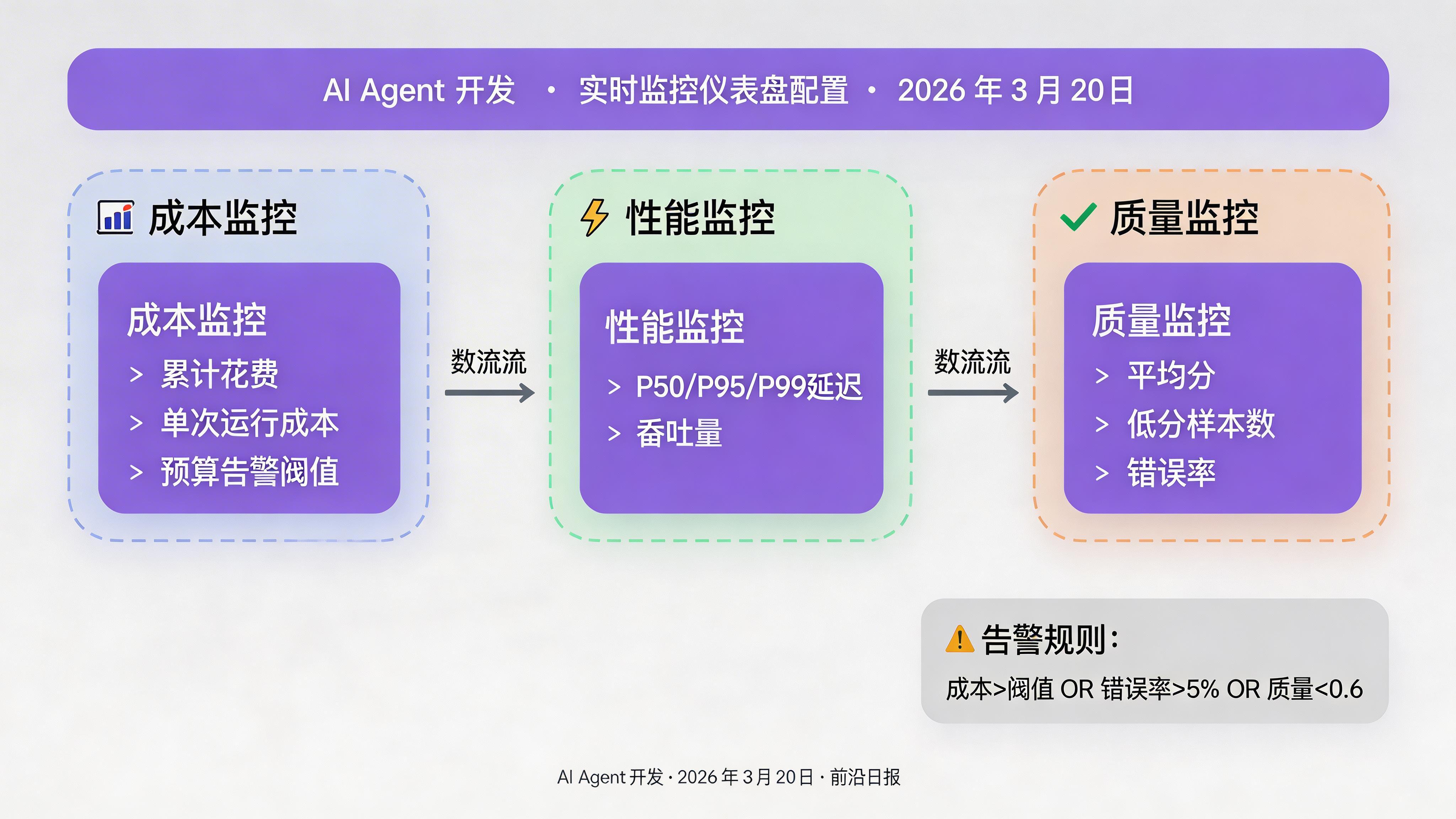
配置实时监控与告警
在生产环境部署监控:
from langsmith import Client
client = Client()
# 创建监控仪表盘
dashboard = client.create_dashboard(
name="Production Agent Monitor",
filters={
"project_name": "agent-production",
"time_range": "last_24h"
}
)
# 配置告警规则
def check_budget_threshold():
"""检查成本是否超出阈值"""
runs = client.list_runs(
project_name="agent-production",
execution_order=1
)
total_cost = sum(run.total_cost or 0 for run in runs)
if total_cost > 100: # 100 美元阈值
send_alert(f"⚠️ 成本告警:当前花费 ${total_cost:.2f}")
return total_cost生产建议:设置成本 tripwire(预算熔断器),当单次运行超过阈值时自动终止 Agent 执行,防止无限循环烧钱。
07
构建迭代优化闭环
基于评估结果持续优化 Agent:
# 从生产 Trace 中收集困难样本
hard_examples = client.list_examples(
dataset_name="production-failures",
filters={"score_lt": 0.5} # 低分样本
)
# 使用困难样本进行回归测试
regression_results = evaluate(
run_agent,
data=hard_examples,
evaluators=[llm_judge],
experiment_prefix="regression-test"
)
# 对比不同版本的表现
v1_scores = [r.scores['llm_judge'] for r in regression_results.v1]
v2_scores = [r.scores['llm_judge'] for r in regression_results.v2]
print(f"V1 平均分:{sum(v1_scores)/len(v1_scores):.2f}")
print(f"V2 平均分:{sum(v2_scores)/len(v2_scores):.2f}")
常见问题与解决方案
如何处理 Agent 执行中断或异常?
利用 LangSmith 的 Trace 回溯功能定位失败步骤。检查
run.error 字段获取错误详情,结合断点调试快速诊断问题。对于重试场景,在 @traceable 中设置 retries 参数。自定义指标如何保证评估准确性?
建议结合多种评估方式(自动规则 + LLM 评判 + 人工审核),并通过历史数据校准 LLM 评判器。定期抽样人工复核评估结果,调整评分标准。
如何控制评估成本和延迟?
合理设置评估频率和粒度:关键指标实时评估,次要指标抽样评估。使用便宜的模型(如 GPT-4o-mini)做初步评判,只对低分样本使用高端模型复核。利用缓存和批量处理优化性能。
进阶技巧与最佳实践
- Insights Agent 自动聚类:使用 LangSmith Insights 自动分析 Trace,发现潜在失败模式和使用趋势
- Agent Studio 可视化调试:设置断点动态调整 Agent 行为,支持单步执行查看中间状态
- 版本控制与 A/B 测试:为不同版本 Agent 创建独立 Project,对比关键指标推动持续优化
- 影子测试:新版本上线前,让新旧 Agent 同时运行,对比决策偏移度确保平稳过渡
- 分层评估策略:Skeleton Tests(毫秒级)+ Property Assertions(秒级)+ Budget Tripwires(分钟级)组合使用
关键收获:优秀的 Agent 评估系统不仅能发现问题,更能预防问题。通过 Trace 驱动的可观测性 + 多维度自动评估 + 实时告警,构建从开发到生产的闭环优化体系。
总结
- AI Agent 评估需要追踪整个决策链路,而非仅看最终输出
- LangSmith 提供 Trace 采集、多维度评估、实时监控的完整解决方案
- 自定义评估指标 + LLM-as-Judge 组合实现自动化质量量化
- 生产环境必须配置成本告警和熔断机制
- 基于评估结果构建迭代优化闭环,持续推动 Agent 性能提升