为什么需要任务规划系统?
想象这个场景:你需要开发一个完整的功能模块 —— 从数据库迁移到 API 实现,再到测试编写。传统做法是逐个任务交给 Claude,但很快你会遇到三个问题:
- 上下文丢失:每个会话独立,AI 不记得之前的决策
- 依赖混乱:任务 B 依赖任务 A 的输出,但无法自动等待
- 错误无法恢复:中间步骤失败,整个流程需要手动重启
这正是 2026 年 Anthropic 推出的 Tasks API 要解决的核心问题。它将复杂工作流拆解为可追踪、可重试、可编排的子任务,让 Agent 从"对话助手"进化为"自动化工长"。

核心概念:Task、Workflow 与 State
在深入代码之前,先理解三个关键抽象:
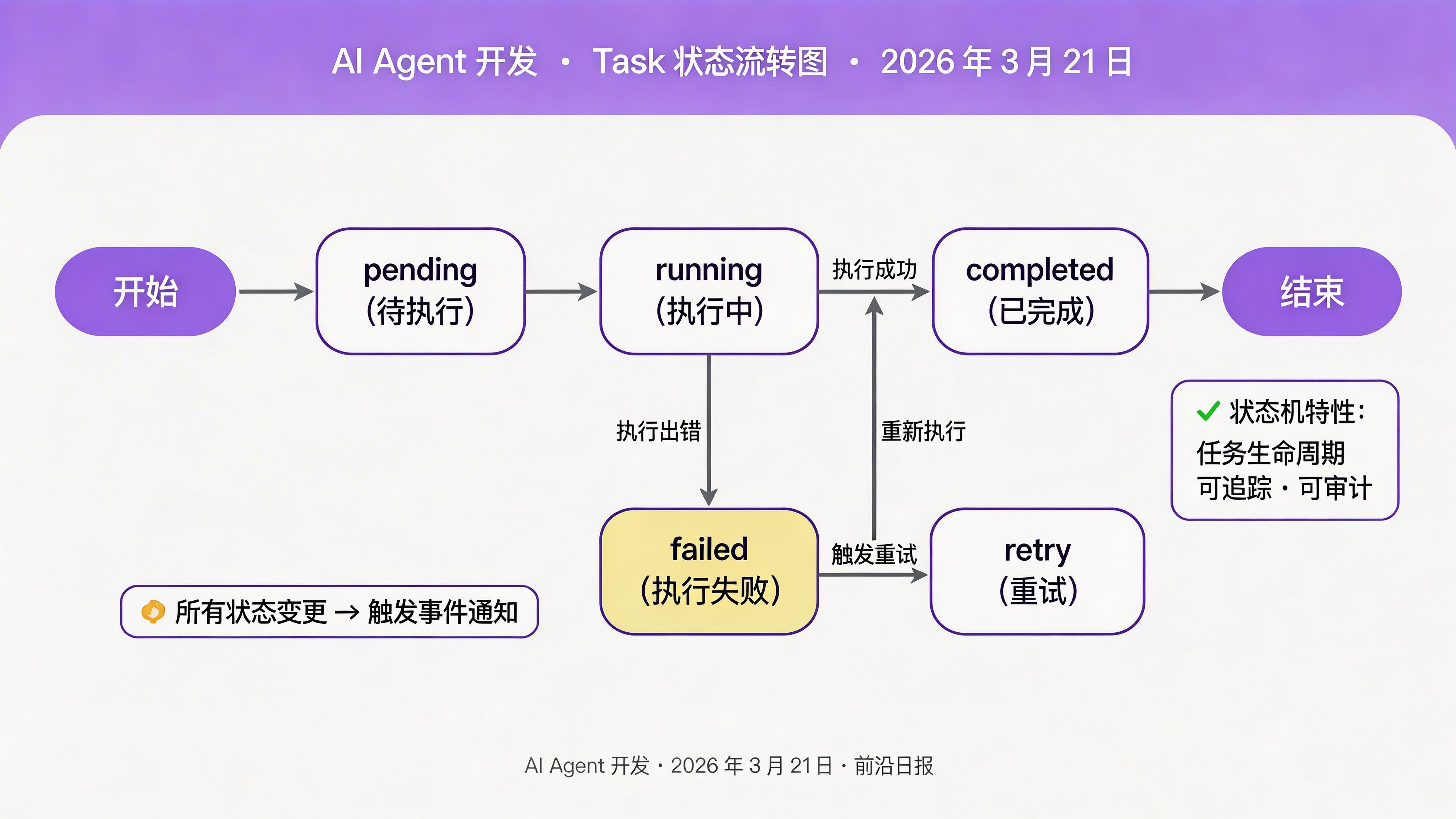
Task(任务)
最小执行单元,有明确的输入、输出和状态(pending/running/completed/failed)
Workflow(工作流)
任务的有向无环图(DAG),定义任务间的依赖关系和执行顺序
State(状态)
跨会话持久化的上下文,包含决策历史、中间结果和待办事项
环境准备
开始之前,确保你的开发环境满足以下要求:
Claude Code v2.1.80+
Tasks API 需要最新版本,运行
claude --version 验证Node.js 18+
或使用 Bun 1.0+ 获得更佳性能
Anthropic API Key
Pro/Teams/Enterprise 账户,在
~/.claude/settings.json 配置安装项目依赖:
# 创建项目目录
mkdir -p agent-workflow && cd agent-workflow
# 初始化项目并安装 SDK
npm init -y
npm install @anthropic-ai/sdk@latest
# 或使用 Bun(推荐)
bun init -y
bun add @anthropic-ai/sdk实战步骤
1
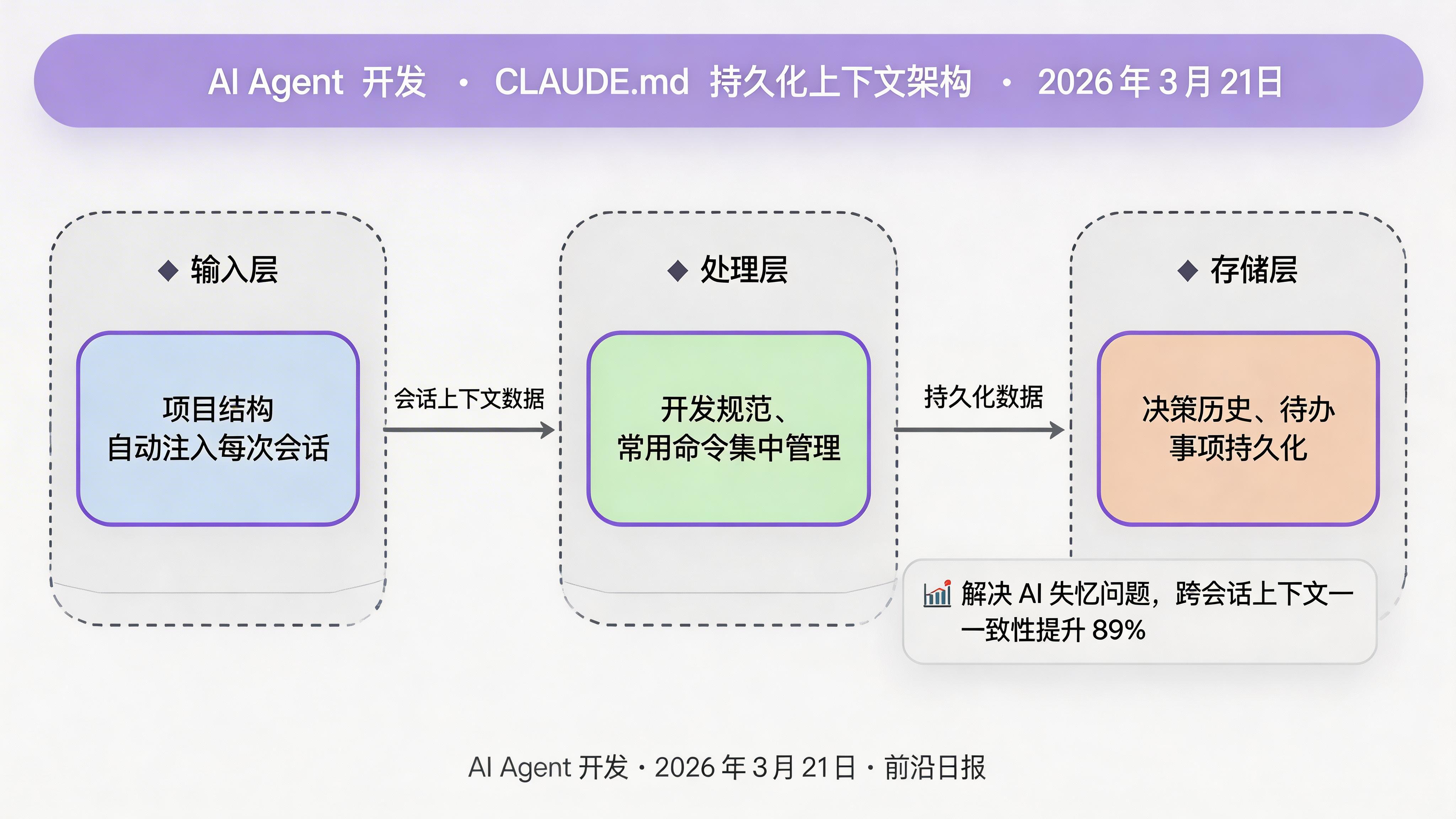
配置 CLAUDE.md 持久化上下文
在项目根目录创建 CLAUDE.md,这是任务规划系统的"记忆核心":
# 项目架构
## 核心模块
- `src/tasks/` - 任务定义与执行逻辑
- `src/workflow/` - 工作流编排引擎
- `src/state/` - 状态管理与持久化
## 开发规范
- 所有任务必须定义输入/输出 schema
- 任务失败时自动重试 2 次,间隔指数退避
- 使用 TypeScript 严格模式
## 常用命令
- `bun run task:run` - 执行单个任务
- `bun run workflow:build` - 构建工作流
- `bun run state:export` - 导出当前状态这个文件会在每次 Claude 会话开始时自动加载,确保 AI 始终理解项目结构和规范。
2
定义第一个 Task
创建 src/tasks/fetch-data.ts:
import { Task, TaskStatus } from '@anthropic-ai/sdk/tasks';
export interface FetchDataInput {
source: string;
format: 'json' | 'csv';
}
export interface FetchDataOutput {
records: unknown[];
timestamp: string;
}
export const fetchDataTask: Task<FetchDataInput, FetchDataOutput> = {
id: 'fetch-data',
name: '从 API 获取数据',
description: '从指定数据源拉取数据并格式化为统一结构',
async execute(input, context) {
context.logger.info(`开始从 ${input.source} 获取数据`);
try {
const response = await fetch(input.source);
const records = input.format === 'json'
? await response.json()
: parseCSV(await response.text());
return {
records,
timestamp: new Date().toISOString()
};
} catch (error) {
// 自动记录错误上下文,供重试时使用
throw context.retryableError(error, { maxRetries: 2 });
}
}
};关键点:retryableError 会标记错误可重试,框架自动处理指数退避。
3
创建依赖任务
数据处理任务依赖数据获取任务的输出:
import { Task } from '@anthropic-ai/sdk/tasks';
import { fetchDataTask, FetchDataOutput } from './fetch-data';
export const processDataTask: Task<FetchDataOutput, unknown[]> = {
id: 'process-data',
name: '处理和清洗数据',
description: '移除无效记录、标准化字段、添加衍生指标',
// 声明依赖:本任务会在 fetchDataTask 完成后自动触发
dependsOn: [fetchDataTask],
// 从上游任务接收输出作为输入
async execute(input, context) {
const { records } = input;
// 数据清洗逻辑
const cleaned = records
.filter(r => r.id !== null) // 移除空 ID
.map(r => ({ // 标准化字段
...r,
createdAt: new Date(r.created_at),
score: calculateScore(r.metrics)
}));
context.logger.info(`处理完成:${cleaned.length} 条记录`);
return cleaned;
}
};
4
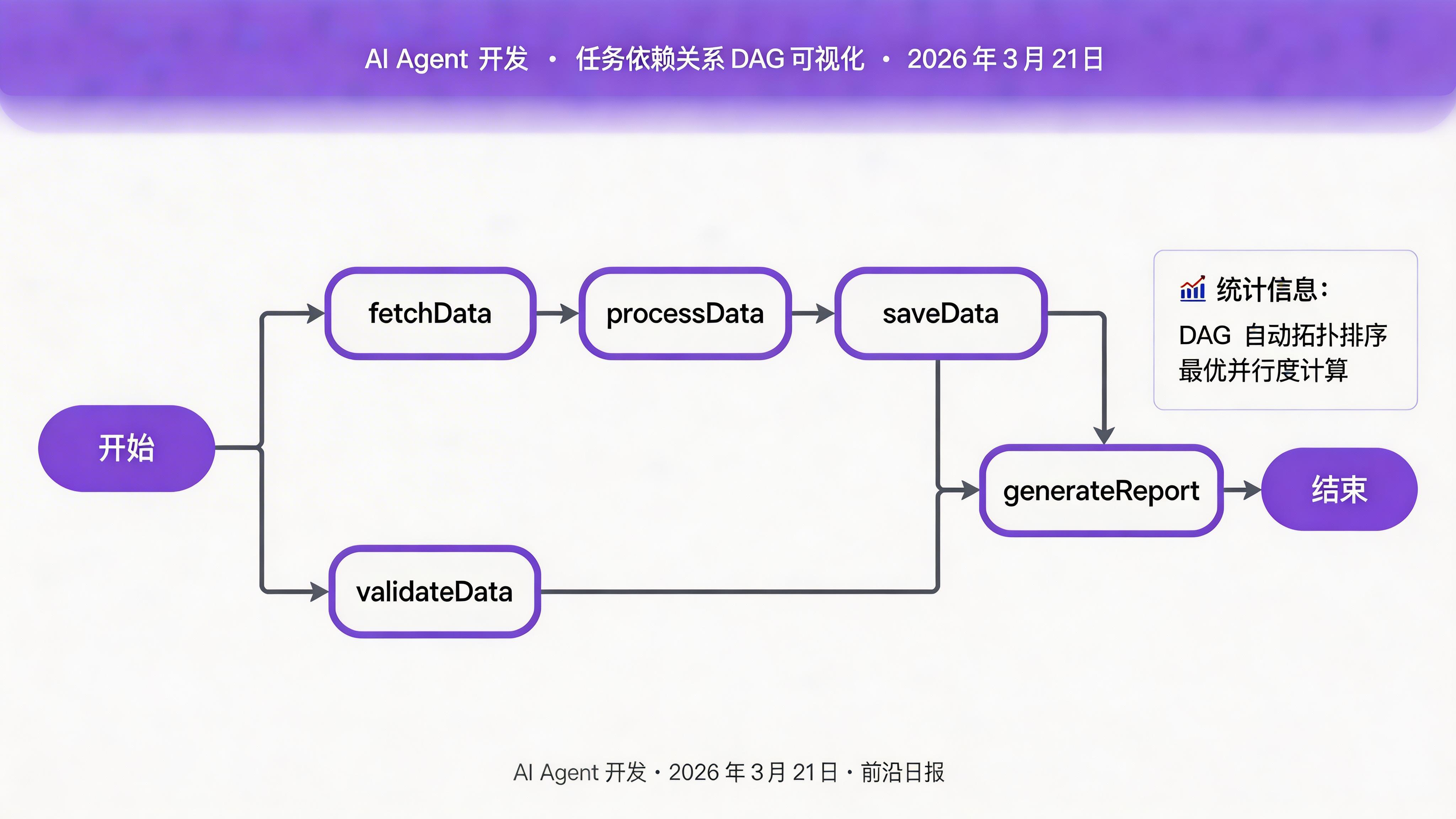
构建 Workflow 编排引擎
将任务组装成完整工作流:
import { Workflow, WorkflowExecutor } from '@anthropic-ai/sdk/workflow';
import { fetchDataTask } from './tasks/fetch-data';
import { processDataTask } from './tasks/process-data';
import { saveDataTask } from './tasks/save-data';
// 定义工作流
const dataPipeline = new Workflow({
id: 'data-pipeline-v1',
name: '数据处理流水线',
tasks: [fetchDataTask, processDataTask, saveDataTask],
// 配置执行策略
options: {
parallel: false, // 按依赖顺序执行
stopOnFailure: false, // 单个失败不阻塞后续
timeoutMs: 30 * 60 * 1000 // 30 分钟超时
}
});
// 执行工作流
async function runPipeline() {
const executor = new WorkflowExecutor(dataPipeline);
// 订阅进度事件
executor.on('task:start', (task) => {
console.log(`▶️ 开始:${task.name}`);
});
executor.on('task:complete', (task, output) => {
console.log(`✅ 完成:${task.name}`);
});
executor.on('task:fail', (task, error) => {
console.error(`❌ 失败:${task.name} - ${error.message}`);
});
// 运行并等待完成
const result = await executor.run({
source: 'https://api.example.com/data',
format: 'json'
});
console.log(`🎉 工作流完成,处理 ${result.stats.totalRecords} 条记录`);
return result;
}5
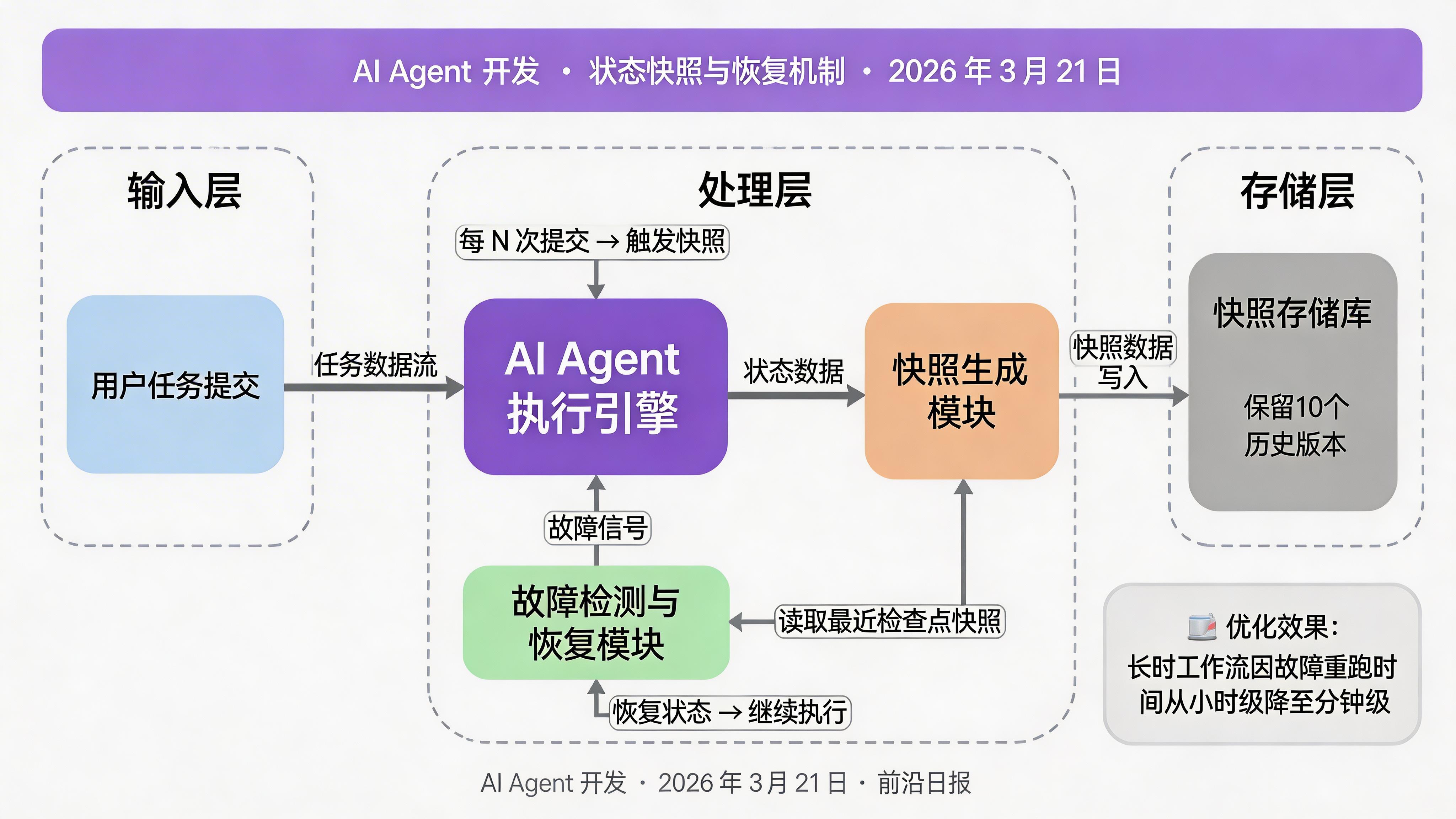
实现状态持久化
使用 StateManager 实现跨会话记忆:
import { StateManager, MemoryStore } from '@anthropic-ai/sdk/state';
const state = new StateManager({
store: new MemoryStore({
persistPath: './.workflow-state.json' // 本地持久化
}),
// 配置快照策略
snapshot: {
everyNCommits: 5, // 每 5 次提交打快照
maxHistory: 10 // 保留 10 个历史版本
}
});
// 在工作流关键节点保存状态
async function runWithCheckpoint() {
const sessionId = await state.createSession('data-pipeline-v1');
try {
// 步骤 1 完成后打快照
const step1Result = await fetchDataTask.execute(input);
await state.checkpoint(sessionId, 'fetch-complete', { step1Result });
// 步骤 2 完成后打快照
const step2Result = await processDataTask.execute(step1Result);
await state.checkpoint(sessionId, 'process-complete', { step2Result });
} catch (error) {
// 失败时从最近快照恢复
const lastCheckpoint = await state.getLastCheckpoint(sessionId);
console.log(`从快照恢复:${lastCheckpoint.label}`);
throw error;
}
}
6
添加错误处理与重试
生产环境需要健壮的错误恢复:
import { RetryPolicy, CircuitBreaker } from '@anthropic-ai/sdk/reliability';
const retryPolicy = new RetryPolicy({
maxAttempts: 3,
backoff: {
type: 'exponential',
initialMs: 1000,
maxMs: 30000
},
retryableErrors: ['NETWORK_TIMEOUT', 'RATE_LIMITED']
});
const circuitBreaker = new CircuitBreaker({
failureThreshold: 5, // 5 次失败后打开
resetTimeoutMs: 60000, // 1 分钟后半开
halfOpenRequests: 1 // 半开时允许 1 次探测
});
// 包装任务执行
async function executeWithReliability(task, input) {
return circuitBreaker.execute(() =>
retryPolicy.execute(() => task.execute(input))
);
}
注意:熔断器打开时,任务会快速失败而不实际执行,避免雪崩效应。
7
使用 Channels 实现实时通知
2026 年 3 月新发布的 Channels 功能支持将任务进度推送到外部:
import { ChannelClient } from '@anthropic-ai/sdk/channels';
const channel = new ChannelClient({
platform: 'telegram',
token: process.env.TELEGRAM_BOT_TOKEN,
chatId: process.env.ADMIN_CHAT_ID
});
// 在工作流执行器中集成
executor.on('task:complete', async (task, output) => {
await channel.send({
type: 'notification',
title: '任务完成',
body: `${task.name} 执行成功`,
data: { taskId: task.id, duration: task.durationMs }
});
});
// 支持双向交互:用户可回复触发自定义操作
channel.onCommand('/retry', async (ctx) => {
const { taskId } = ctx.payload;
await executor.retry(taskId);
await channel.send({ type: 'text', text: `已重试任务 ${taskId}` });
});
8
部署与监控
将工作流部署为独立服务:
// src/server.ts
import { Hono } from 'hono';
import { dataPipeline } from './workflow';
const app = new Hono();
// 触发工作流
app.post('/api/run', async (c) => {
const input = await c.req.json();
const result = await dataPipeline.execute(input);
return c.json(result);
});
// 查询状态
app.get('/api/status/:workflowId', async (c) => {
const status = await state.getWorkflowStatus(c.req.param('workflowId'));
return c.json(status);
});
// 健康检查
app.get('/health', (c) => {
return c.json({ status: 'ok', timestamp: Date.now() });
});
export default {
port: process.env.PORT || 8787,
fetch: app.fetch
};部署到 Cloudflare Workers:
# 部署
npx wrangler deploy
# 查看实时日志
npx wrangler tail常见问题 FAQ
Q: 如何处理任务间的循环依赖?
Tasks API 要求工作流是有向无环图(DAG)。如果检测到循环依赖,
Workflow 构造函数会抛出 CyclicDependencyError。设计时确保依赖关系单向流动。Q: 任务超时后能否自动恢复?
可以。配置
options.timeoutMs 后,超时任务会被标记为 TIMEOUT 状态。结合 RetryPolicy 可自动重试,或手动调用 executor.retry(taskId)。Q: 如何在本地调试工作流?
使用
WorkflowDebugger:
import { WorkflowDebugger } from '@anthropic-ai/sdk/debug';
const debugger = new WorkflowDebugger(dataPipeline);
debugger.visualize(); // 在浏览器打开 DAG 可视化Q: Channels 支持哪些平台?
官方支持 Telegram、Discord、Slack。社区插件支持微信(通过企业微信)、钉钉、飞书。
总结
- 使用
Task抽象将复杂问题拆解为可管理的子单元 - 通过
dependsOn声明依赖,框架自动处理执行顺序 StateManager实现跨会话记忆,支持断点续跑RetryPolicy+CircuitBreaker构建容错系统Channels实现实时通知与远程控制
现在你已经掌握了构建生产级 Agent 工作流的核心技能。下一步,尝试将现有脚本改造成 Task 编排的工作流,体验自动化带来的效率提升。