为什么需要 Playwright MCP?
2026 年,AI Agent 已经能够自动编写代码、分析数据、生成内容。但它们仍然无法像人类一样直接与 Web 应用交互——登录系统、填写表单、抓取动态渲染的内容、执行端到端测试。传统的网页自动化方案存在三大痛点:
- 脆弱的选择器:CSS/XPath 选择器对 DOM 结构变化极度敏感,一个 class 名改动就让脚本失效
- 缺乏语义理解:AI 无法"看懂"页面,只能通过坐标或像素匹配,无法处理动态内容
- 调试困难:失败时只有晦涩的堆栈信息,难以定位是网络问题、元素未加载还是选择器错误
Playwright MCP 服务器通过 Model Context Protocol (MCP) 标准协议,将 Playwright 的浏览器自动化能力暴露给 AI 模型。AI 可以使用自然语言命令浏览器执行操作,并获得结构化的 无障碍树(Accessibility Tree) 反馈,实现语义级交互而非像素级匹配。
核心概念:MCP 协议与 Playwright 的结合
MCP(Model Context Protocol)是 2025-2026 年 AI Agent 领域的标准协议,用于连接大语言模型与外部工具。Playwright MCP 服务器作为"翻译层",将 AI 的自然语言指令转换为 Playwright API 调用:
Planner Agent
解析用户意图,规划浏览器操作序列
MCP Server
注册 browser_navigate、browser_click 等工具
Accessibility Tree
返回结构化 DOM 语义,而非原始 HTML
Healer Agent
自动修复失效的选择器,实现自愈
环境准备
开始前确保已安装以下工具:
- Node.js 18+:MCP 服务器运行环境
- TypeScript 5+:类型安全的开发体验
- Playwright:浏览器自动化框架
- @modelcontextprotocol/sdk:MCP 协议实现
# 1. 创建项目目录
mkdir playwright-mcp-server
cd playwright-mcp-server
# 2. 初始化 npm 项目
npm init -y
# 3. 安装核心依赖
npm install playwright @modelcontextprotocol/sdk zod
# 4. 安装 TypeScript 及类型定义
npm install -D typescript @types/node @types/playwright
# 5. 初始化 TypeScript 配置
npx tsc --init修改 tsconfig.json,确保以下配置:
{
"compilerOptions": {
"target": "ES2022",
"module": "Node16",
"moduleResolution": "Node16",
"outDir": "./dist",
"rootDir": "./src",
"strict": true,
"esModuleInterop": true,
"skipLibCheck": true
}
}步骤 1:搭建 MCP 服务器骨架
创建 src/index.ts,实现最小可用的 MCP 服务器:
import { McpServer } from '@modelcontextprotocol/sdk/server/mcp.js';
import { StdioServerTransport } from '@modelcontextprotocol/sdk/server/stdio.js';
import { z } from 'zod';
import { chromium, Browser, Page } from 'playwright';
// 创建 MCP 服务器实例
const server = new McpServer({
name: 'playwright-mcp',
version: '1.0.0',
description: 'Browser automation via Playwright'
});
// 全局浏览器状态
let browser: Browser | null = null;
let page: Page | null = null;
// 注册工具:启动浏览器
server.tool(
'browser_launch',
'启动 Chromium 浏览器实例',
{
headless: z.boolean().default(true).describe('是否无头模式')
},
async ({ headless }) => {
browser = await chromium.launch({ headless });
page = await browser.newPage();
return {
content: [{ type: 'text', text: 'Browser launched successfully' }]
};
}
);
// 注册工具:导航到 URL
server.tool(
'browser_navigate',
'打开指定 URL',
{
url: z.string().url().describe('目标网址')
},
async ({ url }) => {
if (!page) throw new Error('Browser not launched');
await page.goto(url, { waitUntil: 'networkidle' });
return {
content: [{ type: 'text', text: `Navigated to ${url}` }]
};
}
);
// 启动服务器
async function main() {
const transport = new StdioServerTransport();
await server.connect(transport);
console.error('Playwright MCP Server running on stdio');
}
main().catch(console.error);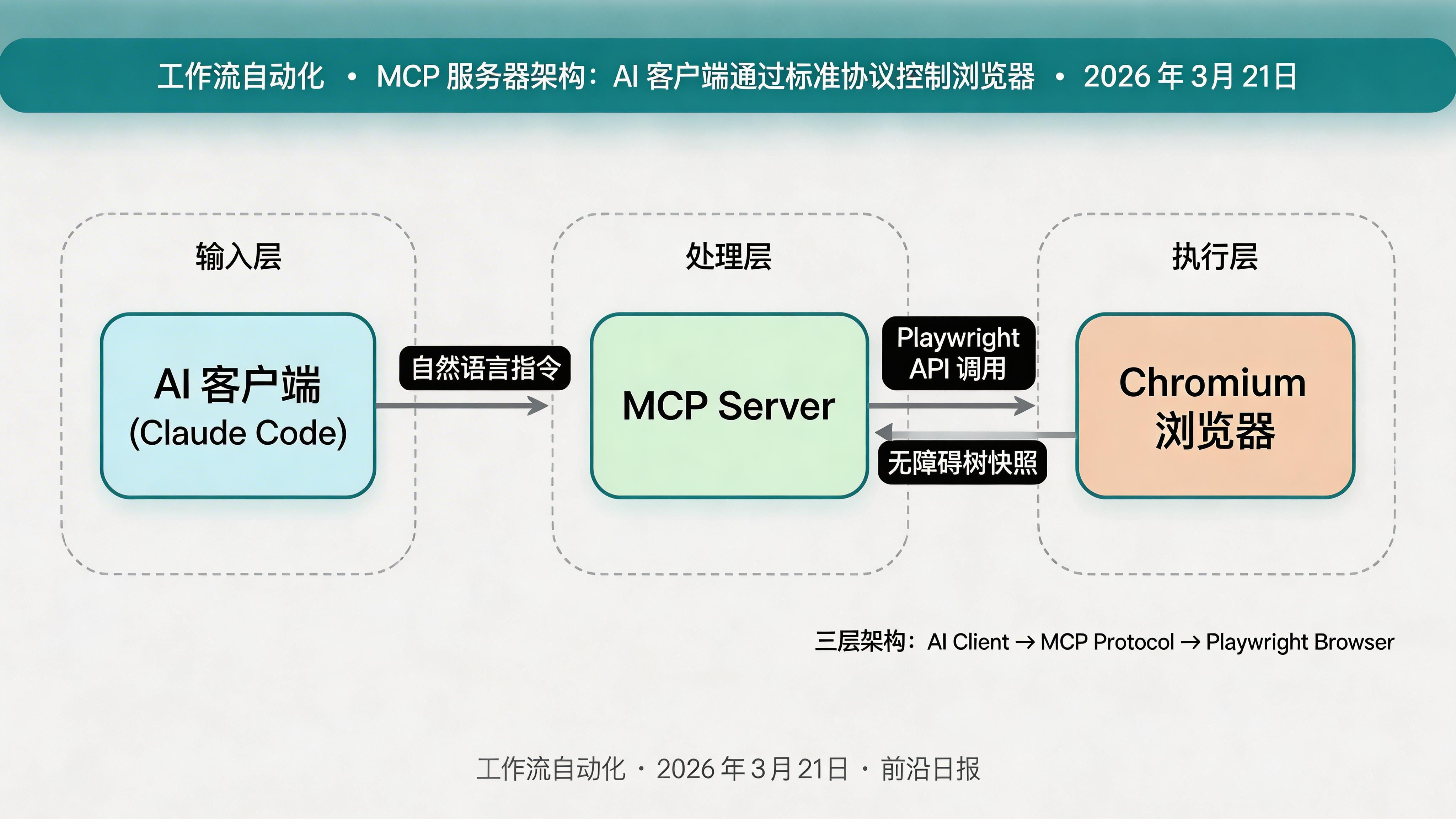
步骤 2:实现核心浏览器操作
扩展服务器,添加点击、输入、截图等常用操作:
// 点击元素
server.tool(
'browser_click',
'点击页面上的元素',
{
selector: z.string().describe('CSS 选择器或 getByRole 文本')
},
async ({ selector }) => {
if (!page) throw new Error('Browser not launched');
await page.click(selector);
return {
content: [{ type: 'text', text: `Clicked: ${selector}` }]
};
}
);
// 输入文本
server.tool(
'browser_type',
'在输入框中输入文本',
{
selector: z.string().describe('输入框选择器'),
text: z.string().describe('要输入的文本')
},
async ({ selector, text }) => {
if (!page) throw new Error('Browser not launched');
await page.fill(selector, text);
return {
content: [{ type: 'text', text: `Typed "${text}" into ${selector}` }]
};
}
);
// 截取屏幕
server.tool(
'browser_screenshot',
'截取当前页面截图',
{
name: z.string().optional().describe('截图文件名')
},
async ({ name }) => {
if (!page) throw new Error('Browser not launched');
const screenshot = await page.screenshot({ type: 'png' });
const base64 = screenshot.toString('base64');
return {
content: [{
type: 'image',
data: base64,
mimeType: 'image/png'
}]
};
}
);
// 获取无障碍树(AI 可读的页面结构)
server.tool(
'browser_snapshot',
'获取页面可访问性快照',
{},
async () => {
if (!page) throw new Error('Browser not launched');
const snapshot = await page.accessibility.snapshot();
return {
content: [{ type: 'text', text: JSON.stringify(snapshot, null, 2) }]
};
}
);
步骤 3:编译与运行
编译 TypeScript 并启动服务器:
# 编译
npx tsc
# 运行服务器
node dist/index.js此时服务器等待 stdin 输入。接下来配置 AI 客户端连接。
步骤 4:连接 Claude Code
在项目根目录创建 CLAUDE.md,配置 MCP 服务器:
{
"mcpServers": {
"playwright": {
"command": "node",
"args": ["/absolute/path/to/playwright-mcp-server/dist/index.js"],
"env": {}
}
}
}启动 Claude Code,验证工具已加载:
claude --debug现在可以使用自然语言命令控制浏览器:
示例对话:
用户:打开 https://github.com 并搜索 "playwright mcp"
Claude: (调用 browser_launch → browser_navigate → browser_type → browser_click)
已完成,搜索结果如下...
用户:打开 https://github.com 并搜索 "playwright mcp"
Claude: (调用 browser_launch → browser_navigate → browser_type → browser_click)
已完成,搜索结果如下...

步骤 5:高级特性——自愈选择器
传统自动化脚本的痛点是选择器脆弱。使用 AI + MCP 可以实现自愈:
// 智能查找元素(支持多种策略)
server.tool(
'browser_find',
'使用 AI 语义查找元素',
{
description: z.string().describe('元素描述,如"登录按钮"')
},
async ({ description }) => {
if (!page) throw new Error('Browser not launched');
// 获取无障碍树
const snapshot = await page.accessibility.snapshot();
// AI 分析 snapshot,返回最佳选择器
// (此处调用 LLM API,省略)
const selector = await aiFindSelector(snapshot, description);
return {
content: [{ type: 'text', text: `Found: ${selector}` }]
};
}
);当页面结构变化时,AI 可以重新分析无障碍树并找到新的选择器,无需人工维护脚本。
步骤 6:Docker 部署(生产环境)
创建 Dockerfile,确保环境一致性:
FROM mcr.microsoft.com/playwright:v1.42.0-jammy
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
RUN npm run build
# 安装 Playwright 浏览器
RUN npx playwright install chromium
CMD ["node", "dist/index.js"]构建并运行:
docker build -t playwright-mcp .
docker run -d playwright-mcp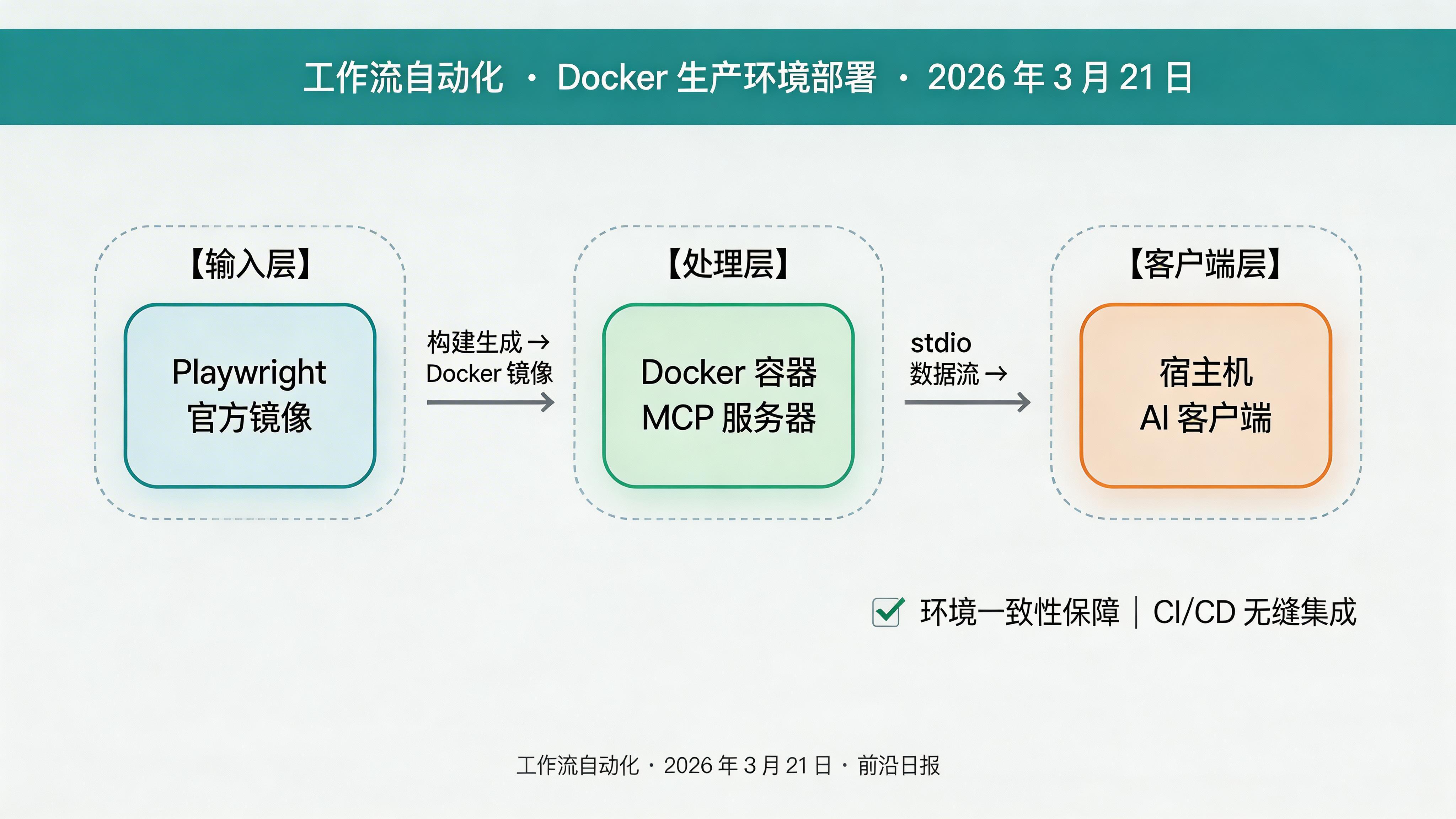
常见问题 FAQ
Q: 为什么使用无障碍树而不是直接解析 HTML?
无障碍树(Accessibility Tree)是浏览器为辅助功能 API 生成的语义化表示,它过滤了纯装饰性元素,保留了角色(role)、名称(name)、状态等关键信息。AI 基于无障碍树做决策更稳定,不受 class 名、DOM 嵌套变化影响。
Q: 如何处理需要登录的网站?
有两种方案:1) 在启动浏览器时加载已保存的 Cookie(
browser.newContext({ storageState: 'auth.json' }));2) 让 AI 自动执行登录流程(导航到登录页 → 填写表单 → 提交)。推荐方案 1,避免每次重复登录。Q: MCP 服务器占用多少 token?
根据实测,Playwright MCP 的 6 个工具定义约占用 13,600 token。优化方法:1) 精简工具描述;2) 将相关操作合并为复合工具;3) 使用 CLI 命令代替 MCP(当不需要 AI 自主决策时)。
Q: 能同时控制多个浏览器标签页吗?
可以。扩展服务器维护一个 Page 映射表,通过
pageId 参数区分不同标签页。AI 可以使用 browser_new_tab 创建新页面,然后用 browser_switch 切换上下文。最佳实践总结
- ✓ 使用 getByRole 选择器:比 CSS/XPath 更稳定,与无障碍树对齐
- ✓ 启用视频录制:调试失败时回放完整操作过程(
recordVideo: { dir: 'videos/' }) - ✓ 隔离浏览器上下文:每个任务使用独立的 ephemeral context,避免状态污染
- ✓ 限制文件访问:生产环境禁用本地文件系统访问,仅允许白名单域名
- ✓ 监控 token 用量:记录每次工具调用的 token 消耗,优化高频工具的描述长度
- ✓ 集成 CI/CD:将 MCP 服务器打包为 Docker 镜像,在 GitHub Actions 中自动运行测试
下一步
掌握 Playwright MCP 服务器开发后,你可以:
- 构建自动化测试生成器:AI 分析需求文档,自动生成端到端测试脚本
- 开发 Web scraping 工具:AI 识别页面结构,提取结构化数据
- 创建 UI 审计系统:AI 检查可访问性问题,生成修复建议
- 实现 RPA 流程:AI 操作企业内部系统,完成跨应用的工作流