2026 年的 AI 应用开发已经不再满足于单一的 LLM 调用。企业级应用需要多个 AI 角色协同工作:研究员负责收集信息、分析师负责整理数据、写手负责生成内容、审核员负责质量把关。这些角色需要共享状态、传递消息、协调执行顺序——这正是 LangGraph 的设计目标。
本教程将带你从零开始构建一个完整的多 Agent 协作系统,涵盖状态图定义、Agent 节点设计、条件路由、工具调用等核心概念。你将学会如何使用 LangGraph 的图结构编排复杂工作流,让多个 AI 角色像真实团队一样高效协作。
准备工作:环境搭建与依赖安装
首先创建项目目录并安装依赖:
mkdir langgraph-multi-agent
cd langgraph-multi-agent
python -m venv venv
source venv/bin/activate # Windows 使用:venv\Scripts\activate
# 安装核心依赖
pip install langgraph langchain langchain-anthropic langchain-core创建 .env 文件配置 API 密钥:
ANTHROPIC_API_KEY=sk-ant-xxxxxxxxxxxx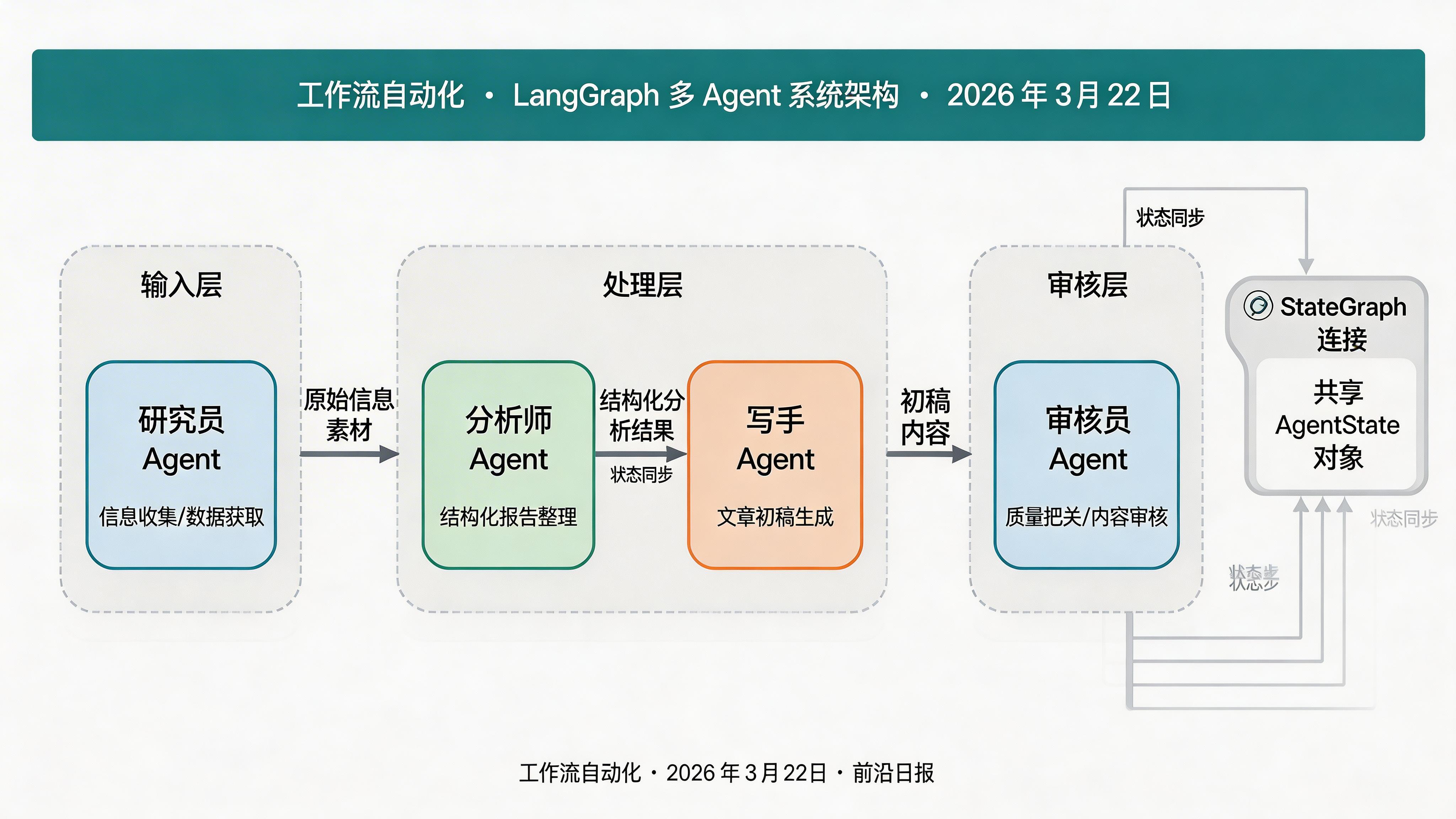
核心概念:LangGraph 状态图模型
LangGraph 的核心是使用有向图来表示工作流。图中的每个节点代表一个 Agent 或操作,边代表执行流程。与传统 DAG(有向无环图)不同,LangGraph 支持循环,这使得 Agent 可以进行多轮反思和改进。
关键区别:LangChain 的 Chain 是线性的,LCEL 可以构建 DAG,但只有 LangGraph 支持带状态的回环。这意味着你的 Agent 可以根据输出结果决定是否需要重新执行某个步骤。
状态图由三部分组成:
- State:共享的状态对象,所有节点都可以读写
- Nodes:执行具体任务的函数(如调用 LLM、执行工具)
- Edges:定义节点之间的执行顺序,支持条件路由
实战步骤:构建内容生成多 Agent 系统
定义状态 Schema
使用 Python 的 TypedDict 定义状态结构,包含输入、中间结果和最终输出:
from typing import TypedDict, List, Annotated
from langgraph.graph import StateGraph, END
import operator
class AgentState(TypedDict):
"""多 Agent 协作系统的共享状态"""
topic: str # 用户输入的选题
research_notes: List[str] # 研究员收集的笔记
analysis_report: str # 分析师的分析报告
draft_content: str # 写手生成的初稿
feedback: List[str] # 审核员的反馈
final_content: str # 最终内容
iteration_count: int # 迭代次数,防止死循环使用 Annotated 可以定义状态的归约逻辑。例如 operator.add 表示每次写入时追加到列表而不是覆盖。
创建 Agent 节点
每个 Agent 是一个独立的函数,接收当前状态并返回更新:
from langchain_anthropic import ChatAnthropic
from langchain_core.messages import HumanMessage, SystemMessage
# 初始化 LLM
llm = ChatAnthropic(model="claude-sonnet-4-20250514", temperature=0.7)
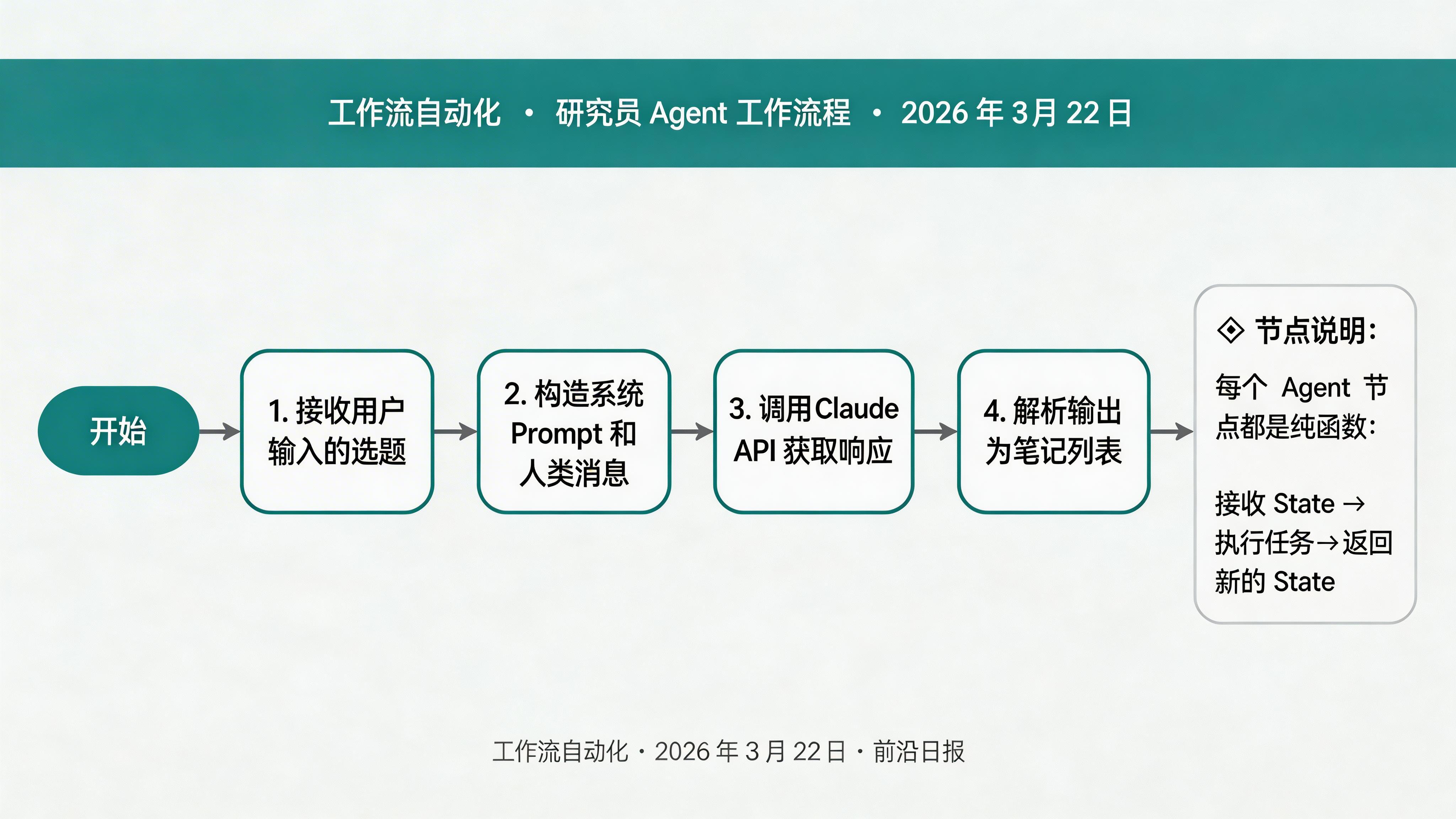
def researcher_node(state: AgentState) -> dict:
"""研究员:收集主题相关资料"""
topic = state["topic"]
system_prompt = """你是一个专业的研究员。你的任务是收集关于指定主题的最新资料。
请列出 5-8 个关键信息点,每个信息点包含:
- 核心概念定义
- 2026 年的最新进展
- 实际应用案例
用简洁的列表格式输出。"""
response = llm.invoke([
SystemMessage(content=system_prompt),
HumanMessage(content=f"请研究以下主题:{topic}")
])
# 将响应拆分为笔记列表
notes = [line.strip() for line in response.content.split('\n') if line.strip()]
return {
"research_notes": notes,
"iteration_count": state.get("iteration_count", 0) + 1
}
创建分析师 Agent
def analyst_node(state: AgentState) -> dict:
"""分析师:整理研究笔记为结构化报告"""
notes = state["research_notes"]
topic = state["topic"]
system_prompt = """你是一个资深分析师。你的任务是将研究员提供的零散笔记整理成结构化报告。
报告结构:
1. 核心概念(200 字)
2. 技术原理(300 字)
3. 应用场景(列举 3-5 个)
4. 发展趋势
使用 Markdown 格式,确保专业术语准确。"""
notes_text = "\n".join(notes)
response = llm.invoke([
SystemMessage(content=system_prompt),
HumanMessage(content=f"主题:{topic}\n\n研究笔记:\n{notes_text}")
])
return {"analysis_report": response.content}创建写手 Agent
def writer_node(state: AgentState) -> dict:
"""写手:根据分析报告生成文章初稿"""
analysis = state["analysis_report"]
topic = state["topic"]
system_prompt = """你是一个经验丰富的技术文章写手。你的任务是将分析报告转化为面向开发者的实战教程。
文章结构:
- 开篇:痛点引入 + 本教程解决什么
- 准备工作:环境搭建
- 核心步骤:5-8 个步骤,每个步骤含代码示例
- 常见问题与解决方案
- 总结
使用中文写作,代码示例使用 Python,字数 2000-3000 字。"""
response = llm.invoke([
SystemMessage(content=system_prompt),
HumanMessage(content=f"主题:{topic}\n\n分析报告:\n{analysis}")
])
return {"draft_content": response.content}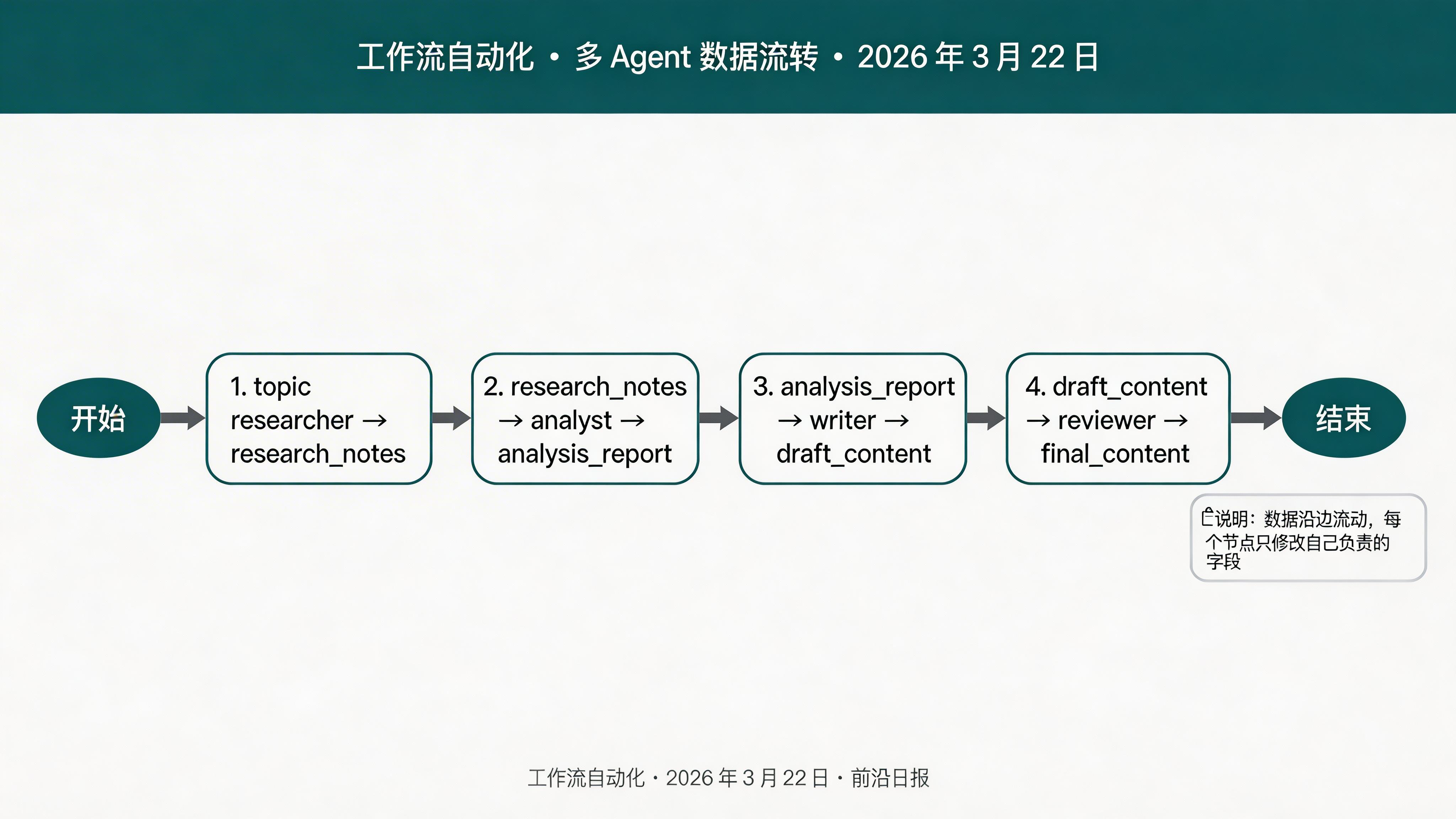
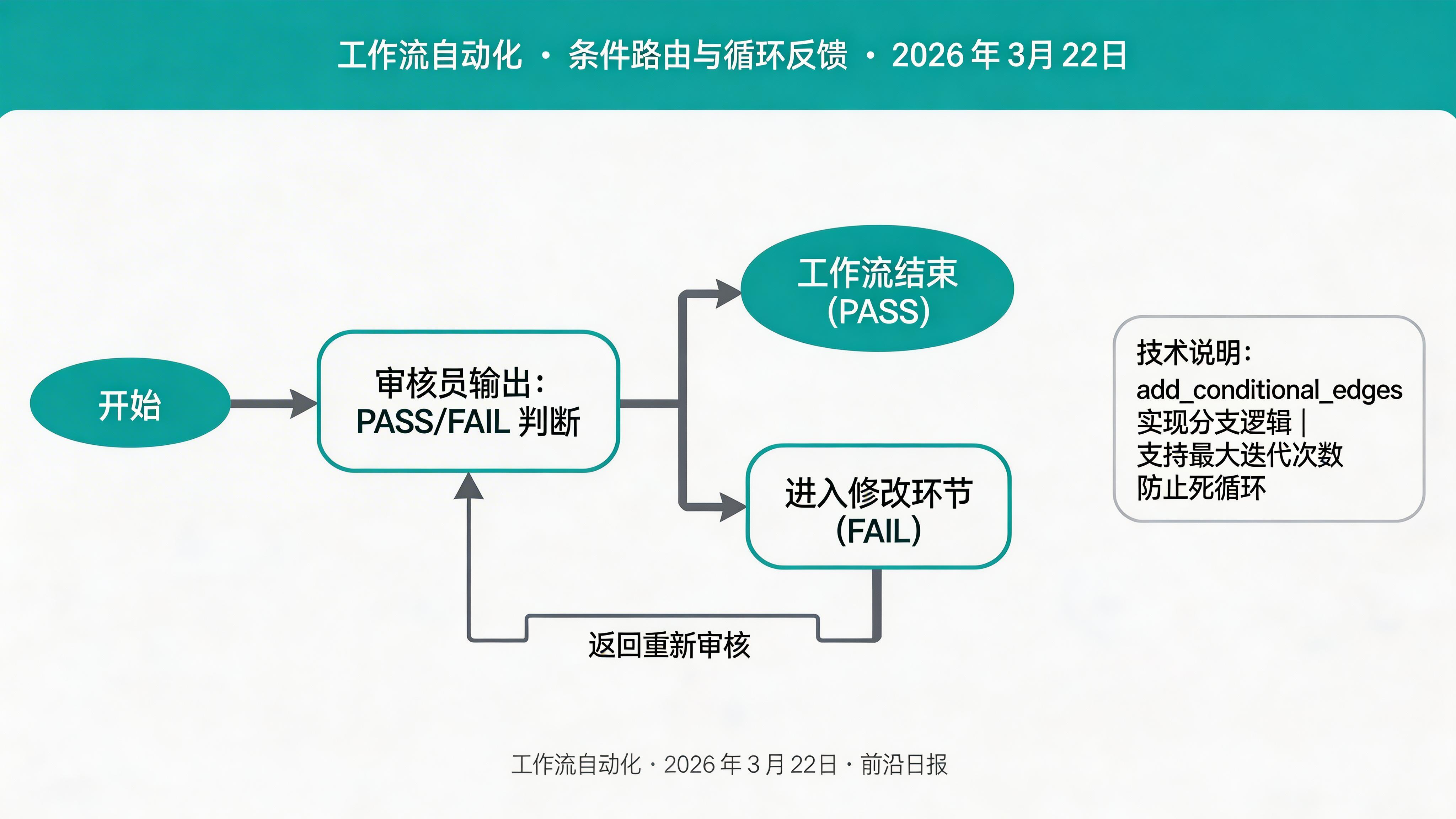
创建审核员 Agent 与条件路由
审核员负责质量把关,如果文章不达标则返回写手重新修改:
def reviewer_node(state: AgentState) -> dict:
"""审核员:检查文章质量并提供反馈"""
draft = state["draft_content"]
topic = state["topic"]
system_prompt = """你是一个严格的 technical editor。请检查文章:
1. 字数是否在 2000-3000 字之间
2. 是否有清晰的代码示例
3. 步骤是否完整可执行
4. 是否有开篇引入和总结
如果通过检查,返回 "PASS"。否则列出具体的修改意见。"""
response = llm.invoke([
SystemMessage(content=system_prompt),
HumanMessage(content=f"主题:{topic}\n\n文章草稿:\n{draft[:5000]}") # 截断避免 token 超限
])
feedback = response.content
passed = "PASS" in feedback
return {
"feedback": [feedback] if not passed else [],
"final_content": draft if passed else ""
}
def should_revise(state: AgentState) -> str:
"""条件路由:决定是否需要修改"""
if state["feedback"]: # 有反馈说明需要修改
return "revise"
return "publish"
def revise_node(state: AgentState) -> dict:
"""修改节点:根据审核反馈改进文章"""
draft = state["draft_content"]
feedback = state["feedback"][-1] # 取最新反馈
system_prompt = """你是一个乐于接受反馈的写手。请根据编辑的反馈修改文章。
保持原文结构,针对性地解决反馈中提到的问题。"""
response = llm.invoke([
SystemMessage(content=system_prompt),
HumanMessage(content=f"原文:\n{draft}\n\n修改意见:\n{feedback}")
])
return {
"draft_content": response.content,
"iteration_count": state["iteration_count"] + 1
}
构建状态图并执行
将所有节点连接成图:
# 创建状态图
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("researcher", researcher_node)
workflow.add_node("analyst", analyst_node)
workflow.add_node("writer", writer_node)
workflow.add_node("reviewer", reviewer_node)
workflow.add_node("revise", revise_node)
# 设置入口
workflow.set_entry_point("researcher")
# 添加边:顺序执行
workflow.add_edge("researcher", "analyst")
workflow.add_edge("analyst", "writer")
workflow.add_edge("writer", "reviewer")
# 条件边:审核结果决定下一步
workflow.add_conditional_edges(
"reviewer",
should_revise,
{
"revise": "revise",
"publish": END
}
)
# 修改后返回审核
workflow.add_edge("revise", "reviewer")
# 编译图
app = workflow.compile()执行工作流:
# 运行
result = app.invoke({
"topic": "LangGraph 工作流编排实战",
"iteration_count": 0
})
print("最终内容:")
print(result["final_content"])
print(f"\n迭代次数:{result['iteration_count']}")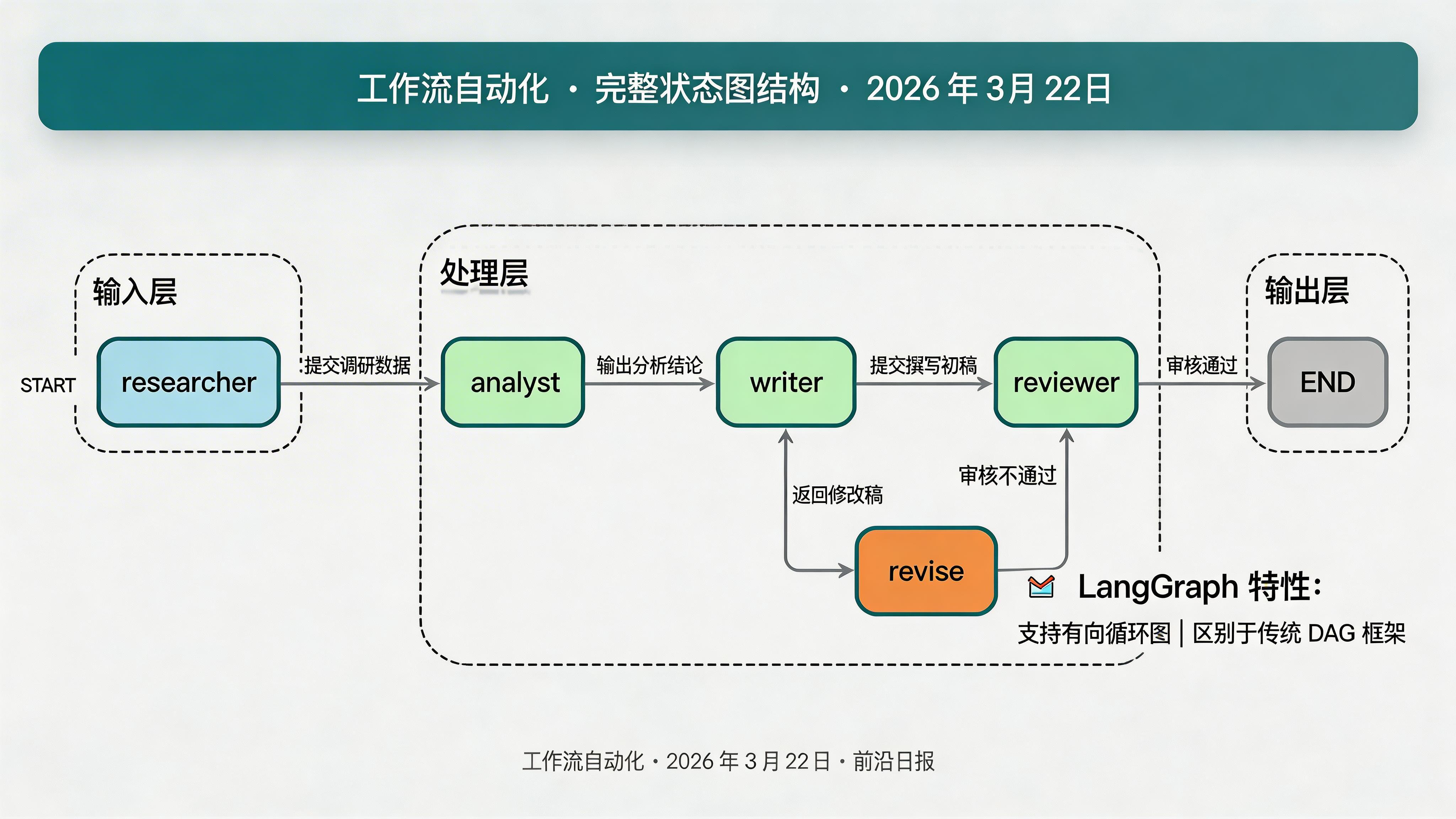
添加可视化和调试
LangGraph 支持将状态图可视化,便于调试:
# 生成 Mermaid 流程图
from langgraph.graph import GraphVisualizer
visualizer = GraphVisualizer(workflow)
mermaid_code = visualizer.to_mermaid()
print(mermaid_code)在 Jupyter 中可以直接渲染:
from IPython.display import display, Markdown
display(Markdown(mermaid_code))防止死循环:在条件路由中务必设置最大迭代次数。可以在每个节点检查 iteration_count,超过阈值强制结束。
进阶技巧:工具调用与记忆管理
LangGraph 可以与 LangChain 的工具系统无缝集成。例如让研究员使用搜索引擎:
from langchain_community.tools import DuckDuckGoSearchResults
search = DuckDuckGoSearchResults()
def researcher_with_tools(state: AgentState) -> dict:
"""带工具的研究员"""
topic = state["topic"]
# 使用搜索工具
search_results = search.run(topic)
# 让 LLM 总结搜索结果
response = llm.invoke([
SystemMessage(content="你是研究员,请总结搜索结果。"),
HumanMessage(content=f"搜索结果:{search_results}")
])
return {
"research_notes": [response.content],
"iteration_count": state.get("iteration_count", 0) + 1
}对于长对话场景,可以使用 LangGraph 的检查点系统保存状态:
from langgraph.checkpoint import MemorySaver
# 使用内存检查点
memory = MemorySaver()
app = workflow.compile(checkpointer=memory)
# 保存线程 ID
config = {"configurable": {"thread_id": "conversation-123"}}
# 多次调用会延续状态
result1 = app.invoke({"topic": "主题 1"}, config)
result2 = app.invoke({"topic": "主题 2"}, config) # 继承之前的状态常见问题与解决方案
draft_content,不需要 research_notes。也可以使用 LangChain 的 RecursiveCharacterTextSplitter 分块处理长文本。app.stream() 代替 app.invoke() 可以实时看到每个节点的输出。也可以启用 LangSmith 追踪,可视化查看每次 LLM 调用的输入输出。AgentState 中定义结构化的字段,如 List[dict] 存储结构化数据。确保每个节点只修改自己负责的字段,避免覆盖其他节点的数据。workflow.add_parallel_nodes()。例如可以并行运行多个研究员,各自负责不同的子主题。总结
- 掌握了 LangGraph 状态图的核心概念:State、Nodes、Edges
- 学会了创建多 Agent 节点并定义职责边界
- 实现了条件路由和循环反馈机制
- 集成了工具调用和记忆管理功能
- 了解了防止死循环和 Token 超限的最佳实践