你在构建企业知识库时是否遇到过这些问题:
- 用户问"哪些客户受到了服务 X 影响",传统 RAG 只能返回含"客户"和"服务 X"的文档片段,无法跨文档关联
- 向量检索返回的内容看似相关,但缺乏实体间的逻辑关系,答案支离破碎
- 面对"请总结过去季度所有与 AI 相关的战略决策"这类全局主题问题,传统 RAG 束手无策
这就是为什么 Microsoft GraphRAG 在 2026 年成为企业级 RAG 的事实标准。它通过在索引阶段构建知识图谱,在检索时利用图结构进行多跳推理和全局摘要,解决了传统向量 RAG 的三大痛点:
- 跨文档关联:通过实体 - 关系图连接分散信息
- 多跳推理:A→B→C 的链式查询不再是难题
- 全局理解:社区发现算法自动识别主题簇并生成摘要
本教程将带你从零开始,使用 Microsoft GraphRAG 框架构建一个支持图文混合检索的企业级知识库。你将掌握完整的实战流程:环境搭建、文档加载、图谱构建、查询优化,以及生产环境的最佳实践。
准备工作:环境与依赖
核心概念:Graph RAG vs 传统 RAG
在开始实战前,我们先理解 Graph RAG 的核心原理。下图展示了两种架构的关键差异:

传统 RAG 的检索流程是线性的:文档切分 → 向量嵌入 → 相似性检索 → LLM 生成。而 Graph RAG 在此基础上增加了图结构层:
- 索引阶段:从文本中提取实体(Entity)和关系(Relation),构建知识图谱
- 社区发现:使用 Leiden 算法识别图中的紧密连接簇(Community)
- 分层摘要:为每个社区生成摘要,形成从微观实体到宏观主题的层级结构
- 查询阶段:同时检索向量、实体、关系和社区摘要,提供多粒度上下文
步骤 1:初始化项目与环境
创建虚拟环境并安装 GraphRAG
python -m venv .venv
source .venv/bin/activate # Linux/macOS
# 或 .venv\Scripts\activate # Windows
pip install graphrag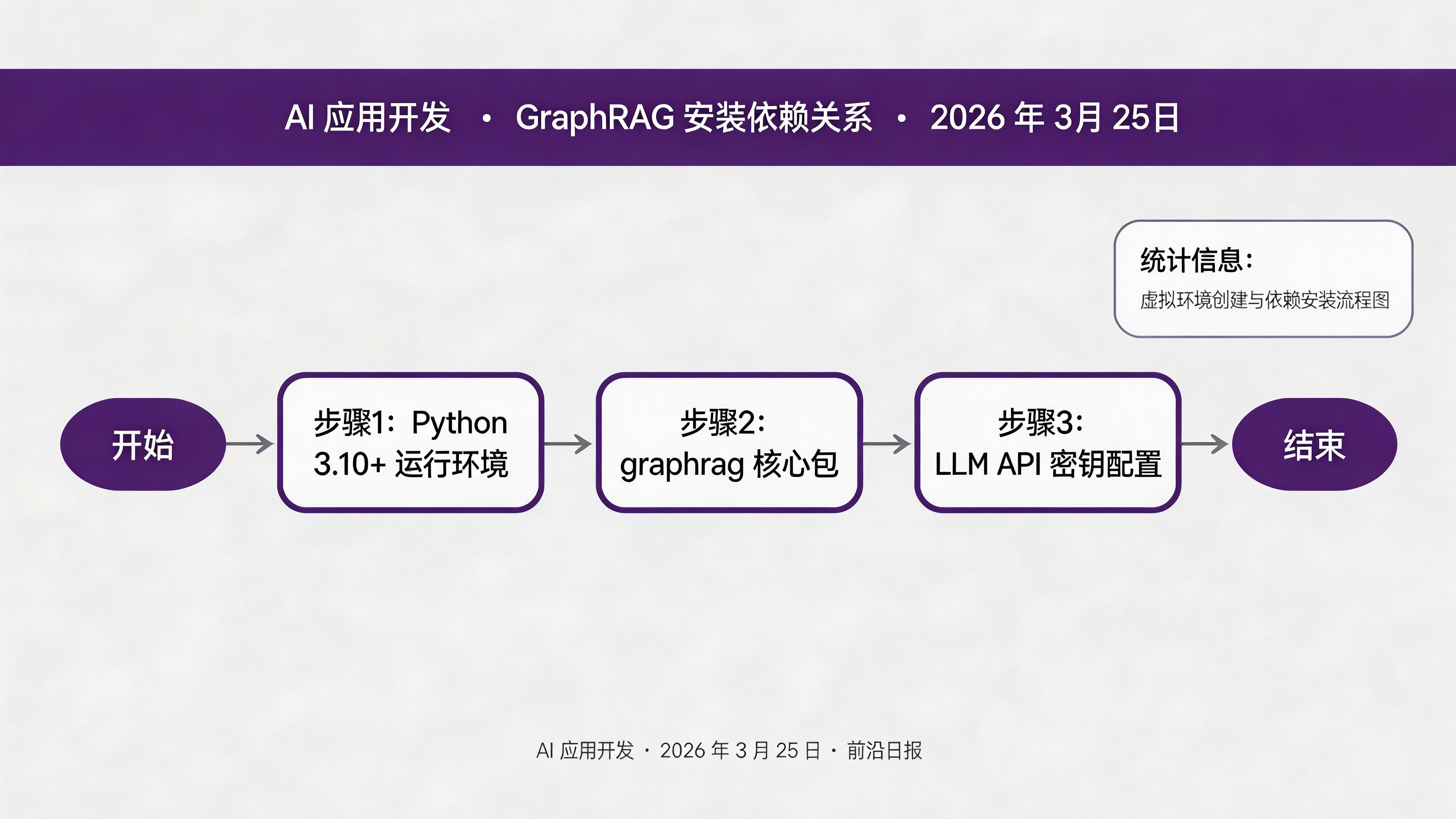
初始化项目结构
mkdir -p graphrag-demo/data
cd graphrag-demo
python -c "from graphrag.pipeline import Pipeline; Pipeline().init(root='./data', force=True)"初始化后,项目结构如下:
graphrag-demo/
├── data/
│ ├── input/ # 原始文档
│ ├── output/ # 索引输出
│ └── settings.yaml # 配置文件
└── .venv/步骤 2:配置 LLM 与索引参数
编辑 data/settings.yaml,配置 LLM 端点和索引参数:
llm:
api_key: ${GRAPHRAG_LLM_API_KEY}
type: openai_chat
model: claude-sonnet-4-5-20250929
api_base: https://api.anthropic.com
embedding:
api_key: ${GRAPHRAG_EMBED_API_KEY}
type: openai_embedding
model: text-embedding-3-large
index:
entity_extraction:
prompt: "prompts/entity_extraction.txt"
max_gleanings: 1 # 对长文档进行多次提取
community_reports:
prompt: "prompts/community_report.txt"
max_length: 2000
embeddings:
vector_store:
type: lancedb # 或 chroma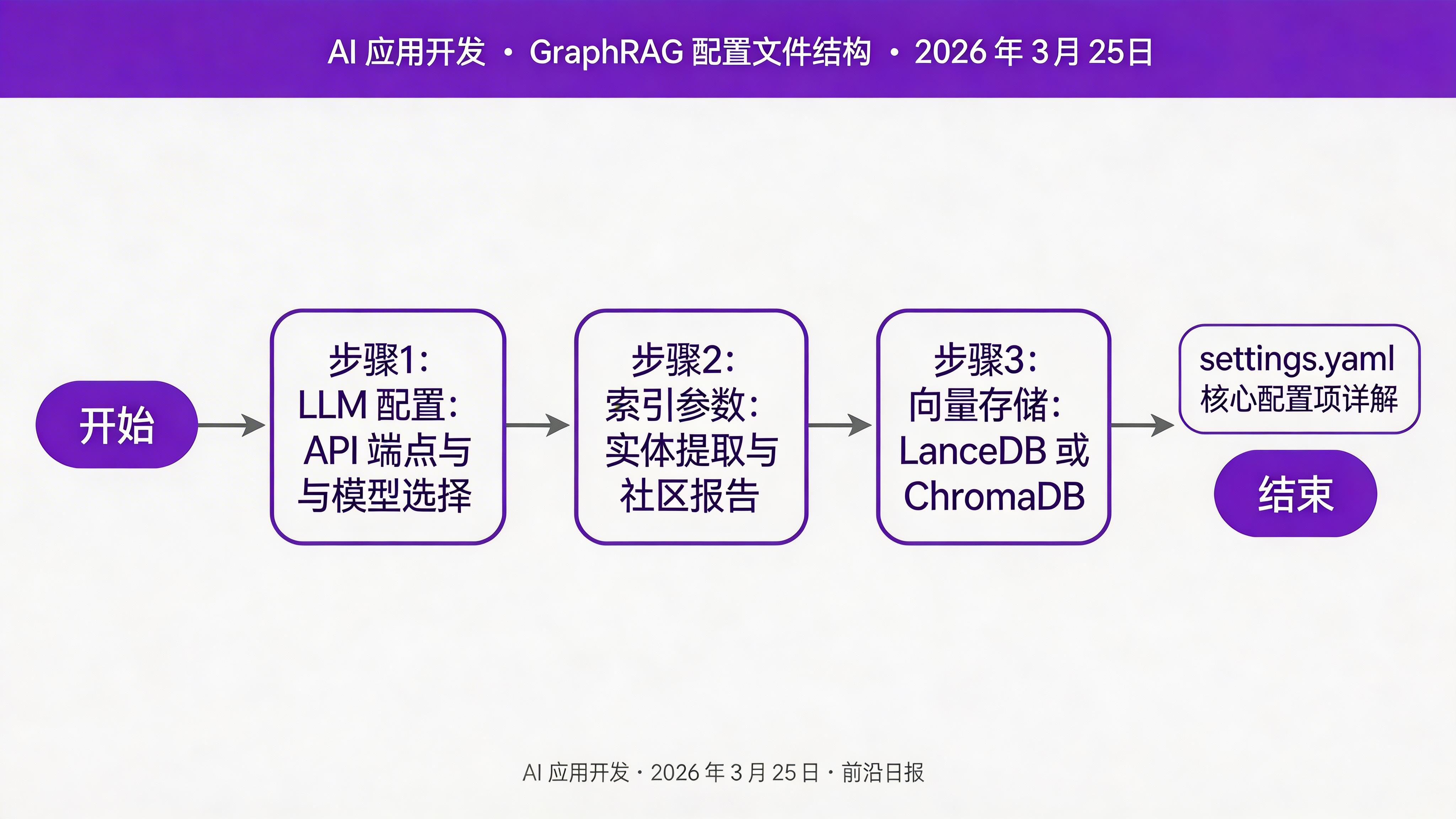
max_gleanings: 0 以减少延迟。
步骤 3:加载文档并构建知识图谱
准备输入文档
将你的企业文档(支持 .txt、.md、.pdf)放入 data/input/ 目录:
cp /path/to/your/docs/*.md data/input/
ls data/input/
# 输出:product_docs.md customer_cases.md technical_specs.md运行索引管道
from graphrag.pipeline import Pipeline
pipeline = Pipeline(root="./data")
pipeline.load_documents()
pipeline.build_index()
print("索引完成!图谱统计:")
print(f" 实体数量:{pipeline.stats.entity_count}")
print(f" 关系数量:{pipeline.stats.relationship_count}")
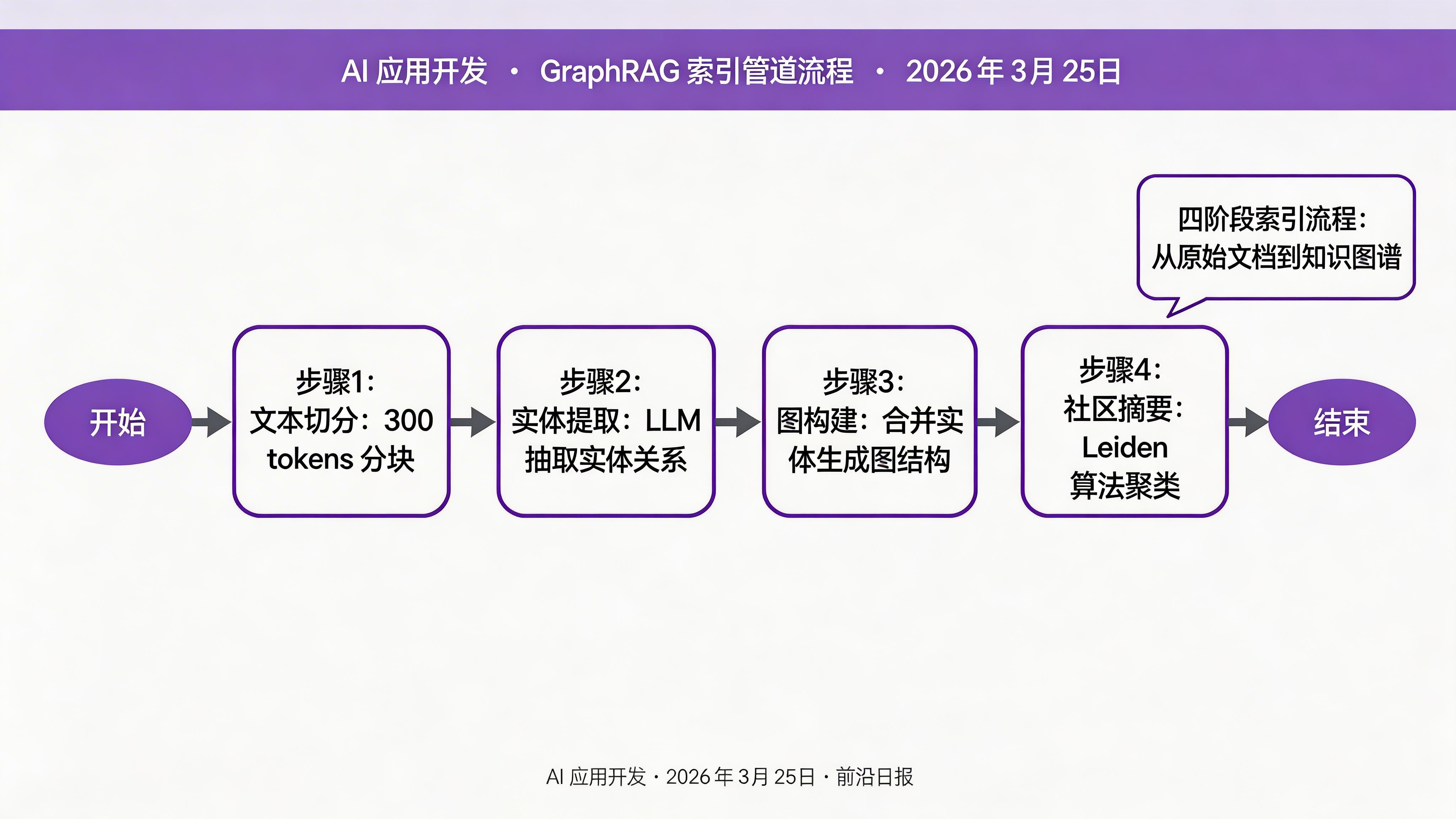
print(f" 社区数量:{pipeline.stats.community_count}")索引过程分为四个阶段:
- 文本切分:将文档分块(默认每块 300 tokens)
- 实体提取:LLM 从每块中提取实体和关系
- 图构建:合并重复实体,构建图结构
- 社区摘要:Leiden 算法聚类 + LLM 生成层级报告
步骤 4:执行多跳查询与全局检索
GraphRAG 支持两种查询模式:
局部查询(Local Search)- 实体中心检索
适用于查询特定实体相关的信息:
response = pipeline.query(
"哪些客户受到了服务 X 停机事件的影响?",
search_type="local",
max_tokens=4000
)
print(response)局部查询会:
- 识别查询中的实体(如"服务 X")
- 检索该实体的邻居节点(1-2 跳)
- 聚合相关文档片段和关系路径
全局查询(Global Search)- 主题级检索
适用于跨文档的全局主题问题:
response = pipeline.query(
"总结过去季度所有与 AI 相关的战略决策",
search_type="global",
max_tokens=8000
)
print(response)全局查询会:
- 检索所有相关的社区摘要
- 并行调用 LLM 生成多个中间答案
- 使用 Map-Reduce 策略聚合最终答案

步骤 5:优化查询性能与准确性
生产环境中,你需要针对延迟和成本进行优化:
# settings.yaml 优化配置
query:
local:
top_k: 10 # 减少检索的实体数量
max_tokens: 4000 # 限制上下文长度
global:
allow_community: true
reduce_tokens: 2000 # 限制聚合时的 token 数
index:
entity_extraction:
strategy: "graph_intelligent" # 使用更高效的提取策略
embeddings:
batch_size: 32 # 批量嵌入以减少 API 调用
常见问题 FAQ
索引阶段慢 3-5 倍(因为需要提取实体和生成社区报告),但查询阶段差异不大。对于需要复杂推理和跨文档关联的场景,准确性提升显著,值得投入。
GraphRAG 本身不限制语言,但实体提取的效果依赖 LLM 的多语言能力。建议使用支持中文的模型(如 Claude、GPT-4),或在提取 prompt 中明确指定输出语言。
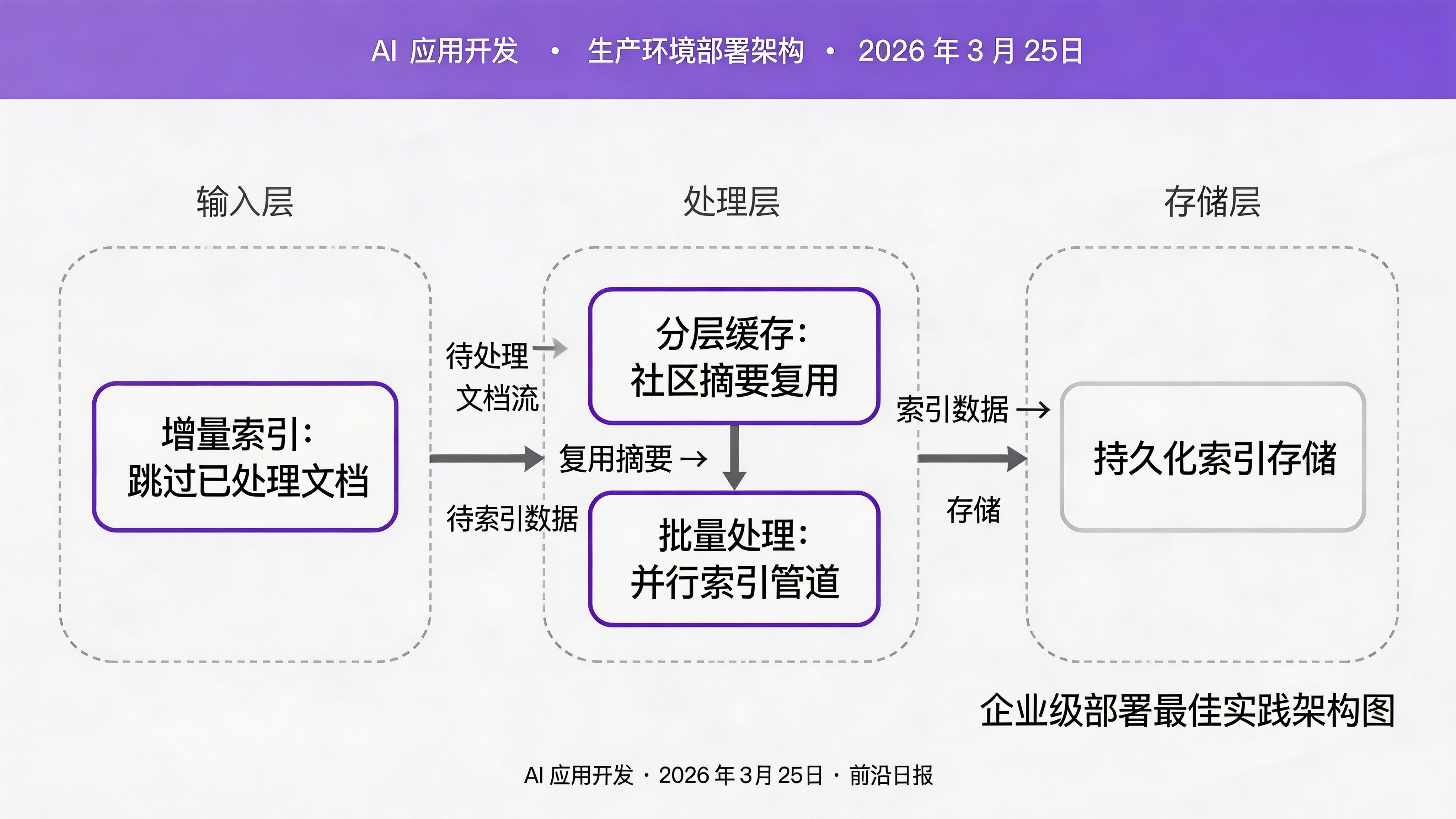
目前官方支持增量索引:设置 incremental_index: true,GraphRAG 会跳过已处理的文档。对于频繁更新的场景,建议按文档类别分批次构建索引。
总结:Graph RAG 的核心价值
- ✓ 知识图谱结构让 RAG 系统具备跨文档关联和多跳推理能力
- ✓ 社区发现算法自动识别主题簇,支持全局主题检索
- ✓ 局部 + 全局双层查询策略,覆盖从实体到主题的全粒度需求
- ✓ 2026 年企业级知识库的标配架构,尤其适合技术文档、客服案例、合规文档等场景