为什么 RAG 系统需要量化评估
在生产环境中部署 RAG 系统后,你是否遇到过这些问题:
- 用户反馈"答案看起来不对",但无法定位是检索问题还是生成问题
- 优化了向量模型,但整体效果反而下降
- A/B 测试时,无法用数据说服团队哪个方案更好
- 每次迭代都像"黑盒调试",靠猜而不是靠数据
这些问题的根源在于缺乏量化评估体系。RAGAS(Retrieval Augmented Generation Assessment)框架应运而生,它提供 6 个核心指标,用 LLM 评估 LLM,让你能够:
- 精准定位瓶颈:区分是检索质量差还是生成能力不足
- 数据驱动优化:每次改动都有明确的分数对比
- 自动化测试:将评估集成到 CI/CD 流水线
- 对标生产指标:将离线评估与在线 A/B 测试结果关联
💡 2026 年最新实践:领先团队将 RAGAS 评估得分与业务指标(转化率、用户留存)建立回归模型,实现技术指标到商业价值的直接映射。
RAGAS 六大核心指标详解
RAGAS 将 RAG 流程拆解为检索(Retrieval)和生成(Generation)两个阶段,每个阶段有 3 个独立指标:

环境准备与依赖安装
开始之前,确保你的开发环境满足以下要求:
⚠️ 注意:RAGAS 本身不依赖特定向量数据库,支持 Chroma、Pinecone、Qdrant、Weaviate 等主流方案。
安装 RAGAS 及依赖
创建虚拟环境并安装核心依赖:
# 创建虚拟环境
python -m venv ragas-env
source ragas-env/bin/activate # Windows: ragas-env\Scripts\activate
# 安装 RAGAS(2026 年最新版)
pip install ragas
# 安装可选依赖(根据使用的向量数据库选择)
pip install chromadb # ChromaDB
pip install pinecone-client # Pinecone
pip install qdrant-client # Qdrant
# 安装 LLM 客户端
pip install openai langchain-openai验证安装:
import ragas
print(f"RAGAS version: {ragas.__version__}")
# 输出:RAGAS version: 0.4.x准备评估数据集
RAGAS 需要以下格式的评估数据:
from datasets import Dataset
# 标准评估数据集格式
eval_data = {
"question": [
"如何配置 ChromaDB 的持久化存储?",
"LangChain 的 Memory 模块有哪些类型?",
# ... 至少 10-20 个问题
],
"answer": [
"ChromaDB 支持三种持久化模式:memory(默认)、sqlite 和 parquet...",
"LangChain 提供 BufferMemory、SummaryMemory、VectorStoreMemory 等...",
],
"contexts": [
["ChromaDB 文档:持久化配置说明...", "StackOverflow: Chroma persistence..."],
["LangChain 官方文档:Memory 模块...", "GitHub: langchain memory examples"],
],
"ground_truth": [
"ChromaDB 支持在启动时指定 persist_directory 参数实现数据持久化",
"包括 ConversationBufferMemory、ConversationSummaryMemory、VectorStoreRetrieverMemory",
]
}
# 转换为 HuggingFace Dataset 格式
dataset = Dataset.from_dict(eval_data)⚠️ 关键:ground_truth 需要人工标注,这是评估的"金标准"。建议至少准备 10-20 个高质量样本,覆盖常见查询类型。
配置 LLM 和嵌入模型
RAGAS 使用 LLM 作为"评判者",需要配置评估模型:
from ragas import evaluate
from ragas.llms import llm_factory
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
import os
# 配置 API Key
os.environ["OPENAI_API_KEY"] = "your-api-key"
# 配置评估用 LLM(推荐使用较强模型)
eval_llm = ChatOpenAI(model="gpt-4o", temperature=0)
# 配置嵌入模型(用于某些指标计算)
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 创建 RAGAS 配置
ragas_config = {
"llm": eval_llm,
"embeddings": embeddings
}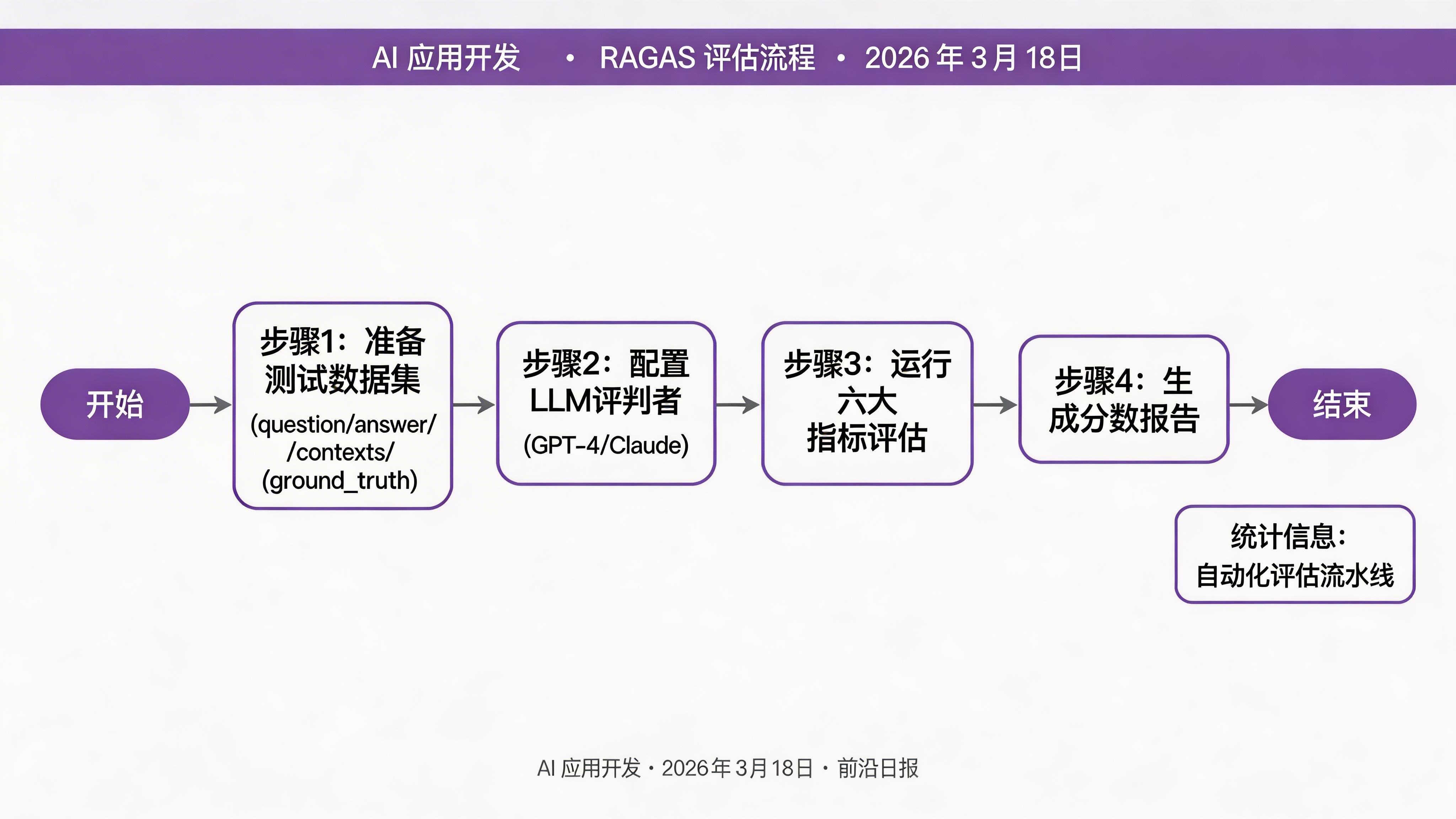
运行完整评估
使用默认指标集运行评估:
from ragas import evaluate
from ragas.metrics import (
context_precision,
context_recall,
faithfulness,
answer_relevance,
context_entities_recall,
noise_sensitivity
)
# 运行评估
results = evaluate(
dataset=dataset,
llm=eval_llm,
embeddings=embeddings,
metrics=[
context_precision,
context_recall,
faithfulness,
answer_relevance,
context_entities_recall,
noise_sensitivity
]
)
# 查看结果
print(results)
print(f"Context Precision: {results['context_precision']:.3f}")
print(f"Context Recall: {results['context_recall']:.3f}")
print(f"Faithfulness: {results['faithfulness']:.3f}")
print(f"Answer Relevance: {results['answer_relevance']:.3f}")输出示例:
┌─────────────────────────┬─────────┐
│ metric │ score │
├─────────────────────────┼─────────┤
│ context_precision │ 0.742 │
│ context_recall │ 0.685 │
│ faithfulness │ 0.823 │
│ answer_relevance │ 0.891 │
│ context_entities_recall │ 0.612 │
│ noise_sensitivity │ 0.756 │
└─────────────────────────┴─────────┘解读评估结果
每个指标的分数范围和含义:
- Context Precision (0.742):74.2% 的相关文档排在前面。低于 0.7 说明检索排序有问题,需优化重排序(Rerank)策略。
- Context Recall (0.685):68.5% 的相关文档被检索到。低于 0.7 说明检索覆盖面不足,需扩大 top_k 或优化查询改写。
- Faithfulness (0.823):82.3% 的答案内容源自检索。低于 0.7 说明模型在"幻觉",需加强 prompt 约束。
- Answer Relevance (0.891):89.1% 的答案直接回答问题。低于 0.8 说明生成模型偏离主题。

💡 经验法则:生产环境建议 Context Precision ≥ 0.75、Faithfulness ≥ 0.80、Answer Relevance ≥ 0.85。
针对性优化:提升检索精确率
如果 Context Precision 低于 0.7,添加重排序步骤:
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
# 使用 LLM 进行智能重排序
compressor = LLMChainExtractor.from_llm(eval_llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=original_retriever
)
# 重新评估
new_dataset = generate_new_dataset(retriever=compression_retriever)
new_results = evaluate(dataset=new_dataset, ...)预期提升:+15%~25% 的 Context Precision。
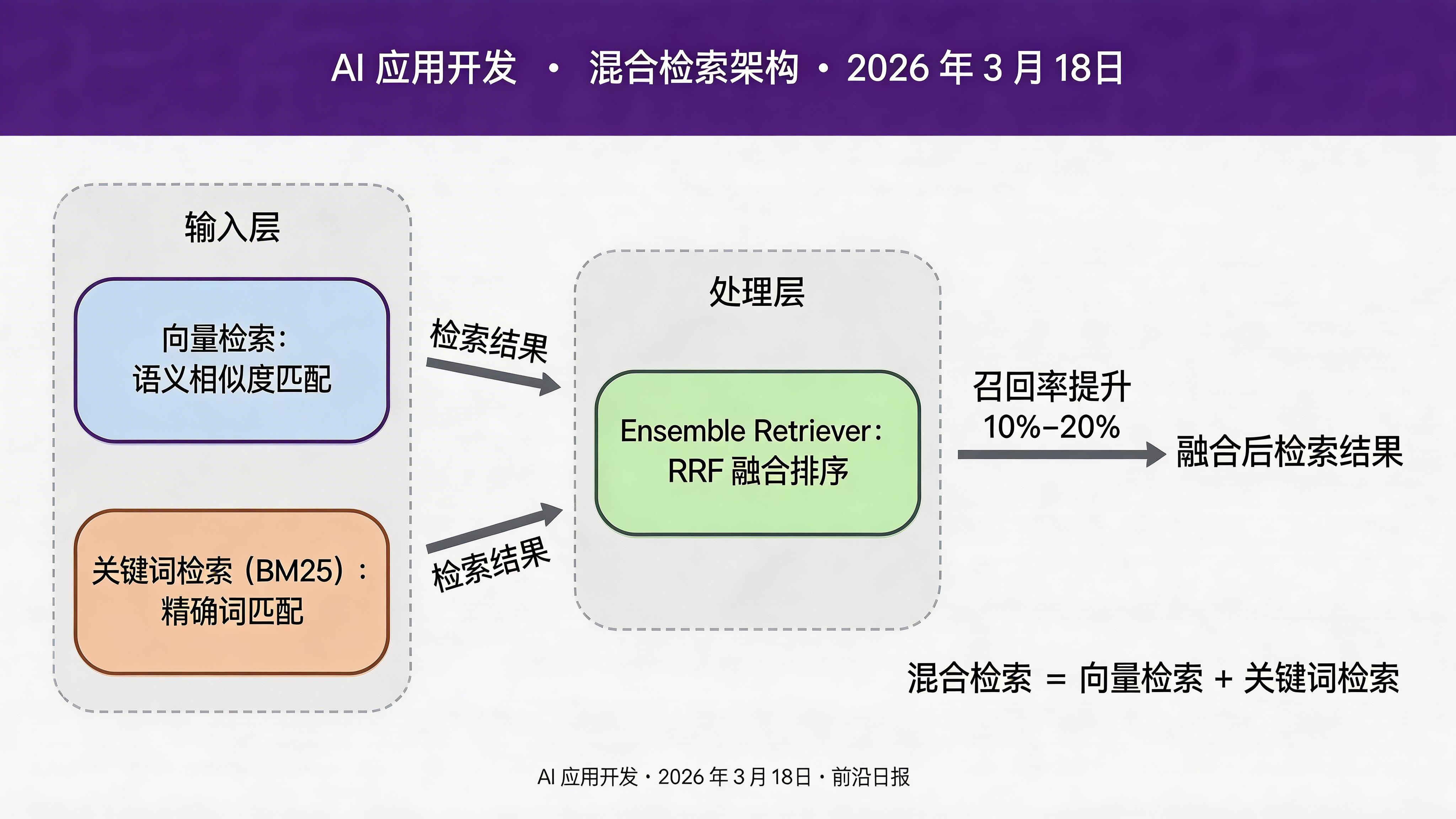
针对性优化:提升检索召回率
如果 Context Recall 低于 0.7,使用混合检索策略:
from langchain.retrievers import EnsembleRetriever
from langchain_community.retrievers import BM25Retriever
# 向量检索 + 关键词检索
vector_retriever = ChromaRetriever(chroma_db, k=10)
keyword_retriever = BM25Retriever.from_documents(docs, k=10)
# 集成检索(Reciprocal Rank Fusion)
ensemble_retriever = EnsembleRetriever(
retrievers=[vector_retriever, keyword_retriever],
weights=[0.6, 0.4]
)
# 重新评估
new_dataset = generate_new_dataset(retriever=ensemble_retriever)
new_results = evaluate(dataset=new_dataset, ...)预期提升:+10%~20% 的 Context Recall。
针对性优化:提升生成忠实度
如果 Faithfulness 低于 0.7,强化 Prompt 约束:
RAG_PROMPT = """你是一个基于检索内容回答问题的助手。
重要规则:
1. 只能使用【检索内容】中提供的信息
2. 如果检索内容不足以回答问题,明确说"根据提供的资料无法回答"
3. 不要添加任何检索内容之外的知识
4. 每个关键陈述后标注引用来源
【检索内容】
{context}
【问题】
{question}
【答案】
"""
from langchain.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template(RAG_PROMPT)预期提升:+10%~15% 的 Faithfulness。
进阶技巧:构建自动化评估流水线
将 RAGAS 集成到 CI/CD 流水线,每次代码提交自动运行评估:
# evaluation_pipeline.py
import json
from datetime import datetime
def run_evaluation(retriever, llm, test_dataset):
"""运行评估并记录历史"""
results = evaluate(
dataset=test_dataset,
llm=llm,
metrics=[context_precision, context_recall, faithfulness]
)
# 记录历史
history_entry = {
"timestamp": datetime.now().isoformat(),
"commit": get_current_commit(),
"scores": {
"context_precision": float(results["context_precision"]),
"context_recall": float(results["context_recall"]),
"faithfulness": float(results["faithfulness"])
}
}
# 保存历史
with open("eval_history.jsonl", "a") as f:
f.write(json.dumps(history_entry) + "\n")
# 检查回归
if has_regression(history_entry):
raise Exception("评估分数下降,阻止部署!")
return results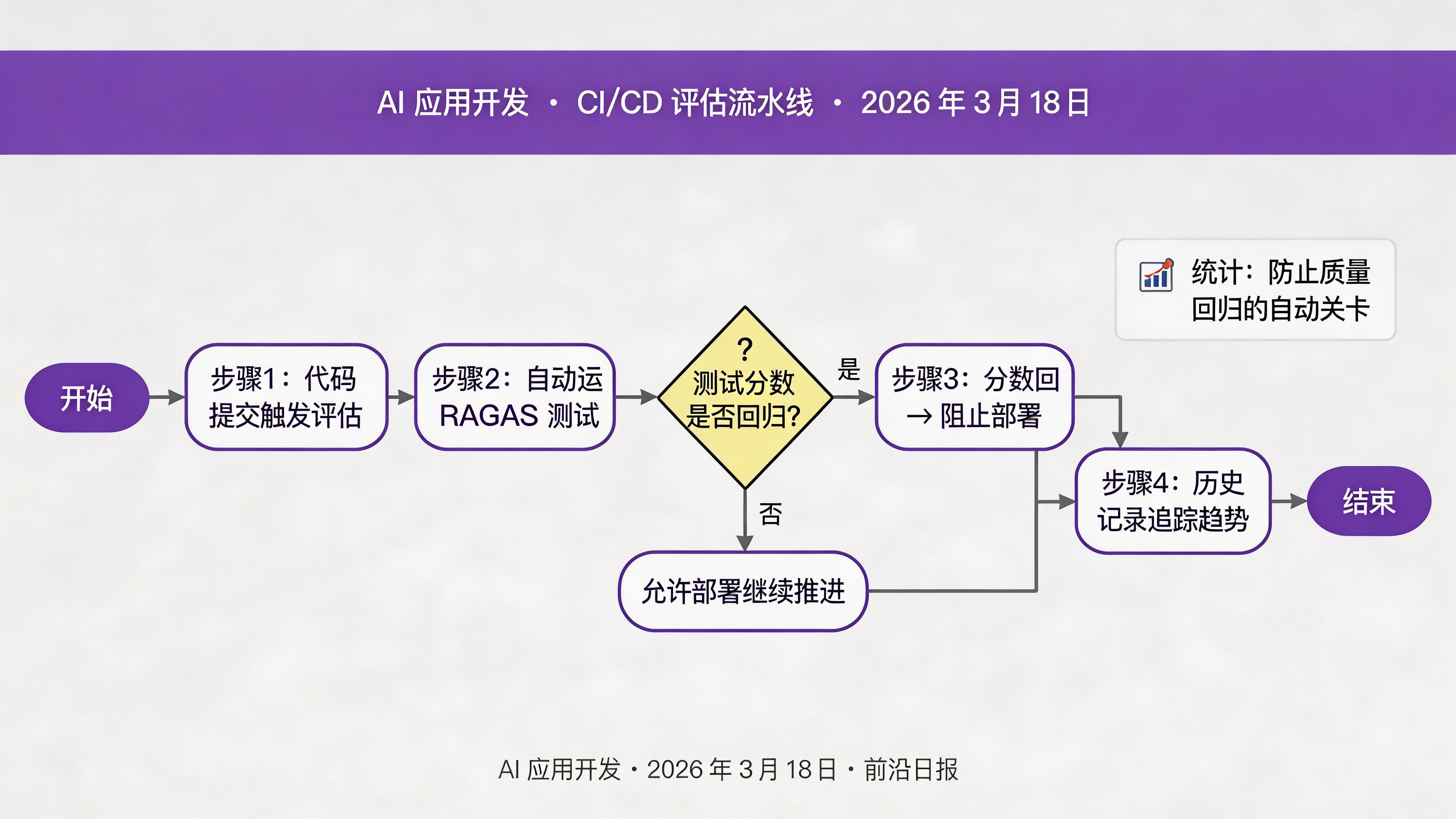
常见问题 FAQ
关键要点总结
- RAGAS 提供 6 个核心指标:Context Precision、Context Recall、Context Entities Recall、Faithfulness、Answer Relevance、Noise Sensitivity
- 评估数据集需要人工标注 ground_truth,建议 20-50 个高质量样本
- 生产环境基准:Context Precision ≥ 0.75、Faithfulness ≥ 0.80、Answer Relevance ≥ 0.85
- 检索优化:重排序提升 Precision、混合检索提升 Recall
- 生成优化:强化 Prompt 约束提升 Faithfulness
- 将 RAGAS 集成到 CI/CD 流水线,防止评估分数回归