你是否遇到过这样的场景:用 CrewAI 或 AutoGen 搭建的多 Agent 系统,在简单任务上运行良好,但一旦遇到需要循环迭代、条件分支或状态恢复的复杂工作流,就开始出现信息丢失、逻辑混乱、难以调试的问题?
传统 Agent 框架采用隐式状态传递 —— 信息通过 LLM 上下文"隐式"流转,你看不到它、无法保证它、更无法追踪它。当系统出错时,你面对的是黑盒般的执行日志,无从下手。
本教程将带你掌握 LangGraph —— 一种基于状态机和图结构的 Agent 编排框架,通过显式定义状态(State)、节点(Node)和边(Edge),实现:
- ✅ 确定性执行路径,可预测、可复现
- ✅ 循环和条件分支,支持动态决策
- ✅ 状态持久化与检查点,支持故障恢复
- ✅ 可视化调试,每步状态清晰可查
准备工作:环境与依赖
Python 3.10+
推荐 3.10 或更高版本
LangGraph
核心图编排框架
LangChain
LLM 抽象与工具集成
OpenAI SDK
或其他 LLM 提供商
# 创建虚拟环境
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
# 安装依赖
pip install langgraph langchain langchain-openai核心概念:状态机思维
LangGraph 的核心思想源自有限状态机(Finite State Machine, FSM)。将 Agent 工作流建模为图:
- 状态(State):共享且强类型的内存结构,贯穿整个图,保存上下文、决策和中间结果
- 节点(Node):执行单元,负责调用 LLM、工具、数据转换等单一职责操作
- 边(Edge):定义节点间的控制流,支持顺序、条件和循环跳转,显式控制执行路径
💡 关键洞察:与传统 Agent 框架不同,LangGraph 中的状态是显式定义、强类型、全局共享的。每个节点读取状态并返回状态更新,而非隐式传递消息。
实战:构建自修正 Agent 系统
我们将构建一个具有反思能力的 Agent:它能生成答案、自我评估、并在质量不达标时自动迭代优化。
1
定义状态结构
使用 Python 的 TypedDict 定义强类型状态:
from typing import TypedDict, Literal
class AgentState(TypedDict):
"""Agent 执行状态"""
request: str # 用户请求
draft: str # 生成的草稿
critique: str # 评估意见
should_refine: bool # 是否需要优化
final_output: str # 最终输出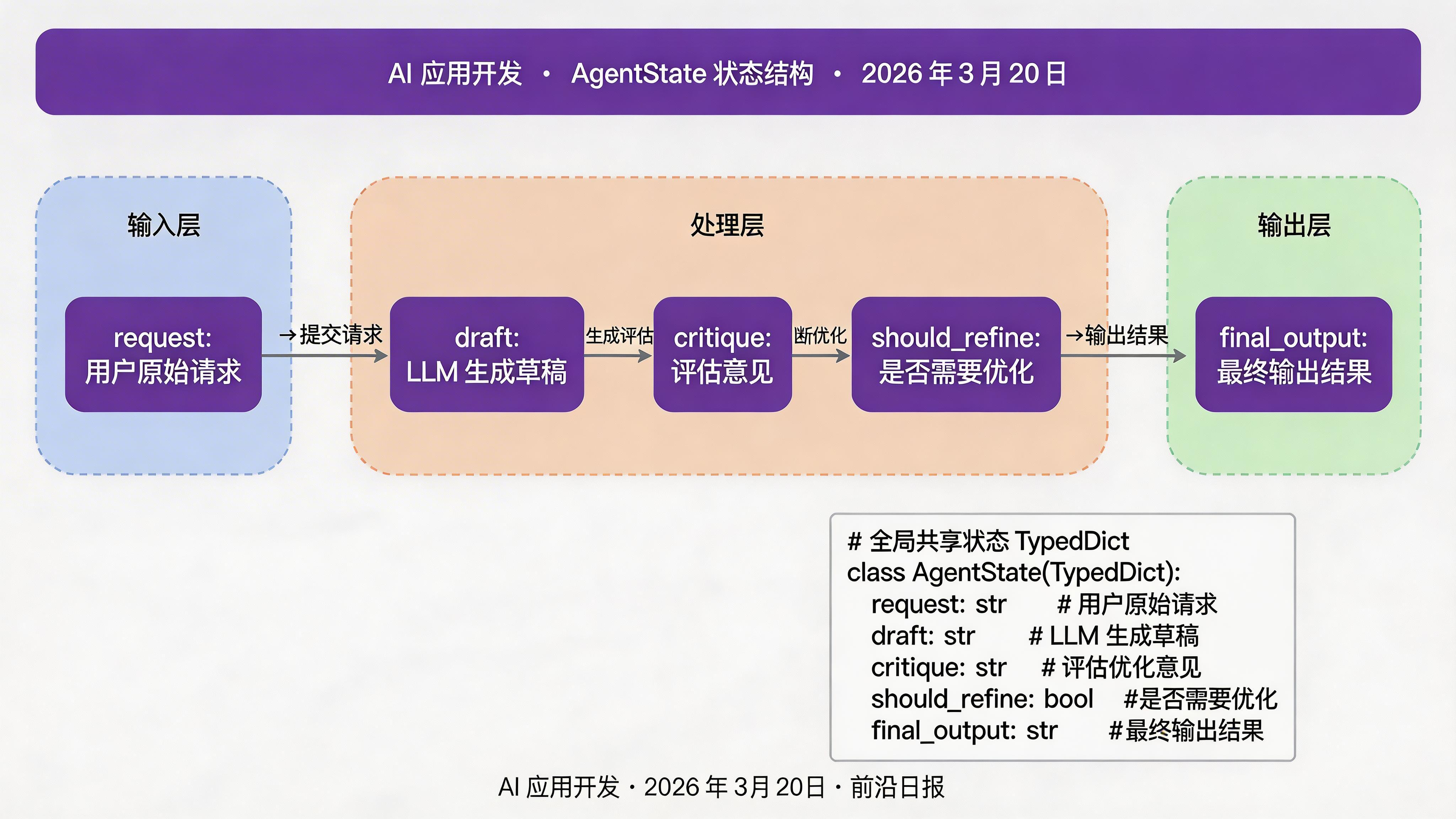
2
实现生成节点
生成节点负责根据用户请求创建初始草稿:
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.7)
def generate_node(state: AgentState) -> AgentState:
"""生成初始草稿"""
prompt = f"请针对以下请求生成详细回答:\n\n{state['request']}"
response = llm.invoke([HumanMessage(content=prompt)])
return {"draft": response.content, "should_refine": True}3
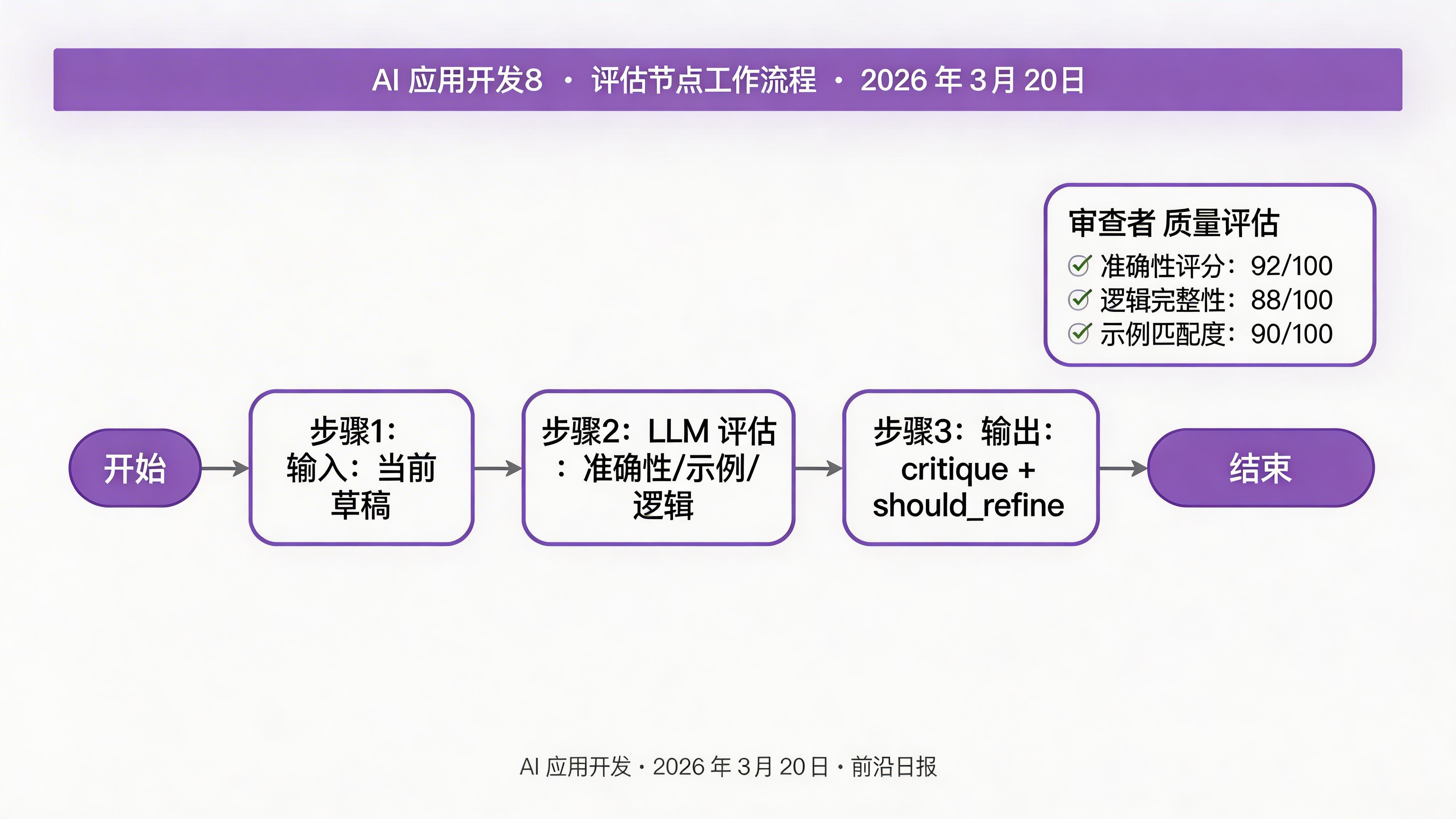
实现评估节点
评估节点扮演"审查者"角色,检查草稿质量:
def critique_node(state: AgentState) -> AgentState:
"""评估草稿质量并给出改进建议"""
prompt = f"""请评估以下回答的质量:
请求:{state['request']}
回答:{state['draft']}
评估标准:
1. 是否准确回答了问题?
2. 是否包含具体示例或代码?
3. 逻辑是否清晰、结构是否完整?
如果回答质量优秀(满足以上所有标准),请输出"PASSED"。
否则,请指出需要改进的具体问题。"""
response = llm.invoke([HumanMessage(content=prompt)])
critique = response.content
return {
"critique": critique,
"should_refine": "PASSED" not in critique
}
4
实现优化节点
当评估未通过时,优化节点根据反馈意见改进草稿:
def refine_node(state: AgentState) -> AgentState:
"""根据评估意见优化草稿"""
prompt = f"""请根据以下评估意见改进回答:
原始请求:{state['request']}
原始回答:{state['draft']}
评估意见:{state['critique']}
请针对评估中指出的问题进行改进,生成更高质量的回答。"""
response = llm.invoke([HumanMessage(content=prompt)])
return {"draft": response.content, "final_output": response.content}5
定义条件边(路由)
路由函数决定下一步执行哪个节点,实现条件分支:
def router(state: AgentState) -> Literal["refine", "finalize"]:
"""根据评估结果决定下一步"""
if state["should_refine"]:
return "refine"
return "finalize"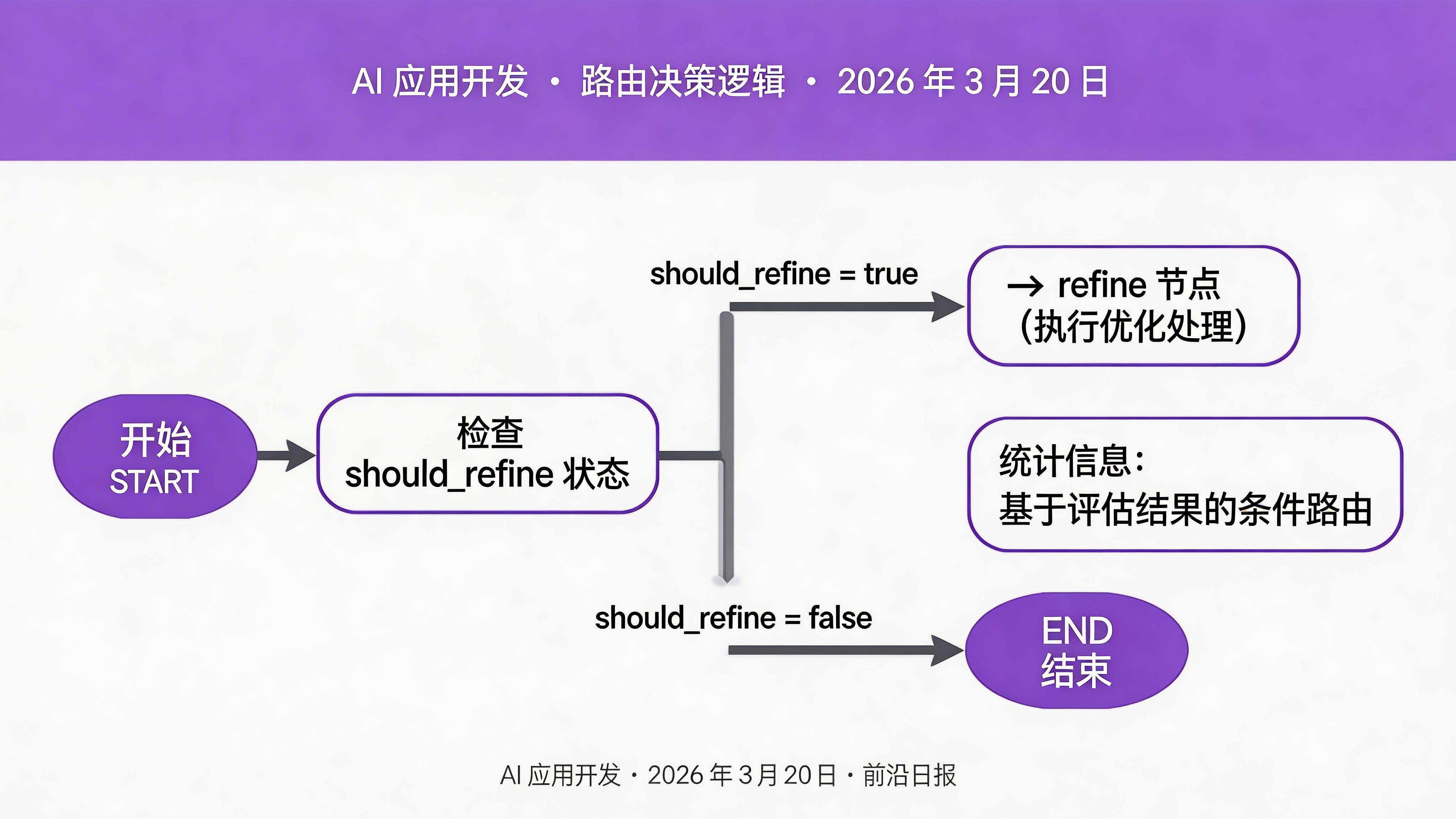
6
构建并编译图
将所有组件组装成完整的图结构:
from langgraph.graph import StateGraph, END
# 创建图
graph = StateGraph(AgentState)
# 添加节点
graph.add_node("generate", generate_node)
graph.add_node("critique", critique_node)
graph.add_node("refine", refine_node)
# 设置入口
graph.set_entry_point("generate")
# 添加边
graph.add_edge("generate", "critique")
graph.add_conditional_edges(
"critique",
router,
{
"refine": "refine",
"finalize": END
}
)
graph.add_edge("refine", "critique") # 优化后重新评估
# 编译
app = graph.compile()![LangGraph 完整图结构:generate → critique → [refine 循环] → END](/img/2026-03-20/tut-ai-dev-tut-20260320-0957/section-04.jpg)
7
执行与调试
运行 Agent 并观察每步状态变化:
# 执行并流式输出每步状态
for step in app.stream({
"request": "解释 Python 中的装饰器原理",
"draft": "",
"critique": "",
"should_refine": False,
"final_output": ""
}):
print(step)
print("---")
# 获取最终结果
result = app.invoke({...})
print(result["final_output"])
8
添加状态持久化(可选)
使用检查点实现状态持久化,支持故障恢复和审计:
from langgraph.checkpoint.memory import MemorySaver
# 创建内存检查点
checkpointer = MemorySaver()
# 编译时传入
app = graph.compile(checkpointer=checkpointer)
# 使用线程 ID 隔离会话
config = {"configurable": {"thread_id": "session-001"}}
# 执行(状态自动保存)
result = app.invoke({...}, config=config)
# 恢复历史状态
history = app.get_state_history(config)
for state in history:
print(state.values)⚠️ 注意:检查点仅保存在节点之间。如果单个节点内部有长时间循环,需要在节点内部手动实现分段保存。
常见问题(FAQ)
LangGraph 与 CrewAI、AutoGen 的核心区别是什么?
CrewAI/AutoGen 采用隐式状态传递(通过 LLM 上下文),适合快速原型但难以控制复杂流程。LangGraph 显式定义状态和边,提供确定性执行、循环支持和可视化调试,适合生产环境。
如何避免无限循环?
在状态中添加计数器字段(如
iteration_count),在路由函数中检查是否超过最大迭代次数。示例:if state["iteration_count"] >= 3: return "finalize"状态结构过于复杂怎么办?
保持状态简洁,只保存跨节点共享的数据。节点内部的临时变量不要放入状态。可以使用嵌套 TypedDict 组织复杂结构。
如何集成自定义工具?
在节点函数中直接调用工具函数,或使用 LangChain 的
@tool装饰器定义工具后在节点中调用。工具返回结果后更新状态即可。总结
- 使用TypedDict定义强类型状态,确保数据结构清晰
- 节点职责单一化,每个节点只做一件事
- 通过条件边实现动态决策和循环逻辑
- 利用流式执行调试每步状态变化
- 生产环境启用检查点实现状态持久化
- 设置迭代上限防止无限循环