痛点:企业知识库的"多模态鸿沟"
想象这个场景:产品团队想查找去年某次评审会上的设计图,销售需要定位合同扫描件中的特定条款,客服想检索培训视频里的问题处理片段——但传统关键词搜索对这些非结构化多模态数据束手无策。
根据 2026 年 McKinsey 调研,71% 的企业已在至少一个业务功能中采用生成式 AI,但只有 23% 实现了多模态数据的统一检索。RAG(检索增强生成)市场预计到 2030 年将达到 110 亿美元,年复合增长率 49.1%,而多模态 RAG正是下一代企业知识基础设施的核心。
本教程将带你使用 LangChain4j(Java 生态的 LangChain)构建一个生产级多模态 RAG 系统,支持:
- 📄 PDF 文档文本提取与向量化
- 🖼️ 图像内容理解与描述生成
- 🔍 文本 + 图像的混合语义检索
- 💬 基于检索结果的自然语言回答
核心架构:多模态 RAG 系统拆解
多模态 RAG 系统由两大核心模块组成:
准备工作:环境搭建与依赖配置
开始之前,确保你的开发环境满足以下要求:
创建 Maven 项目,pom.xml 核心依赖如下:
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>multimodal-rag</artifactId>
<version>1.0.0</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.0</version>
</parent>
<dependencies>
<!-- LangChain4j 核心库 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.35.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-google-ai-gemini</artifactId>
<version>0.35.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pgvector</artifactId>
<version>0.35.0</version>
</dependency>
<!-- PDF 解析与图像处理 -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>3.0.2</version>
</dependency>
<!-- Spring Boot Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
</project>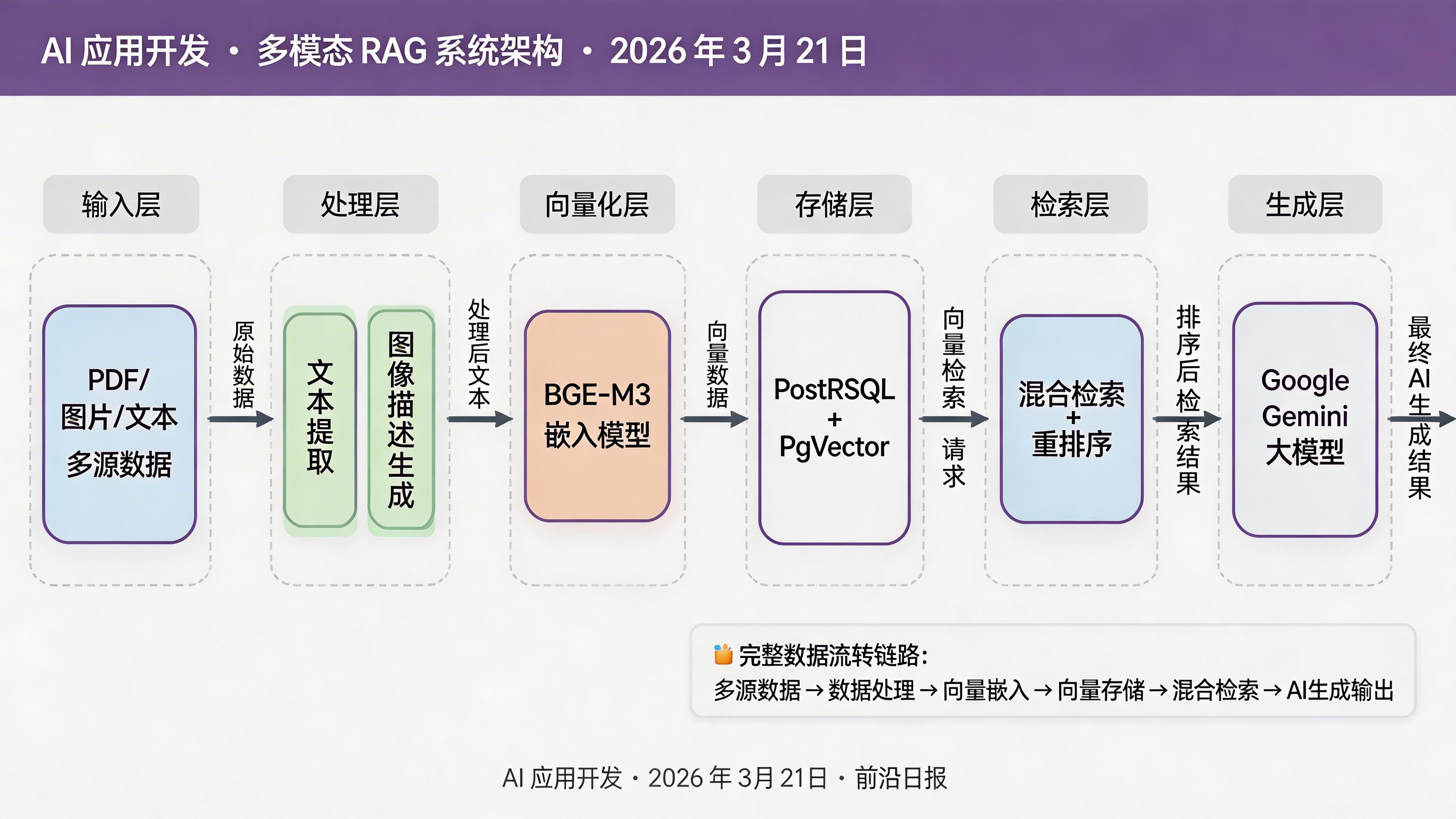
架构图展示了数据从输入到最终回答的完整流转过程,每个模块都可通过 LangChain4j 的组件接口灵活替换。
实战步骤:从零构建多模态 RAG 系统
配置向量数据库
使用 Docker Compose 快速部署 PostgreSQL + PgVector:
# docker-compose.yml
version: '3.8'
services:
postgres:
image: pgvector/pgvector:pg16
container_name: rag-vector-db
environment:
POSTGRES_USER: raguser
POSTGRES_PASSWORD: ragpass123
POSTGRES_DB: ragdb
ports:
- "5432:5432"
volumes:
- pgdata:/var/lib/postgresql/data
volumes:
pgdata:启动服务:
docker-compose up -d初始化 Embedding Store
创建 LangChain4j 的 PgVector 连接配置:
@Configuration
public class VectorStoreConfig {
@Bean
public EmbeddingStore embeddingStore() {
return PgVectorEmbeddingStore.builder()
.host("localhost")
.port(5432)
.database("ragdb")
.user("raguser")
.password("ragpass123")
.table("embeddings")
.dimension(768) // BGE-M3 模型维度
.build();
}
}实现 PDF 解析与文本提取
使用 Apache PDFBox 提取 PDF 内容:
public class PdfProcessor {
public List<TextSegment> processPdf(Path pdfPath) throws IOException {
try (PDDocument document = PDDocument.load(pdfPath.toFile())) {
PDFTextStripper stripper = new PDFTextStripper();
String fullText = stripper.getText(document);
// 按段落分割并进行语义分块
return chunkBySemantics(fullText);
}
}
private List<TextSegment> chunkBySemantics(String text) {
// 使用 LangChain4j 的分块策略
DocumentSplitter splitter = DocumentSplitters.recursive(300, 30);
List<TextSegment> chunks = splitter.split(text);
// 为每个 chunk 添加元数据
return chunks.stream()
.map(segment -> TextSegment.from(segment.text(),
Metadata.from("source", "pdf")))
.collect(Collectors.toList());
}
}实现图像描述生成
使用 Google Gemini Vision 为图像生成描述:
public class ImageProcessor {
private final VisionModel visionModel;
public ImageProcessor(String geminiApiKey) {
this.visionModel = GeminiVisionModel.builder()
.apiKey(geminiApiKey)
.modelName("gemini-2.0-flash")
.build();
}
public String generateImageDescription(Path imagePath) throws IOException {
byte[] imageBytes = Files.readAllBytes(imagePath);
String prompt = """
请用中文详细描述这张图片的内容,包括:
1. 主要物体和场景
2. 颜色、布局等视觉特征
3. 图片可能表达的信息或用途
限制在 200 字以内。
""";
VisionContentRequest request = VisionContentRequest.builder()
.addUserMessage(prompt)
.addImage(imageBytes)
.build();
return visionModel.generate(request);
}
}
构建向量化流水线
将文本和图像描述转换为向量并存入数据库:
@Service
public class IngestionService {
private final EmbeddingModel embeddingModel;
private final EmbeddingStore embeddingStore;
private final PdfProcessor pdfProcessor;
private final ImageProcessor imageProcessor;
// 使用 Hugging Face BGE-M3 模型
public IngestionService() {
this.embeddingModel = new HuggingFaceEmbeddingModel("BAAI/bge-m3");
}
public void ingestDocument(Path docPath) {
List<TextSegment> segments = new ArrayList<>();
// 处理 PDF
if (docPath.toString().endsWith(".pdf")) {
segments.addAll(pdfProcessor.processPdf(docPath));
}
// 处理图片
if (isImage(docPath)) {
String description = imageProcessor.generateImageDescription(docPath);
segments.add(TextSegment.from(description,
Metadata.from("type", "image").add("filename", docPath.getFileName())));
}
// 生成向量并存入
for (TextSegment segment : segments) {
Embedding embedding = embeddingModel.embed(segment);
embeddingStore.add(embedding, segment);
}
}
}实现检索 - 生成流水线
创建 RAG 查询服务:
@Service
public class RagQueryService {
private final EmbeddingStore embeddingStore;
private final ChatLanguageModel chatModel;
private final EmbeddingModel embeddingModel;
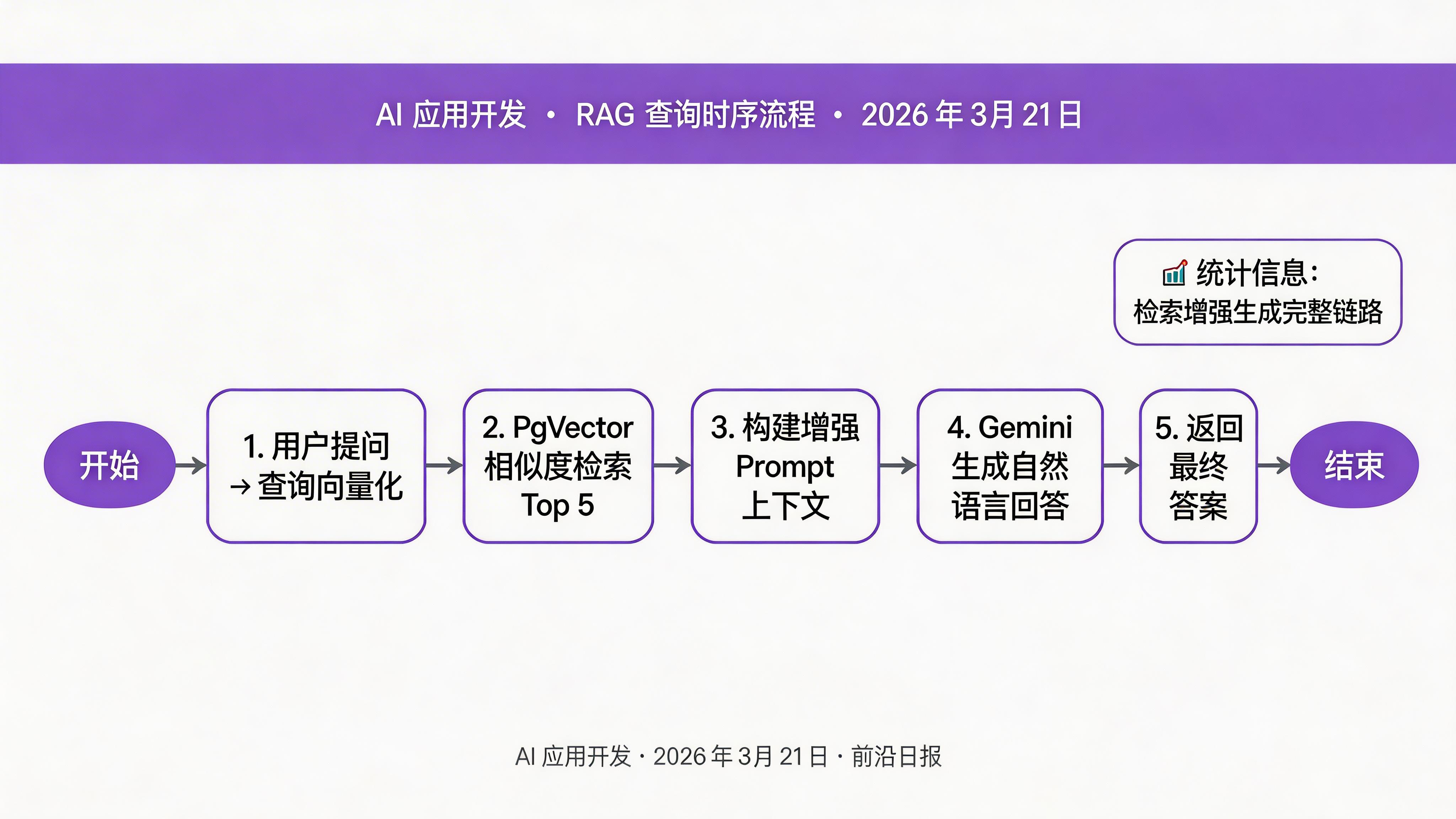
public String query(String question) {
// 1. 将查询向量化
Embedding queryEmbedding = embeddingModel.embed(question);
// 2. 检索最相关的文档片段
List<EmbeddingMatch> matches = embeddingStore.findRelevant(
queryEmbedding,
5 // 返回 top 5 结果
);
// 3. 构建增强 prompt
String context = buildContext(matches);
String augmentedPrompt = buildRagPrompt(question, context);
// 4. 生成回答
return chatModel.generate(augmentedPrompt);
}
private String buildContext(List<EmbeddingMatch> matches) {
return matches.stream()
.map(match -> match.embedded().text())
.collect(Collectors.joining("\n\n---\n\n"));
}
private String buildRagPrompt(String question, String context) {
return """
你是一个企业知识库助手。请基于以下上下文信息回答问题:
【上下文】
%s
【问题】
%s
如果上下文中没有相关信息,请如实告知。
""".formatted(context, question);
}
}提供 RESTful API
基于 Spring Boot 暴露查询接口:
@RestController
@RequestMapping("/api/rag")
public class RagController {
@Autowired
private RagQueryService ragQueryService;
@Autowired
private IngestionService ingestionService;
@PostMapping("/query")
public ResponseEntity<QueryResponse> query(@RequestBody QueryRequest request) {
String answer = ragQueryService.query(request.question());
return ResponseEntity.ok(new QueryResponse(answer));
}
@PostMapping("/ingest")
public ResponseEntity<?> ingest(@RequestParam("file") MultipartFile file)
throws IOException {
Path tempFile = Files.createTempFile("upload", file.getOriginalFilename());
file.transferTo(tempFile);
ingestionService.ingestDocument(tempFile);
Files.delete(tempFile);
return ResponseEntity.ok(Map.of("status", "success"));
}
}
进阶技巧:提升检索质量的最佳实践
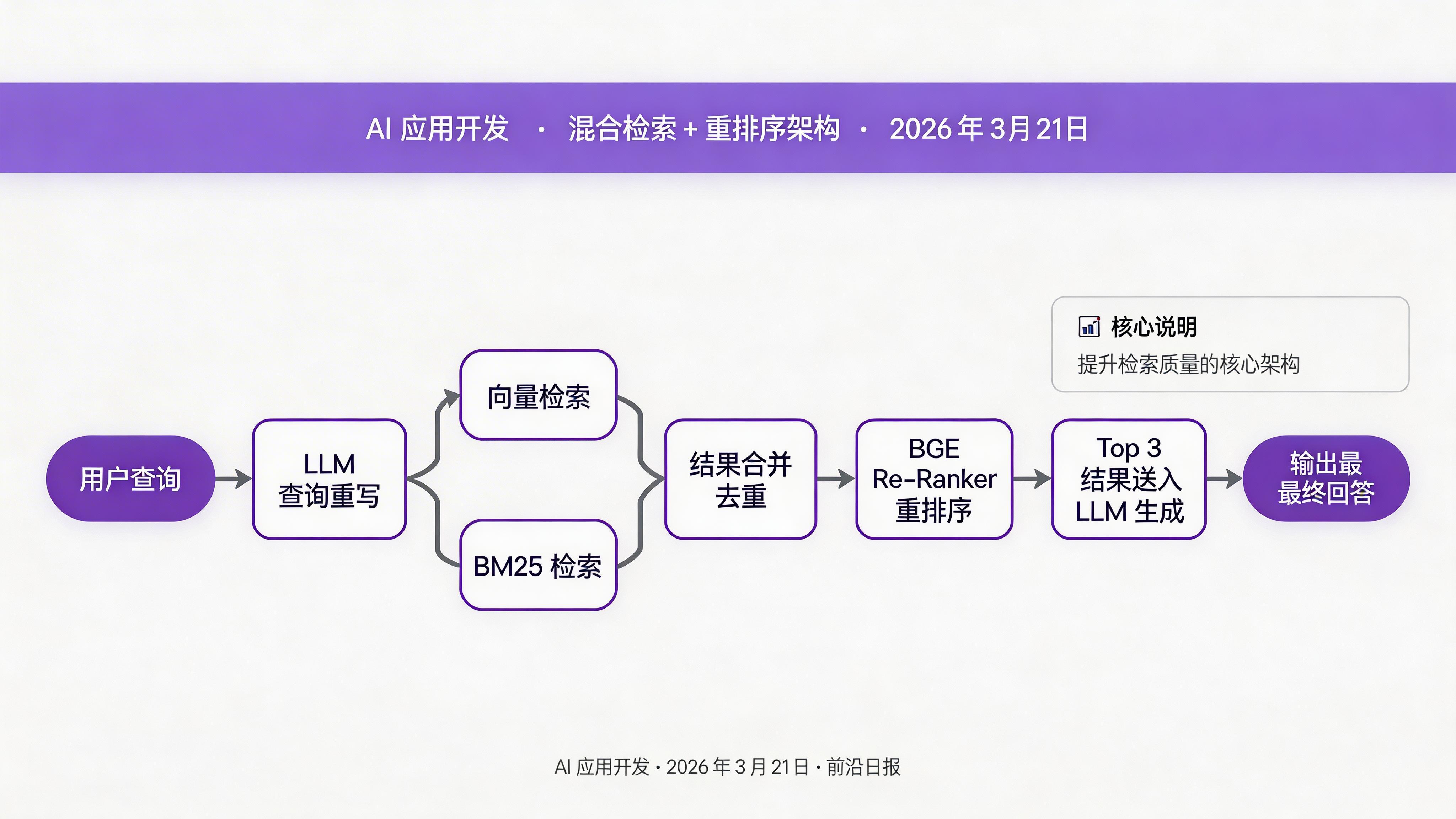
混合检索策略
单一向量检索可能遗漏关键词精确匹配的结果。结合 BM25(关键词)+ 向量(语义)的混合检索能显著提升召回率:
public List<EmbeddingMatch> hybridSearch(String query, int k) {
// 向量检索
Embedding queryEmbedding = embeddingModel.embed(query);
List<EmbeddingMatch> vectorResults = embeddingStore.findRelevant(queryEmbedding, k);
// BM25 关键词检索(使用 PostgreSQL 全文搜索)
List<EmbeddingMatch> bm25Results = bm25Search(query, k);
// 合并并去重,按分数加权排序
return mergeResults(vectorResults, bm25Results, 0.7, 0.3);
}查询重写与扩展
用户查询往往简短模糊,使用 LLM 进行查询重写能提升检索精度:
public String rewriteQuery(String originalQuery) {
return chatModel.generate("""
请将以下用户查询重写为更适合检索的形式:
- 扩展同义词和相关概念
- 明确隐含的时间、实体等信息
- 保持简洁,不超过 50 字
原始查询:%s
重写后:
""".formatted(originalQuery));
}重排序(Re-ranking)
检索后使用 Cross-Encoder 模型对结果重排序,能进一步提升相关性:
// 使用 BGE Re-Ranker 对初步检索结果重排序
public List<EmbeddingMatch> rerank(String query, List<EmbeddingMatch> candidates) {
List<ScoredResult> scored = reranker.score(query, candidates);
return scored.stream()
.sorted(Comparator.comparingDouble(ScoredResult::score).reversed())
.map(ScoredResult::toEmbeddingMatch)
.limit(3) // 只取 top 3 给 LLM,节省 token
.collect(Collectors.toList());
}
常见问题 FAQ
department、security_level),查询时根据用户身份过滤。PgVector 支持在 SQL 层面添加 WHERE 条件实现权限过滤。总结:构建企业级多模态 RAG 的关键要点
- ✓ 多模态 RAG 融合文本、图像、PDF 等多种数据源,突破传统搜索的局限
- ✓ LangChain4j 为 Java 开发者提供与 LangChain 对等的 AI 应用开发能力
- ✓ PgVector 作为开源向量数据库,支持高效相似度检索和权限过滤
- ✓ 混合检索(向量 +BM25)+ 重排序策略显著提升检索质量
- ✓ 生产环境需关注分块策略、缓存机制、评估体系等工程细节
本教程展示了从零构建多模态 RAG 系统的完整流程。实际生产中,还需根据具体业务场景调整模型选型、优化检索策略、建立质量评估体系,让 AI 真正成为企业知识的"智能入口"。