为什么 2026 年的 AI 应用需要全新范式?
在 2024-2025 年,大多数开发者构建 AI 应用的方式是:写好提示词 → 调用 LLM API → 解析响应 → 调用下一个工具。这种线性链式结构在处理简单任务时行之有效,但当面对需要多轮迭代、条件分支、错误恢复的复杂场景时,问题便暴露无遗:
- 控制流不可见:代码中的 if-else 与 LLM 的自由发挥混在一起,调试时难以追踪
- 状态管理混乱:多轮对话历史、中间结果、工具返回值散落在各处,难以保持一致性
- 无法优雅重试:一旦某步失败,要么从头再来,要么人工介入
- 多 Agent 协作失控:多个 Agent 之间缺乏明确的协调机制,容易陷入无意义的循环对话
LangGraph 4.0 的发布标志着 AI 应用开发进入新阶段:它不再把 LLM 当作聊天机器人,而是将其视为确定性执行引擎中的智能节点。本文将通过完整实战,展示如何用 LangGraph 4.0 构建一个支持状态持久化、多 Agent 协作、人类审核介入的生产级系统。
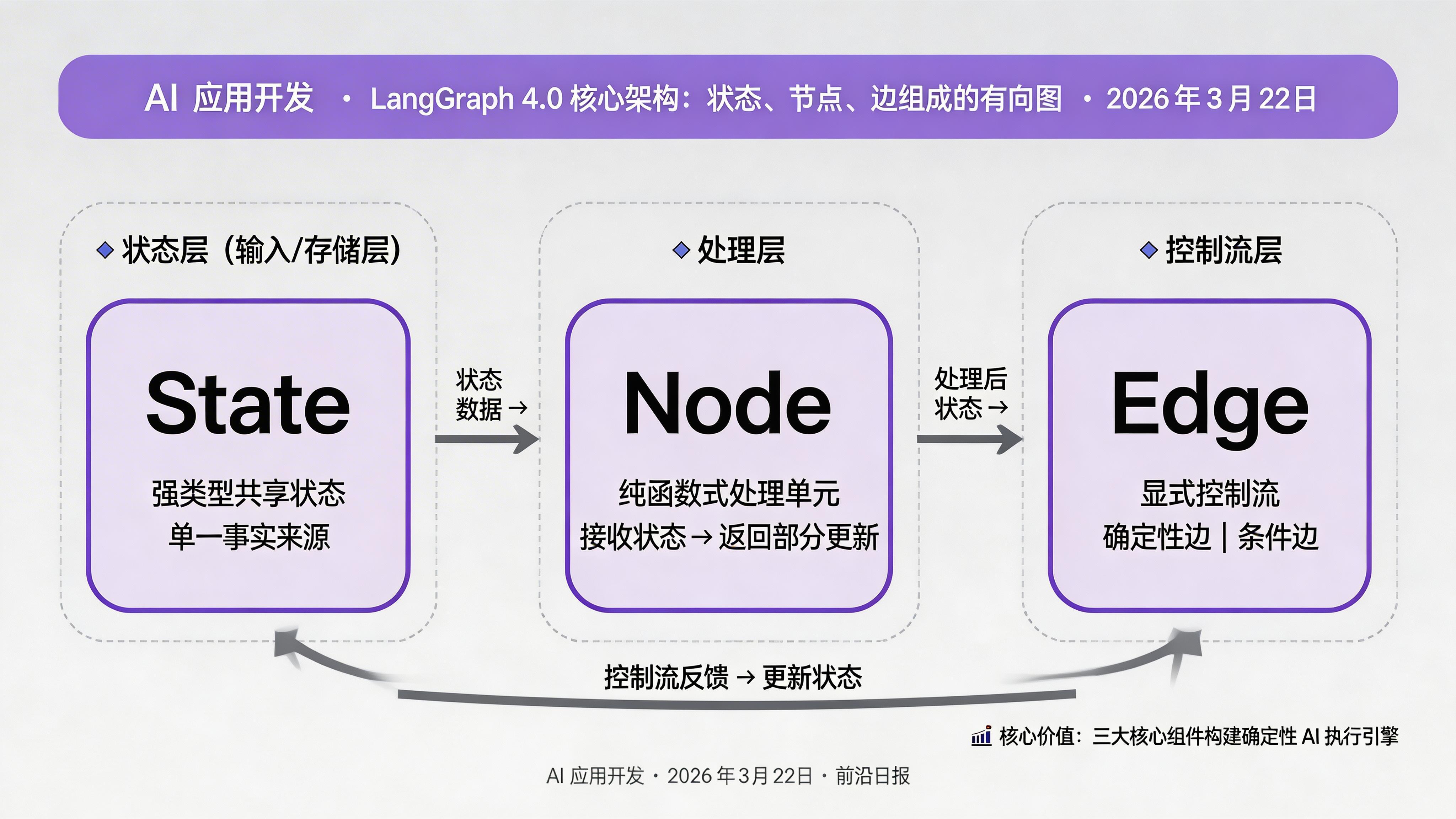
核心概念:把 AI 流程变成状态机
LangGraph 4.0 的设计哲学可以概括为一句话:控制流显式化,状态持久化,节点模块化。理解以下三个核心概念是掌握 LangGraph 的关键:
1. State(状态):单一事实来源
State 是一个强类型的对象(通常使用 TypedDict 定义),它贯穿整个图的执行过程。所有节点读取的输入和输出的修改都基于这个共享状态。这种设计带来了两大好处:
- 可追溯性:每一步的输入输出都被记录,可以完整回放执行历史
- 类型安全:编译时就能发现状态字段的拼写错误或类型不匹配
2. Node(节点):纯函数式的处理单元
每个节点是一个 Python 函数,它接收当前状态,返回部分状态更新(partial update)。节点应该是纯函数:相同的输入产生相同的输出,没有副作用。这使得测试、调试、回滚都变得简单。
3. Edge(边):显式的控制流定义
边定义了节点之间的执行顺序。LangGraph 支持两种边:
- 确定性边:A 节点执行完后一定执行 B 节点
- 条件边:根据节点返回的值,动态决定下一个节点(类似 switch-case)
这种显式控制流让 AI 流程不再是大模型的"黑盒决策",而是可预测、可调试的状态机。
准备工作:环境搭建与依赖
首先创建虚拟环境并安装依赖:
python -m venv venv
source venv/bin/activate # Windows 使用 venv\Scripts\activate
# 安装核心依赖
pip install langgraph langchain-openai langchain-community
# 可选:LangSmith 用于生产监控
pip install langsmith接着配置环境变量:
# ~/.bashrc 或.env 文件
export OPENAI_API_KEY="sk-..."
export LANGCHAIN_API_KEY="你的 LangSmith API Key" # 可选
export LANGCHAIN_TRACING_V2="true" # 启用 LangSmith 追踪
实战步骤:构建多 Agent 内容审核系统
本教程将通过一个实际案例——多 Agent 内容审核系统——来演示 LangGraph 4.0 的完整使用流程。该系统包含三个 Agent:
- 初审 Agent:快速扫描内容,标记疑似违规
- 复审 Agent:对疑似违规内容进行深度分析
- 决策 Agent:根据复审结果,决定最终处理方式(通过/警告/删除)
我们还将在关键环节加入人类审核介入,确保在边界案例中不会误判。
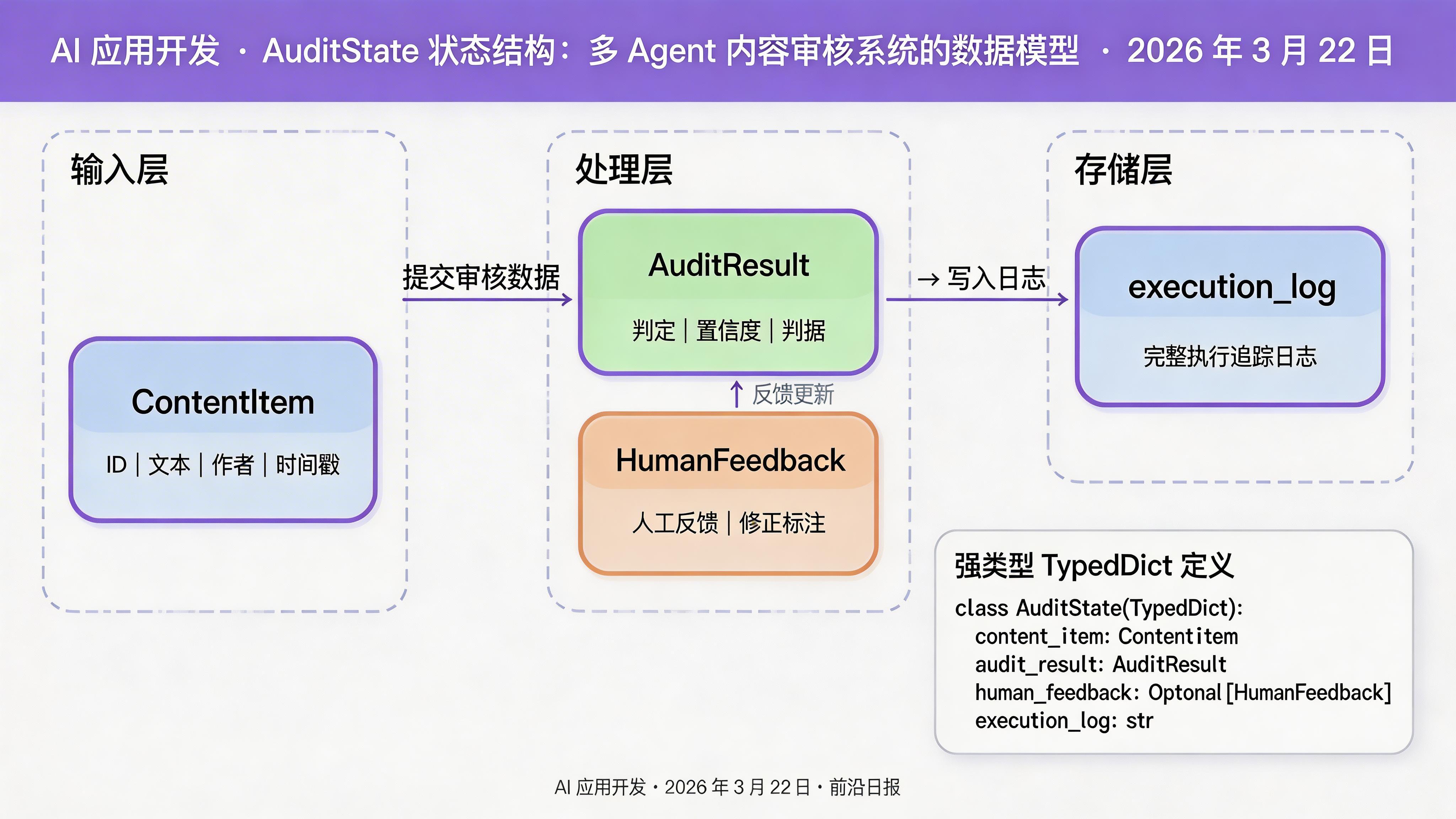
步骤 1:定义状态结构(State Schema)
状态是整个系统的单一事实来源。我们需要明确定义所有需要跨节点共享的数据:
from typing import TypedDict, List, Optional, Literal
from datetime import datetime
class ContentItem(TypedDict):
"""待审核的内容项"""
id: str
text: str
author: str
timestamp: datetime
class AuditResult(TypedDict):
"""审核结果"""
verdict: Literal["pass", "warning", "reject"] # 通过/警告/拒绝
confidence: float # 置信度 0-1
reasons: List[str] # 判据列表
class HumanFeedback(TypedDict):
"""人类审核反馈"""
reviewed_by: str
decision: Literal["approve", "override", "escalate"]
comment: str
# 主状态定义
class AuditState(TypedDict):
"""审核系统共享状态"""
content: ContentItem # 待审核内容
initial_flags: List[str] # 初审标记的违规类型
preliminary_result: Optional[AuditResult] # 初审结果
deep_analysis: Optional[AuditResult] # 复审结果
human_feedback: Optional[HumanFeedback] # 人类审核反馈
final_decision: Optional[Literal["pass", "warning", "reject"]] # 最终决策
execution_log: List[str] # 执行日志使用 TypedDict 的好处在于:如果你的 IDE 支持类型检查,可以在编码阶段就发现状态字段访问错误。此外,LangGraph 4.0 会在运行时验证状态更新是否符合 schema。
步骤 2:实现节点函数(Nodes)
每个节点都是一个独立的处理单元。我们按照职责单一原则,将系统拆分为以下节点:
2.1 初审节点:快速标记违规类型
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
def initial_screen(state: AuditState) -> dict:
"""
初审节点:快速扫描内容,标记可能的违规类型
返回部分状态更新(只更新 initial_flags 字段)
"""
prompt = f"""你是一个内容审核助手。请快速扫描以下内容,识别可能的违规类型。
违规类型包括:仇恨言论、暴力威胁、色情内容、垃圾广告、虚假信息、隐私泄露。
内容:
{state['content']['text']}
请以 JSON 数组形式返回识别到的违规类型(如果没有明显违规,返回空数组):
违规类型列表:"""
response = llm.invoke([
SystemMessage(content="你是一名专业的内容审核 AI,只输出 JSON 格式。"),
HumanMessage(content=prompt)
])
import json
try:
flags = json.loads(response.content)
except:
flags = []
# 记录执行日志
log_entry = f"[初审] 识别到 {len(flags)} 个违规类型:{', '.join(flags)}"
return {
"initial_flags": flags,
"execution_log": state.get("execution_log", []) + [log_entry]
}步骤 3:实现复审节点与决策节点
2.2 条件路由:决定是否需要复审
并非所有内容都需要深度复审。我们定义一个简单的路由逻辑:如果初审没有发现违规,直接通过;否则进入复审流程。
def route_after_screen(state: AuditState) -> Literal["deep_analyze", "skip_to_decision"]:
"""条件路由函数:根据初审结果决定下一步"""
if len(state.get("initial_flags", [])) == 0:
return "skip_to_decision" # 无违规,直接通过
else:
return "deep_analyze" # 有违规标记,进入深度分析2.3 复审节点:深度分析违规程度
def deep_analyze(state: AuditState) -> dict:
"""复审节点:对疑似违规进行深度分析,给出置信度和判据"""
flags = state['initial_flags']
prompt = f"""你对以下内容进行深度审核分析:
【待审核内容】
{state['content']['text']}
【初审标记的违规类型】
{', '.join(flags)}
请逐项分析每个违规类型:
1. 是否存在该违规(是/否)
2. 置信度(0-1 之间的小数)
3. 具体判据(引用原文并说明理由)
请以 JSON 格式返回:
{{
"verdict": "pass/warning/reject",
"confidence": 0.95,
"reasons": ["理由 1", "理由 2", ...]
}}"""
response = llm.invoke([
SystemMessage(content="你是一名资深内容审核专家,输出严格的 JSON 格式。"),
HumanMessage(content=prompt)
])
import json
try:
result = json.loads(response.content)
audit_result = {
"verdict": result.get("verdict", "pass"),
"confidence": result.get("confidence", 0.5),
"reasons": result.get("reasons", [])
}
except Exception as e:
audit_result = {
"verdict": "warning",
"confidence": 0.3,
"reasons": [f"解析失败:{str(e)}"]
}
log_entry = f"[复审] 判定:{audit_result['verdict']}, 置信度:{audit_result['confidence']}"
return {
"deep_analysis": audit_result,
"execution_log": state.get("execution_log", []) + [log_entry]
}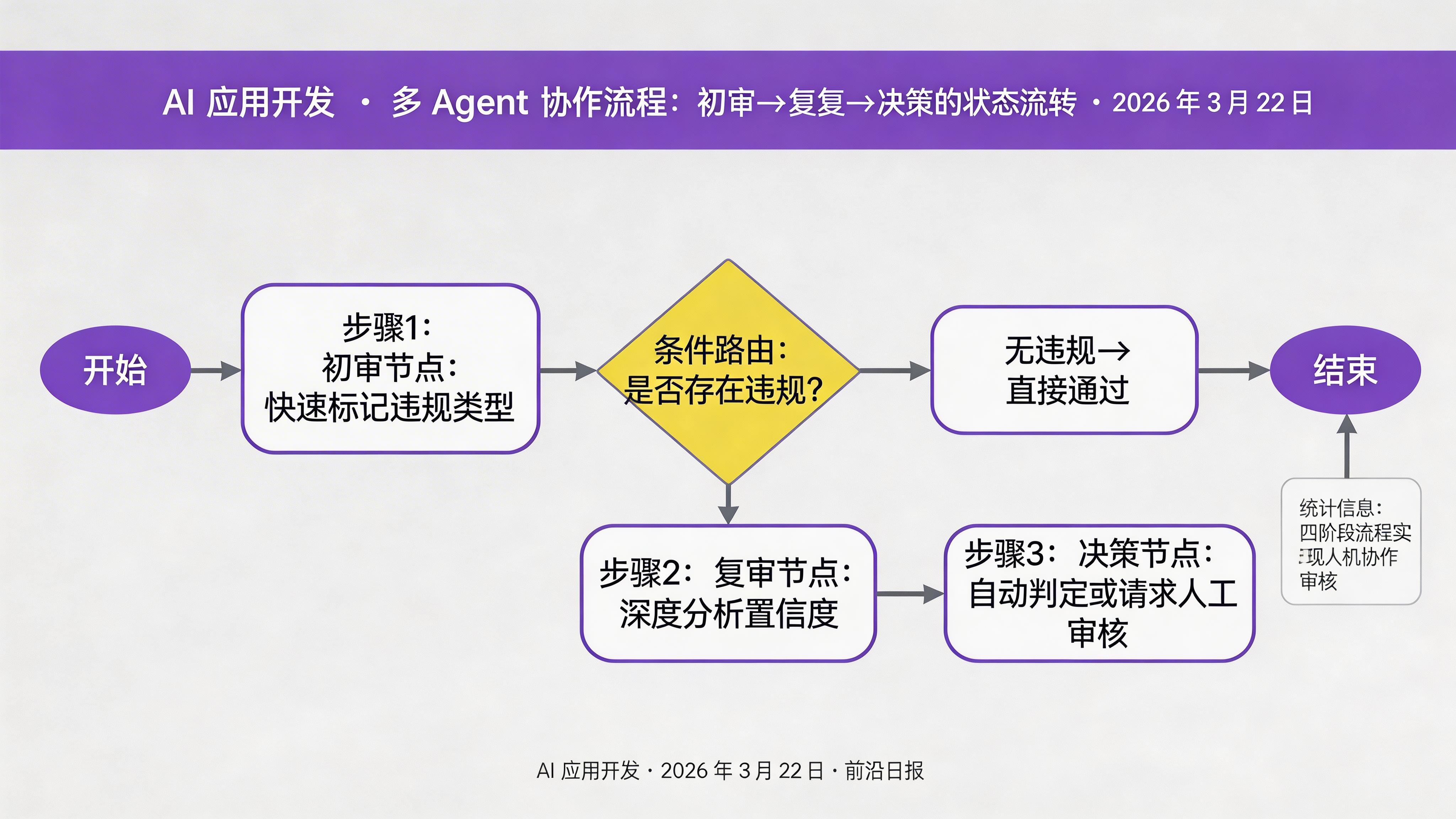
步骤 4:加入人类审核介入
LangGraph 4.0 支持在任意节点前后设置"中断点"(interrupt),用于人类审核。这在医疗、法律、金融等高风险场景中至关重要。
2.4 决策节点:综合判断并请求人类确认(如需要)
def make_decision(state: AuditState) -> dict:
"""
决策节点:根据复审结果决定最终处理方式
如果置信度低于阈值,请求人类审核
"""
# 如果有复审结果,使用它;否则使用初审的默认通过
if state.get("deep_analysis"):
analysis = state["deep_analysis"]
else:
analysis = {"verdict": "pass", "confidence": 1.0, "reasons": ["初审无违规"]}
# 置信度阈值:低于 0.7 需要人工审核
HUMAN_REVIEW_THRESHOLD = 0.7
if analysis["confidence"] < HUMAN_REVIEW_THRESHOLD:
log_entry = f"[决策] 置信度 {analysis['confidence']:.2f} < {HUMAN_REVIEW_THRESHOLD},请求人工审核"
# 设置中断,等待人类反馈
# 实际应用中这里会触发外部审核系统
return {
"execution_log": state.get("execution_log", []) + [log_entry],
# 不设置 final_decision,等待人类反馈后再决定
}
else:
final_verdict = analysis["verdict"]
log_entry = f"[决策] 自动判定:{final_verdict}"
return {
"final_decision": final_verdict,
"execution_log": state.get("execution_log", []) + [log_entry]
}💡 LangGraph 4.0 的中断机制:在生产环境中,你可以使用graph.interrupt()在关键点暂停执行,将状态保存到数据库,然后触发外部审核流程(如发送邮件通知、Slack 消息等)。审核完成后,使用graph.resume()从断点继续执行。
步骤 5:构建状态图并编译执行
所有节点准备就绪后,我们使用 StateGraph 将它们组装成完整的执行流程:
from langgraph.graph import StateGraph, END
# 创建状态图
builder = StateGraph(AuditState)
# 添加节点
builder.add_node("initial_screen", initial_screen)
builder.add_node("deep_analyze", deep_analyze)
builder.add_node("make_decision", make_decision)
# 设置入口点
builder.set_entry_point("initial_screen")
# 添加条件边:初审后决定下一步
builder.add_conditional_edges(
source="initial_screen",
condition=route_after_screen,
mapping={
"deep_analyze": "deep_analyze",
"skip_to_decision": "make_decision"
}
)
# 复审后进入决策
builder.add_edge("deep_analyze", "make_decision")
# 决策后结束
builder.add_edge("make_decision", END)
# 编译成可执行应用
app = builder.compile()现在可以调用这个应用了:
# 测试用例:一段正常内容
test_content = {
"content": {
"id": "post-001",
"text": "今天天气真好,去公园散步很开心!",
"author": "user123",
"timestamp": datetime.now()
},
"initial_flags": [],
"preliminary_result": None,
"deep_analysis": None,
"human_feedback": None,
"final_decision": None,
"execution_log": []
}
# 执行
result = app.invoke(test_content)
print(f"最终决策:{result['final_decision']}")
print(f"执行日志:{result['execution_log']}")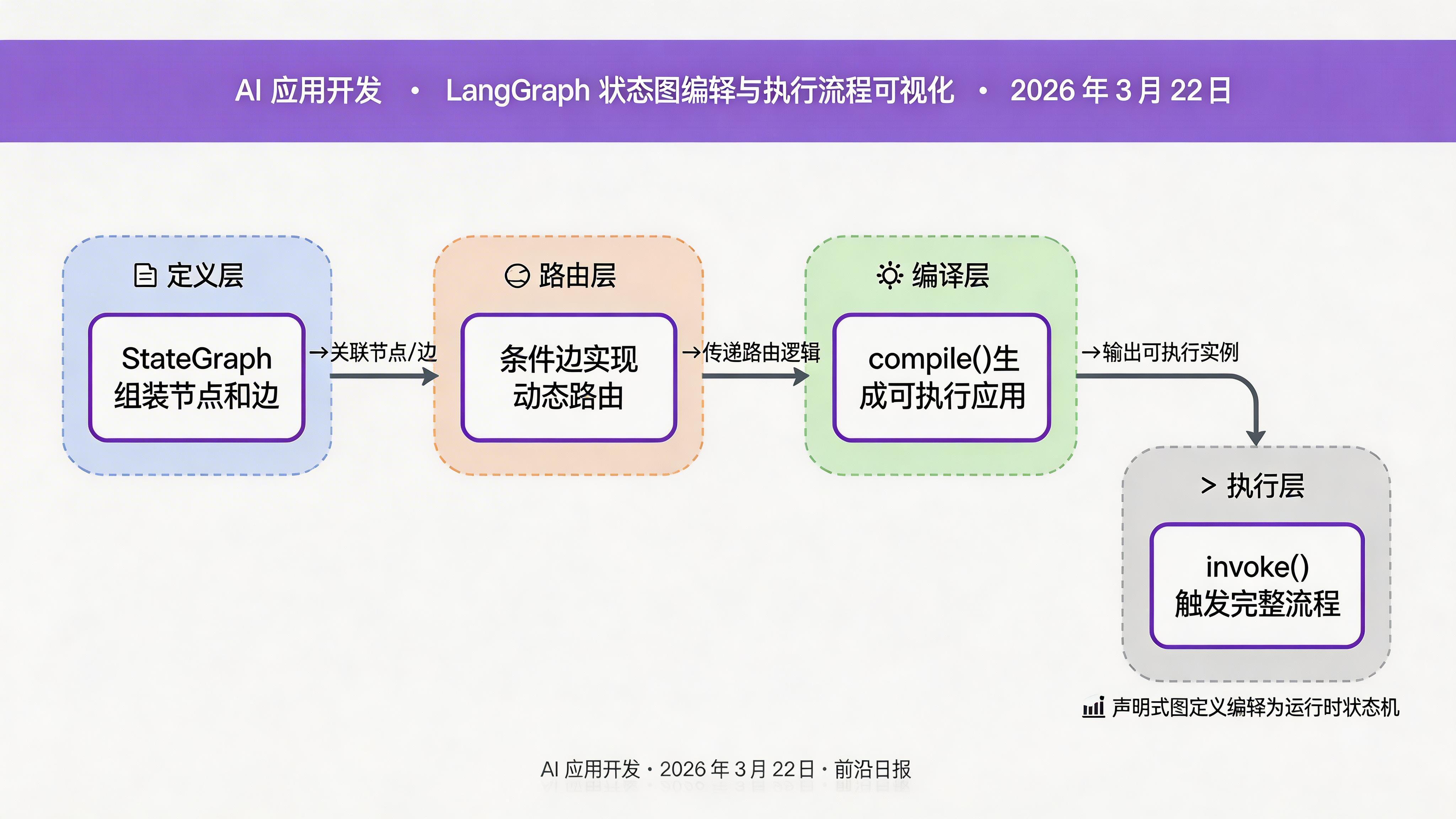
步骤 6:状态持久化与断点续跑
LangGraph 4.0 内置了检查点(checkpoint)机制,可以将状态持久化到数据库中。这样即使进程崩溃或需要人工审核,也能从中断点恢复。
from langgraph.checkpoint.sqlite import SqliteSaver
# 配置 SQLite 持久化
checkpointer = SqliteSaver.from_conn_string(":memory:") # 生产环境用文件路径
# 使用检查点器重新编译
app = builder.compile(checkpointer=checkpointer)
# 现在每次执行都会自动保存状态
config = {"configurable": {"thread_id": "audit-session-001"}}
# 首次执行
result = app.invoke(test_content, config=config)
# 如果需要从断点恢复(例如人类审核完成后)
# app.invoke(None, config=config) # 传入 None 表示从上次状态继续💡 生产环境建议:使用 PostgreSQL 或 Redis 作为持久化后端,配置定期备份策略。对于需要审计的场景(如金融、医疗),检查点日志应保留至少 7 年。
常见问题与解决方案
LANGCHAIN_TRACING_V2=true环境变量,所有执行步骤都会自动记录到 LangSmith 控制台。你可以看到每个节点的输入输出、执行时间、token 消耗等详细信息。retry_count: int字段,每次重试时递增,达到上限后返回错误。
进阶技巧:使用 LaunchDarkly 动态配置多 Agent 系统
2026 年的最佳实践是使用功能标志平台(如 LaunchDarkly)来动态控制 Agent 行为,无需重新部署即可调整策略。以下是一个示例:
from launchdarkly_server_sdk import LDClient
# 初始化 LaunchDarkly
ld_client = LDClient("your-sdk-key")
user = {"key": "audit-system"}
def get_confidence_threshold() -> float:
"""从 LaunchDarkly 动态获取置信度阈值"""
return ld_client.variation("human-review-threshold", user, 0.7)
# 在决策节点中使用
def make_decision_dynamic(state: AuditState) -> dict:
threshold = get_confidence_threshold()
# 使用动态阈值进行判断
...这样,运营团队可以在控制台上调整阈值,观察不同设置下的审核效果,而无需等待开发团队发布新版本。
总结:LangGraph 4.0 的核心价值
- 显式控制流:用图结构替代隐式提示词链,让 AI 流程可预测、可调试
- 强类型状态:单一事实来源,支持持久化、回滚、审计
- 模块化节点:每个节点独立测试、独立部署、独立监控
- 人类介入:在关键点设置中断,实现人机协作
- 生产就绪:与 LangSmith、LaunchDarkly 等工具集成,支持动态配置和可观测性
2026 年的 AI 应用开发不再是"提示词工程",而是状态机设计 + 节点逻辑 + 控制流编排的系统工程。掌握 LangGraph 4.0,就是掌握了构建生产级多 Agent 系统的钥匙。