为什么需要多模态 Agent?
想象一个场景:你需要定期从后台导出用户数据、整理成报表、再上传到共享文档。传统自动化脚本只能处理结构化 API,一旦涉及网页操作就束手无策。
多模态 Agent(Multimodal Agent)的出现改变了这一局面。它结合了视觉理解与工具调用能力,能够像人类一样"看"屏幕、"操作"浏览器,完成端到端的自动化任务。
本教程将带你使用 Claude Code 的 Computer Use API,从零构建一个能自主操作浏览器的 AI 助手。
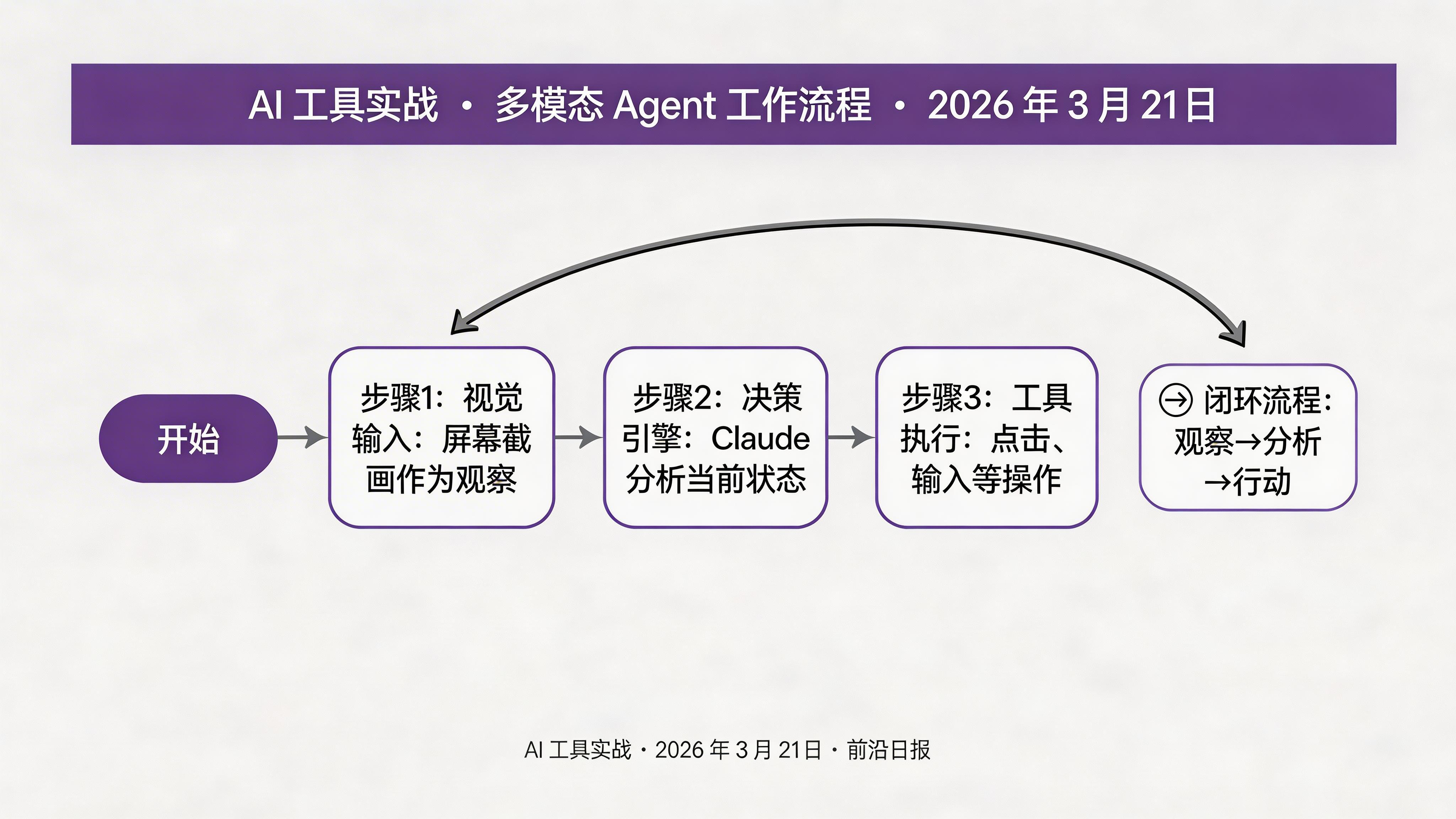
核心概念:Computer Use API 如何工作
Claude 的 Computer Use API 基于三个核心组件:
整个流程形成一个闭环:观察 → 分析 → 行动 → 再观察,直到任务完成。
准备工作:环境与依赖
开始之前,确保你的开发环境满足以下要求:
安装依赖
# 创建项目目录
mkdir claude-computer-use && cd claude-computer-use
# 初始化 Python 虚拟环境
python3 -m venv .venv
source .venv/bin/activate
# 安装核心依赖
pip install anthropic playwright selenium
playwright install chromium实战步骤:构建浏览器自动化 Agent
我们将构建一个完整的多模态 Agent,能够自动登录指定网站并抓取数据。以下是详细的 7 个步骤:
配置 API 客户端
首先创建与 Claude API 的连接:
import os
from anthropic import Anthropic
# 初始化客户端
client = Anthropic(api_key=os.environ["ANTHROPIC_API_KEY"])
# 验证连接
print(f"Connected: {client.models.list().models[0].id}")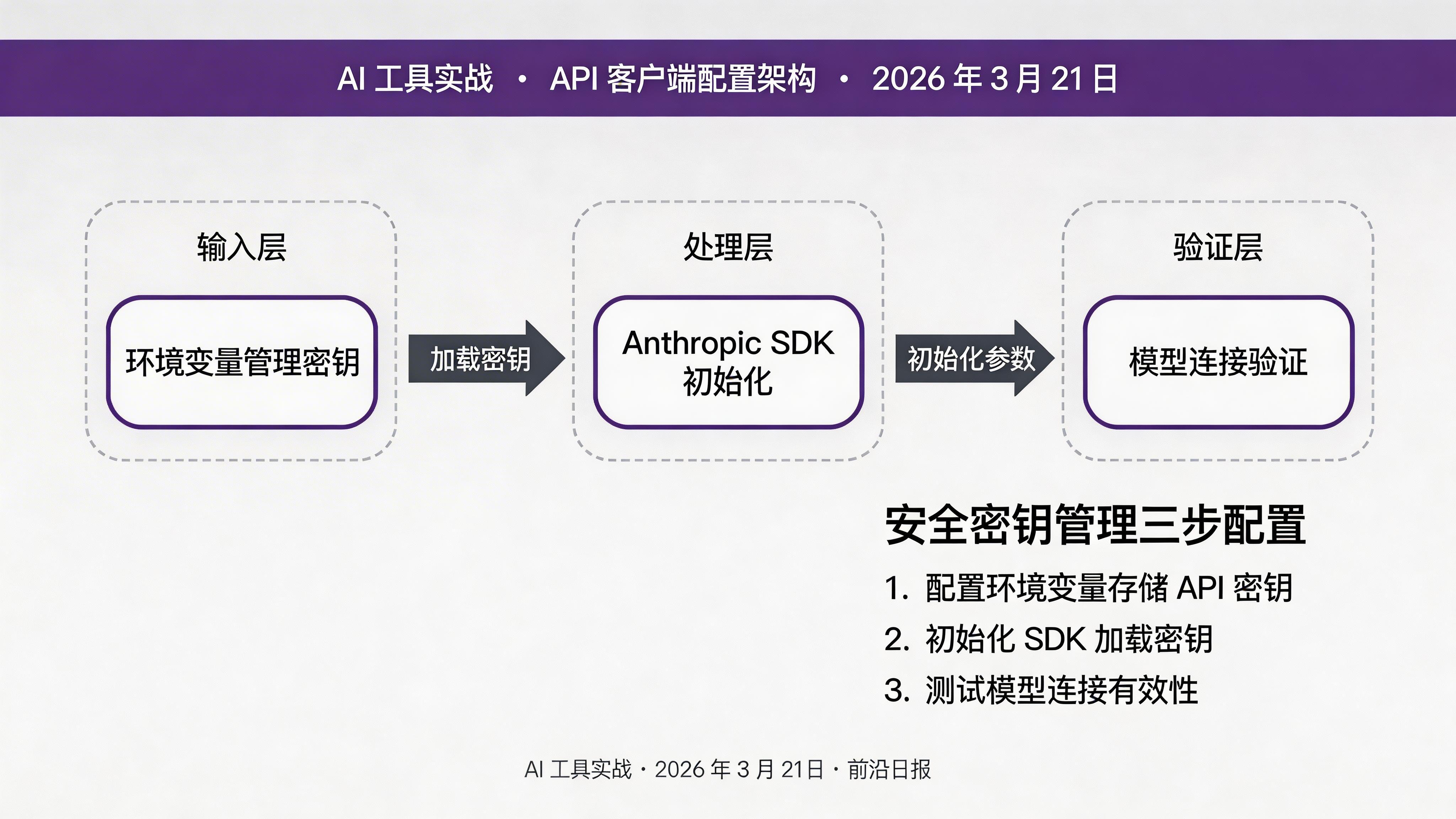
设置 Playwright 浏览器
启动无头浏览器并配置截图能力:
from playwright.sync_api import sync_playwright
import base64
import time
class BrowserController:
def __init__(self):
self.playwright = sync_playwright().start()
self.browser = self.playwright.chromium.launch(headless=True)
self.page = self.browser.new_page()
def navigate(self, url):
self.page.goto(url)
time.sleep(2) # 等待页面加载
def capture_screenshot(self) -> str:
"""截取当前屏幕并返回 base64 编码"""
screenshot = self.page.screenshot()
return base64.standard_b64encode(screenshot).decode('utf-8')
def click(self, selector: str):
self.page.click(selector)
time.sleep(1)
def type_text(self, selector: str, text: str):
self.page.fill(selector, text)
def close(self):
self.browser.close()
self.playwright.stop()定义工具函数
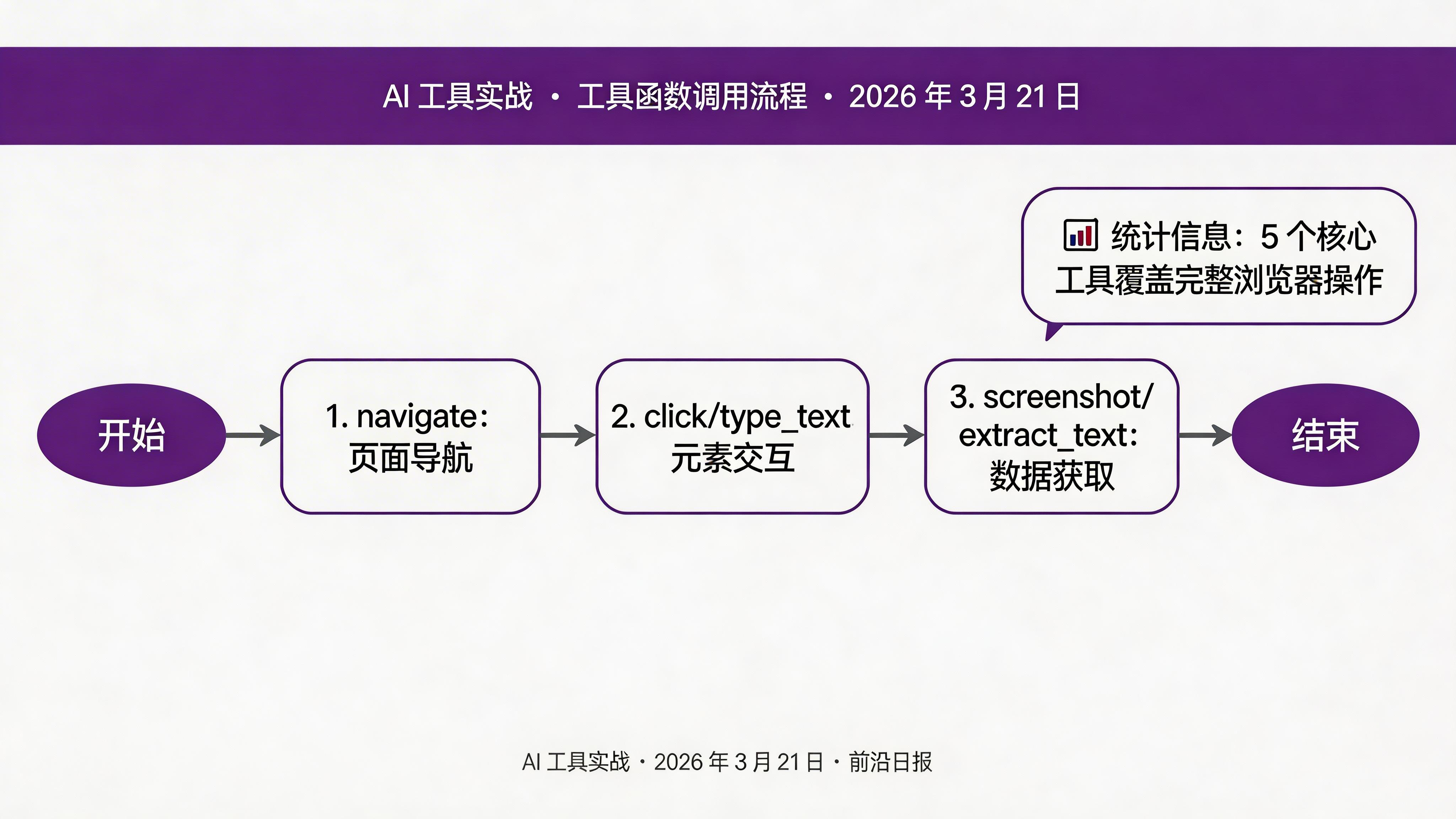
将浏览器操作封装为 Claude 可调用的工具:
tools = [
{
"name": "navigate",
"description": "导航到指定 URL",
"input_schema": {
"type": "object",
"properties": {
"url": {"type": "string", "description": "目标网址 URL"}
},
"required": ["url"]
}
},
{
"name": "click",
"description": "点击页面元素",
"input_schema": {
"type": "object",
"properties": {
"selector": {"type": "string", "description": "CSS 选择器"}
},
"required": ["selector"]
}
},
{
"name": "type_text",
"description": "在输入框中填写文本",
"input_schema": {
"type": "object",
"properties": {
"selector": {"type": "string", "description": "CSS 选择器"},
"text": {"type": "string", "description": "要输入的文本"}
},
"required": ["selector", "text"]
}
},
{
"name": "screenshot",
"description": "截取当前页面屏幕",
"input_schema": {"type": "object", "properties": {}}
},
{
"name": "extract_text",
"description": "提取页面中指定元素的文本",
"input_schema": {
"type": "object",
"properties": {
"selector": {"type": "string", "description": "CSS 选择器"}
},
"required": ["selector"]
}
}
]
构建工具执行器
将工具定义与实际浏览器操作关联:
class ToolExecutor:
def __init__(self, browser: BrowserController):
self.browser = browser
def execute(self, name: str, inputs: dict) -> str:
if name == "navigate":
self.browser.navigate(inputs["url"])
return f"已导航到 {inputs['url']}"
elif name == "click":
self.browser.click(inputs["selector"])
return f"已点击 {inputs['selector']}"
elif name == "type_text":
self.browser.type_text(inputs["selector"], inputs["text"])
return f"已输入文本到 {inputs['selector']}"
elif name == "screenshot":
img_data = self.browser.capture_screenshot()
return f"截图完成 (base64 长度:{len(img_data)})"
elif name == "extract_text":
text = self.browser.page.text_content(inputs["selector"])
return f"提取文本:{text}"
return f"未知工具:{name}"实现 Agent 循环
核心逻辑:发送截图给 Claude → 接收工具调用 → 执行 → 重复直到完成:
import json
class ComputerUseAgent:
def __init__(self, browser: BrowserController, executor: ToolExecutor):
self.browser = browser
self.executor = executor
self.client = client
self.conversation_history = []
def run(self, goal: str, max_turns: int = 10):
"""执行任务直到完成或达到最大回合数"""
system_prompt = f"""你是一个自动化助手,能够操作浏览器完成网页任务。
当前任务目标:{goal}
请分析屏幕截图,决定下一步操作。可用工具:
- navigate(url): 导航到网址
- click(selector): 点击元素
- type_text(selector, text): 输入文本
- screenshot(): 截屏
- extract_text(selector): 提取文本
每次只调用一个工具,用 JSON 格式回复:
{{"tool": "工具名", "inputs": {{参数}}}}当任务完成时回复:{{"done": true, "result": "结果描述"}}
for turn in range(max_turns):
# 1. 截取当前屏幕
screenshot = self.browser.capture_screenshot()
# 2. 发送截图给 Claude
response = self.client.messages.create(
model="claude-sonnet-4-6-20260620",
max_tokens=1024,
system=system_prompt,
messages=[
*self.conversation_history,
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/png",
"data": screenshot
}
},
{"type": "text", "text": "请分析当前屏幕并决定下一步操作"}
]
}
],
tools=tools
)
# 3. 解析响应并执行工具
tool_call = response.content[0]
if tool_call.type == "tool_use":
result = self.executor.execute(
tool_call.name,
tool_call.input
)
self.conversation_history.append({
"role": "assistant",
"content": response.content
})
self.conversation_history.append({
"role": "user",
"content": f"工具执行结果:{result}"
})
# 检查是否完成
if "done" in result.lower():
break
return self.conversation_history[-1]["content"]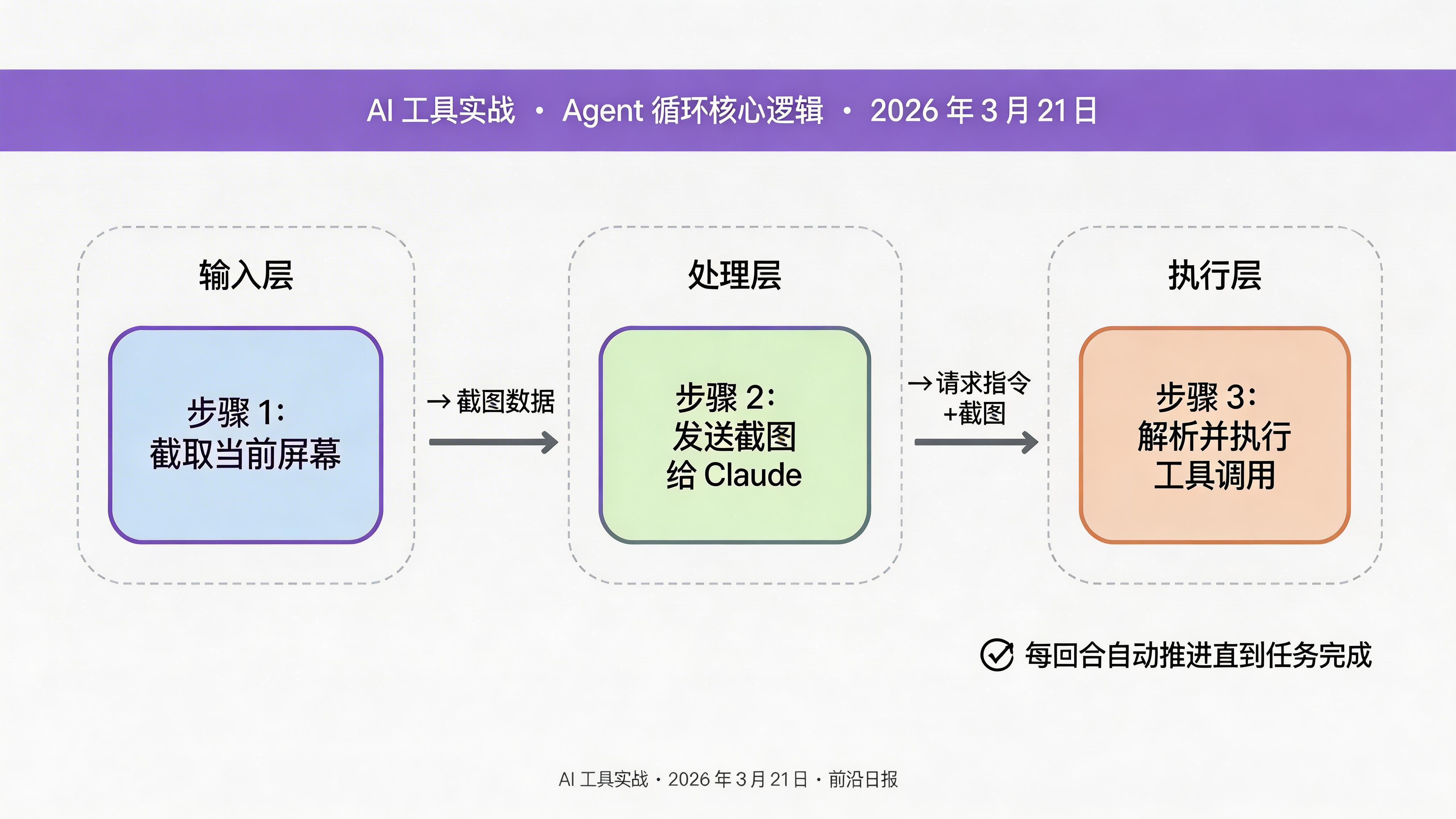
实战演练:自动登录并抓取数据
完整示例:登录 GitHub 并获取仓库列表:
# 主程序
if __name__ == "__main__":
# 初始化组件
browser = BrowserController()
executor = ToolExecutor(browser)
agent = ComputerUseAgent(browser, executor)
# 定义任务
goal = """
1. 导航到 github.com
2. 点击右上角 Sign in
3. 输入用户名和密码(从环境变量读取)
4. 登录后导航到用户的 Repositories 页面
5. 提取前 5 个仓库的名称和 star 数
6. 返回 JSON 格式结果
"""
# 执行任务
result = agent.run(goal, max_turns=15)
print(f"任务完成:{result}")
# 清理资源
browser.close()GITHUB_USERNAME 和 GITHUB_PASSWORD 存储敏感信息。
调试与日志
添加可视化调试能力:
import logging
from pathlib import Path
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
# 截图保存调试
class DebugBrowserController(BrowserController):
def __init__(self, debug_dir: str = "./debug"):
super().__init__()
self.debug_dir = Path(debug_dir)
self.debug_dir.mkdir(exist_ok=True)
self.turn_count = 0
def capture_screenshot(self) -> str:
self.turn_count += 1
screenshot = super().capture_screenshot()
# 保存调试截图
debug_path = self.debug_dir / f"turn_{self.turn_count:03d}.png"
with open(debug_path, "wb") as f:
f.write(base64.b64decode(screenshot))
logger.info(f"截图已保存:{debug_path}")
return screenshot
常见问题与解决方案
Agent 陷入循环无法完成任务怎么办?
设置合理的 max_turns 限制(建议 10-15 回合),并在系统提示词中强调"每次操作应使任务向前推进"。还可以添加超时机制,检测重复操作。
截图太大导致 API 超时可以吗?
可以缩放截图尺寸(建议 1024x768),或者使用滚动截图截取可见区域。另一个方案是使用 DOM 提取代替截图,仅在选择器定位失败时才用视觉辅助。
如何处理动态加载的内容?
在 navigate() 和 click() 后添加智能等待:使用 Playwright 的 wait_for_selector() 或检测网络空闲状态,而不是固定 sleep()。
能否同时操作多个标签页?
可以。扩展 BrowserController 添加 new_tab() 和 switch_tab(index) 方法,并将当前 tab 索引作为工具参数。注意 Claude 每次只能"看到"一个 tab 的截图。
进阶技巧与最佳实践
- 选择器优先策略:优先使用 CSS 选择器定位,截图仅作为后备方案,减少 token 消耗
- 操作原子化:每个工具调用只做一件事(如只点击或只输入),便于 Claude 精确控制
- 错误恢复:在工具执行器中添加重试逻辑,遇到
ElementNotFound时先截图再分析 - 会话记忆:使用
conversation_history保存上下文,避免重复说明当前状态 - 并行验证:关键操作(如登录)执行后立即截图验证,确认成功后再继续
总结
通过本教程,你完成了从零构建多模态 Agent 的完整流程:
- ✓ 理解 Computer Use API 的核心原理与工作流程
- ✓ 使用 Playwright 搭建浏览器自动化环境
- ✓ 封装工具函数并实现 Agent 循环
- ✓ 完成登录抓取的实战案例
- ✓ 掌握调试技巧与常见问题排查方法
多模态 Agent 是 2026 年自动化领域的重要趋势,掌握了这项技术,你就能构建真正"看懂"屏幕、"操作"界面的智能助手,突破传统 RPA 的边界。